 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Layout Analysis, Character Detection and Recognition for Historical Document Digitization
Paper and Code

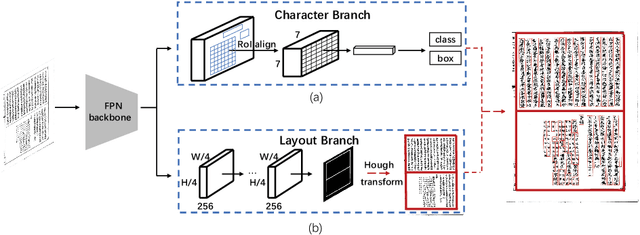
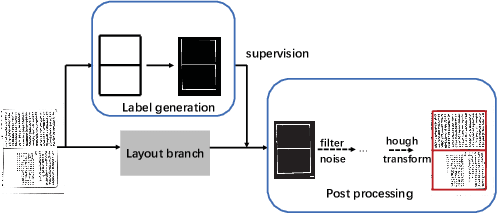
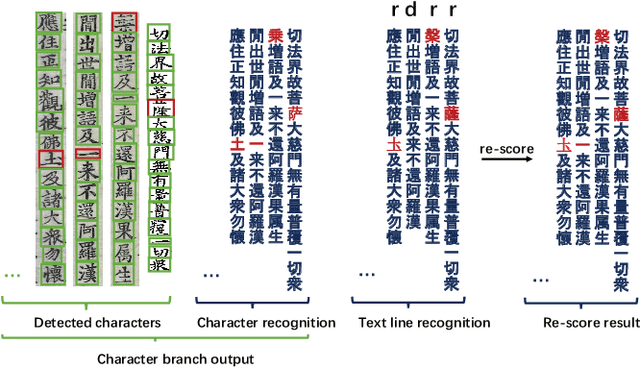
In this paper, we propose an end-to-end trainable framework for restoring historical documents content that follows the correct reading order. In this framework, two branches named character branch and layout branch are added behind the feature extraction network. The character branch localizes individual characters in a document image and recognizes them simultaneously. Then we adopt a post-processing method to group them into text lines. The layout branch based on fully convolutional network outputs a binary mask. We then use Hough transform for line detection on the binary mask and combine character results with the layout information to restore document content. These two branches can be trained in parallel and are easy to train. Furthermore, we propose a re-score mechanism to minimize recognition error. Experiment results on the extended Chinese historical document MTHv2 dataset demonstrate the effectiveness of the proposed framework.