 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniTabBench: Mapping the Empirical Frontiers of GBDTs, Neural Networks, and Foundation Models for Tabular Data at Scale
Apr 08, 2026While traditional tree-based ensemble methods have long dominated tabular tasks, deep neural networks and emerging foundation models have challenged this primacy, yet no consensus exists on a universally superior paradigm. Existing benchmarks typically contain fewer than 100 datasets, raising concerns about evaluation sufficiency and potential selection biases. To address these limitations, we introduce OmniTabBench, the largest tabular benchmark to date, comprising 3030 datasets spanning diverse tasks that are comprehensively collected from diverse sources and categorized by industry using large language models. We conduct an unprecedented large-scale empirical evaluation of state-of-the-art models from all model families on OmniTabBench, confirming the absence of a dominant winner. Furthermore, through a decoupled metafeature analysis, which examines individual properties such as dataset size, feature types, feature and target skewness/kurtosis, we elucidate conditions favoring specific model categories, providing clearer, more actionable guidance than prior compound-metric studies.
Improving Table Structure Recognition with Visual-Alignment Sequential Coordinate Modeling
Mar 20, 2023


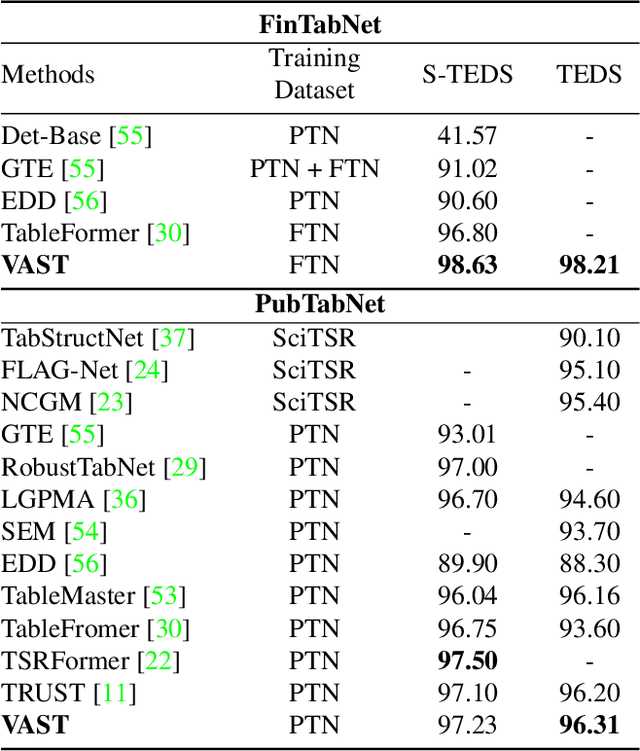
Table structure recognition aims to extract the logical and physical structure of unstructured table images into a machine-readable format. The latest end-to-end image-to-text approaches simultaneously predict the two structures by two decoders, where the prediction of the physical structure (the bounding boxes of the cells) is based on the representation of the logical structure. However, the previous methods struggle with imprecise bounding boxes as the logical representation lacks local visual information. To address this issue, we propose an end-to-end sequential modeling framework for table structure recognition called VAST. It contains a novel coordinate sequence decoder triggered by the representation of the non-empty cell from the logical structure decoder. In the coordinate sequence decoder, we model the bounding box coordinates as a language sequence, where the left, top, right and bottom coordinates are decoded sequentially to leverage the inter-coordinate dependency. Furthermore, we propose an auxiliary visual-alignment loss to enforce the logical representation of the non-empty cells to contain more local visual details, which helps produce better cell bounding boxes. Extensive experiments demonstrate that our proposed method can achieve state-of-the-art results in both logical and physical structure recognition. The ablation study also validates that the proposed coordinate sequence decoder and the visual-alignment loss are the keys to the success of our method.
Recognition of Handwritten Chinese Text by Segmentation: A Segment-annotation-free Approach
Jul 29, 2022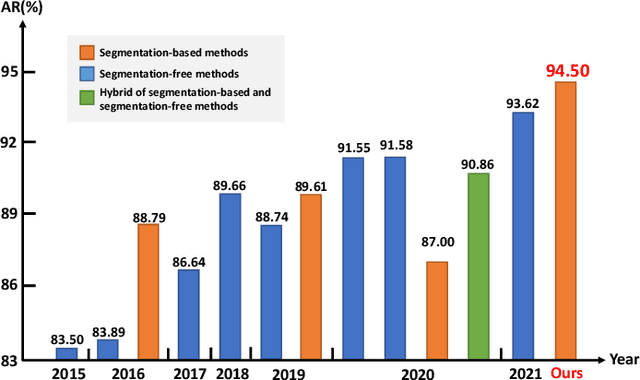
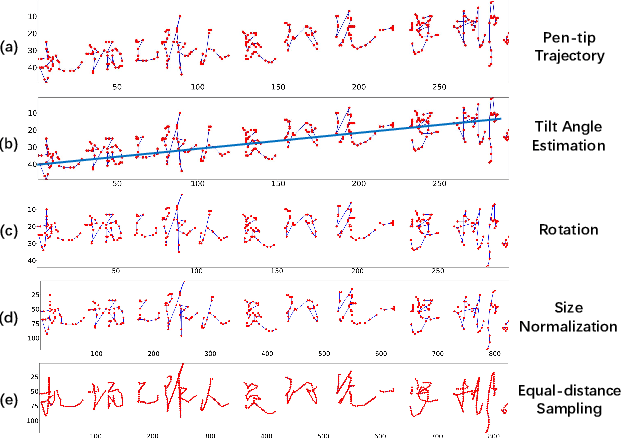


Online and offline handwritten Chinese text recognition (HTCR) has been studied for decades. Early methods adopted oversegmentation-based strategies but suffered from low speed, insufficient accuracy, and high cost of character segmentation annotations. Recently, segmentation-free methods based on connectionist temporal classification (CTC) and attention mechanism, have dominated the field of HCTR. However, people actually read text character by character, especially for ideograms such as Chinese. This raises the question: are segmentation-free strategies really the best solution to HCTR? To explore this issue, we propose a new segmentation-based method for recognizing handwritten Chinese text that is implemented using a simple yet efficient fully convolutional network. A novel weakly supervised learning method is proposed to enable the network to be trained using only transcript annotations; thus, the expensive character segmentation annotations required by previous segmentation-based methods can be avoided. Owing to the lack of context modeling in fully convolutional networks, we propose a contextual regularization method to integrate contextual information into the network during the training stage, which can further improve the recognition performance. Extensive experiments conducted on four widely used benchmarks, namely CASIA-HWDB, CASIA-OLHWDB, ICDAR2013, and SCUT-HCCDoc, show that our method significantly surpasses existing methods on both online and offline HCTR, and exhibits a considerably higher inference speed than CTC/attention-based approaches.
Reading and Writing: Discriminative and Generative Modeling for Self-Supervised Text Recognition
Jul 01, 2022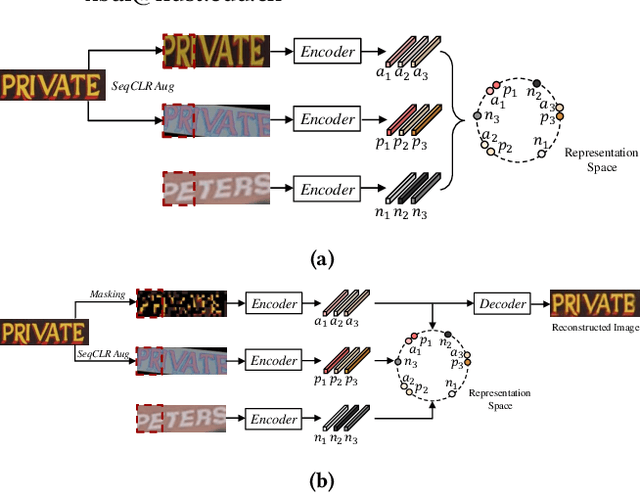
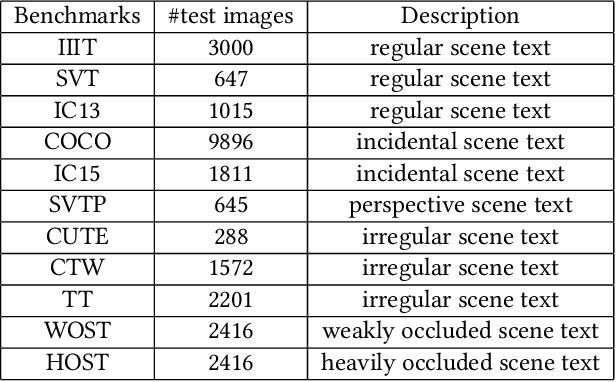
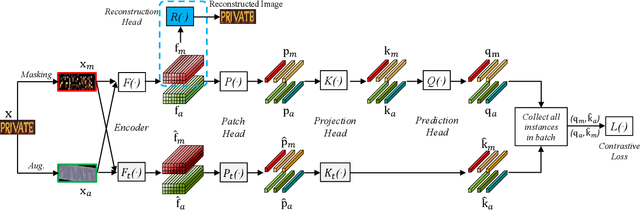
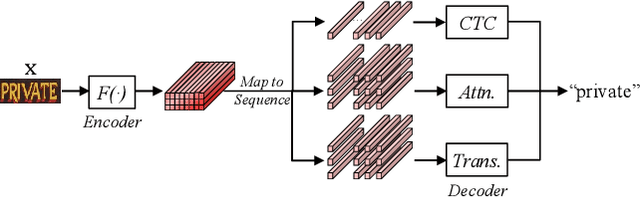
Existing text recognition methods usually need large-scale training data. Most of them rely on synthetic training data due to the lack of annotated real images. However, there is a domain gap between the synthetic data and real data, which limits the performance of the text recognition models. Recent self-supervised text recognition methods attempted to utilize unlabeled real images by introducing contrastive learning, which mainly learns the discrimination of the text images. Inspired by the observation that humans learn to recognize the texts through both reading and writing, we propose to learn discrimination and generation by integrating contrastive learning and masked image modeling in our self-supervised method. The contrastive learning branch is adopted to learn the discrimination of text images, which imitates the reading behavior of humans. Meanwhile, masked image modeling is firstly introduced for text recognition to learn the context generation of the text images, which is similar to the writing behavior. The experimental results show that our method outperforms previous self-supervised text recognition methods by 10.2%-20.2% on irregular scene text recognition datasets. Moreover, our proposed text recognizer exceeds previous state-of-the-art text recognition methods by averagely 5.3% on 11 benchmarks, with similar model size. We also demonstrate that our pre-trained model can be easily applied to other text-related tasks with obvious performance gain.
Look Closer to Supervise Better: One-Shot Font Generation via Component-Based Discriminator
Apr 30, 2022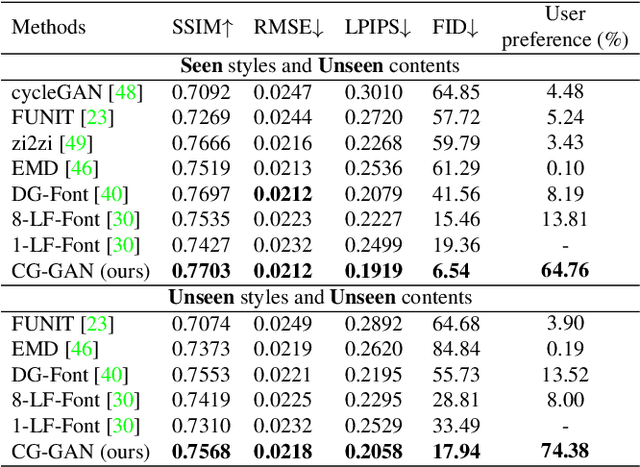
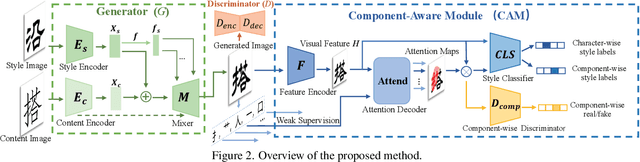


Automatic font generation remains a challenging research issue due to the large amounts of characters with complicated structures. Typically, only a few samples can serve as the style/content reference (termed few-shot learning), which further increases the difficulty to preserve local style patterns or detailed glyph structures. We investigate the drawbacks of previous studies and find that a coarse-grained discriminator is insufficient for supervising a font generator. To this end, we propose a novel Component-Aware Module (CAM), which supervises the generator to decouple content and style at a more fine-grained level, \textit{i.e.}, the component level. Different from previous studies struggling to increase the complexity of generators, we aim to perform more effective supervision for a relatively simple generator to achieve its full potential, which is a brand new perspective for font generation. The whole framework achieves remarkable results by coupling component-level supervision with adversarial learning, hence we call it Component-Guided GAN, shortly CG-GAN. Extensive experiments show that our approach outperforms state-of-the-art one-shot font generation methods. Furthermore, it can be applied to handwritten word synthesis and scene text image editing, suggesting the generalization of our approach.
SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text Recognition
Mar 19, 2022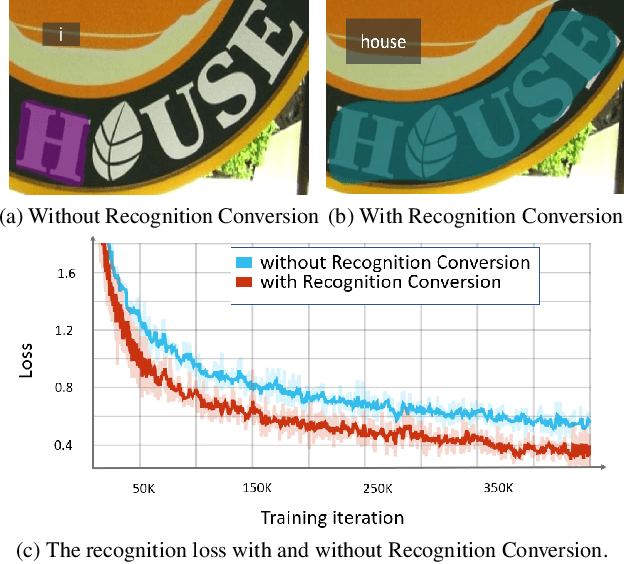
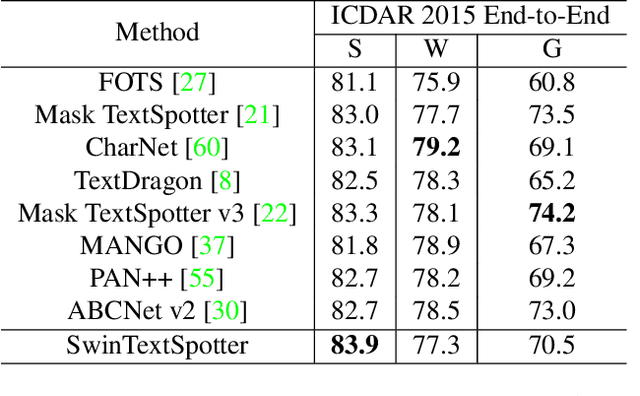
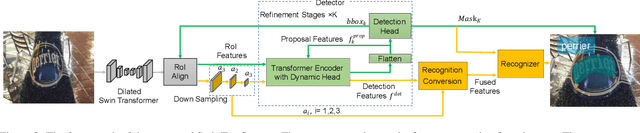
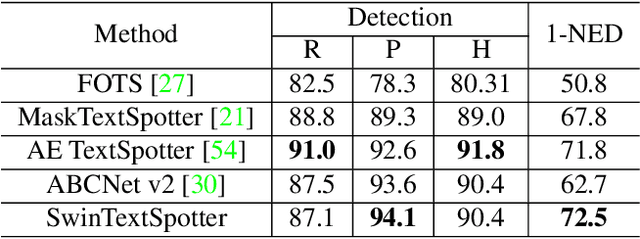
End-to-end scene text spotting has attracted great attention in recent years due to the success of excavating the intrinsic synergy of the scene text detection and recognition. However, recent state-of-the-art methods usually incorporate detection and recognition simply by sharing the backbone, which does not directly take advantage of the feature interaction between the two tasks. In this paper, we propose a new end-to-end scene text spotting framework termed SwinTextSpotter. Using a transformer encoder with dynamic head as the detector, we unify the two tasks with a novel Recognition Conversion mechanism to explicitly guide text localization through recognition loss. The straightforward design results in a concise framework that requires neither additional rectification module nor character-level annotation for the arbitrarily-shaped text. Qualitative and quantitative experiments on multi-oriented datasets RoIC13 and ICDAR 2015, arbitrarily-shaped datasets Total-Text and CTW1500, and multi-lingual datasets ReCTS (Chinese) and VinText (Vietnamese) demonstrate SwinTextSpotter significantly outperforms existing methods. Code is available at https://github.com/mxin262/SwinTextSpotter.
SPTS: Single-Point Text Spotting
Dec 15, 2021
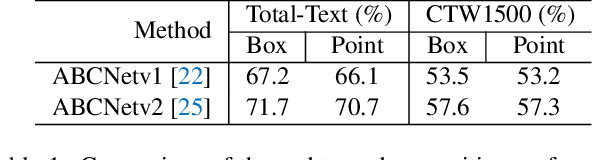

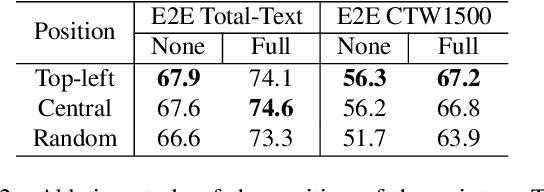
Almost all scene text spotting (detection and recognition) methods rely on costly box annotation (e.g., text-line box, word-level box, and character-level box). For the first time, we demonstrate that training scene text spotting models can be achieved with an extremely low-cost annotation of a single-point for each instance. We propose an end-to-end scene text spotting method that tackles scene text spotting as a sequence prediction task, like language modeling. Given an image as input, we formulate the desired detection and recognition results as a sequence of discrete tokens and use an auto-regressive transformer to predict the sequence. We achieve promising results on several horizontal, multi-oriented, and arbitrarily shaped scene text benchmarks. Most significantly, we show that the performance is not very sensitive to the positions of the point annotation, meaning that it can be much easier to be annotated and automatically generated than the bounding box that requires precise positions. We believe that such a pioneer attempt indicates a significant opportunity for scene text spotting applications of a much larger scale than previously possible.
Video Text Tracking With a Spatio-Temporal Complementary Model
Nov 09, 2021
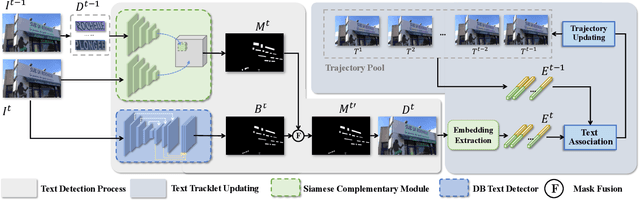
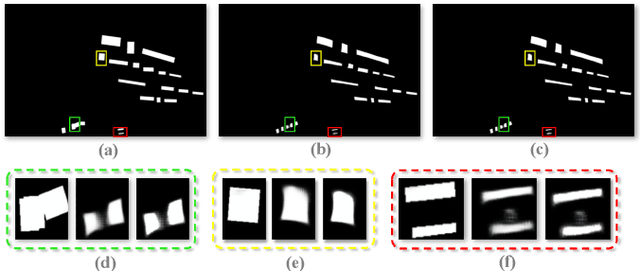

Text tracking is to track multiple texts in a video,and construct a trajectory for each text. Existing methodstackle this task by utilizing the tracking-by-detection frame-work, i.e., detecting the text instances in each frame andassociating the corresponding text instances in consecutiveframes. We argue that the tracking accuracy of this paradigmis severely limited in more complex scenarios, e.g., owing tomotion blur, etc., the missed detection of text instances causesthe break of the text trajectory. In addition, different textinstances with similar appearance are easily confused, leadingto the incorrect association of the text instances. To this end,a novel spatio-temporal complementary text tracking model isproposed in this paper. We leverage a Siamese ComplementaryModule to fully exploit the continuity characteristic of the textinstances in the temporal dimension, which effectively alleviatesthe missed detection of the text instances, and hence ensuresthe completeness of each text trajectory. We further integratethe semantic cues and the visual cues of the text instance intoa unified representation via a text similarity learning network,which supplies a high discriminative power in the presence oftext instances with similar appearance, and thus avoids the mis-association between them. Our method achieves state-of-the-art performance on several public benchmarks. The source codeis available at https://github.com/lsabrinax/VideoTextSCM.
* 12 pages
From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network
Aug 22, 2021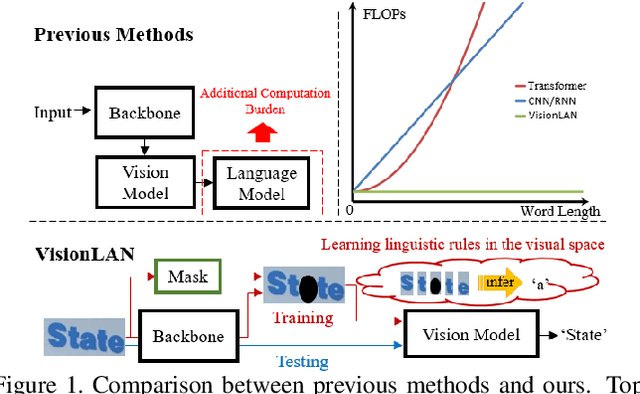
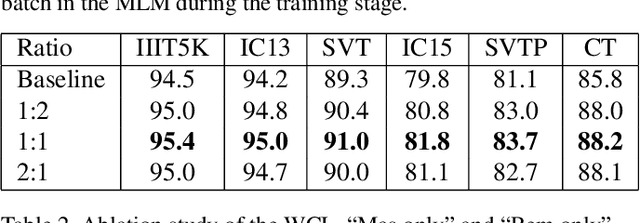
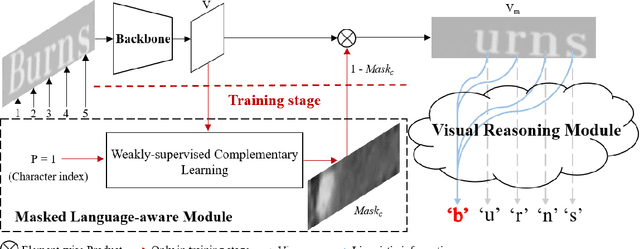
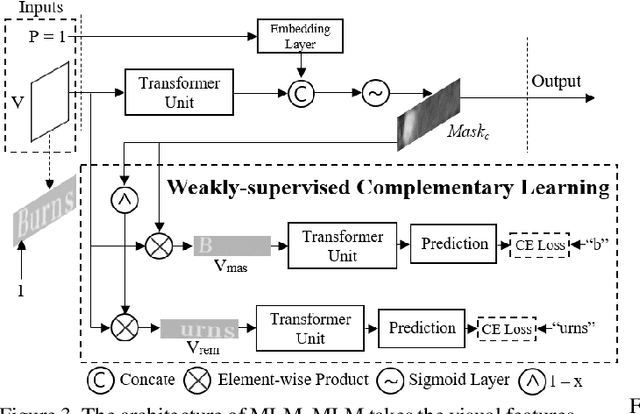
In this paper, we abandon the dominant complex language model and rethink the linguistic learning process in the scene text recognition. Different from previous methods considering the visual and linguistic information in two separate structures, we propose a Visual Language Modeling Network (VisionLAN), which views the visual and linguistic information as a union by directly enduing the vision model with language capability. Specially, we introduce the text recognition of character-wise occluded feature maps in the training stage. Such operation guides the vision model to use not only the visual texture of characters, but also the linguistic information in visual context for recognition when the visual cues are confused (e.g. occlusion, noise, etc.). As the linguistic information is acquired along with visual features without the need of extra language model, VisionLAN significantly improves the speed by 39% and adaptively considers the linguistic information to enhance the visual features for accurate recognition. Furthermore, an Occlusion Scene Text (OST) dataset is proposed to evaluate the performance on the case of missing character-wise visual cues. The state of-the-art results on several benchmarks prove our effectiveness. Code and dataset are available at https://github.com/wangyuxin87/VisionLAN.
Scene Text Retrieval via Joint Text Detection and Similarity Learning
Apr 04, 2021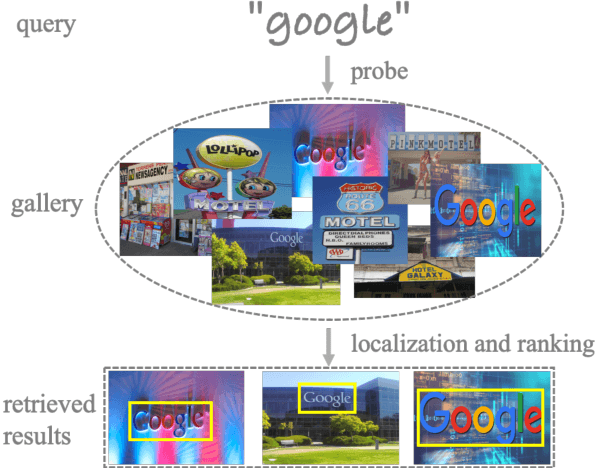

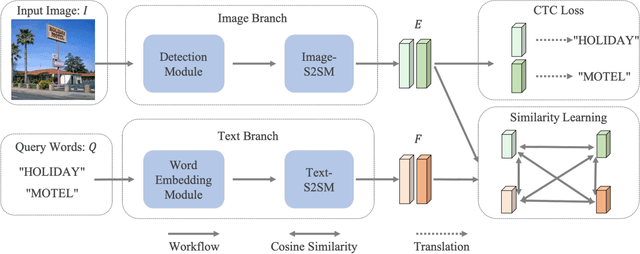
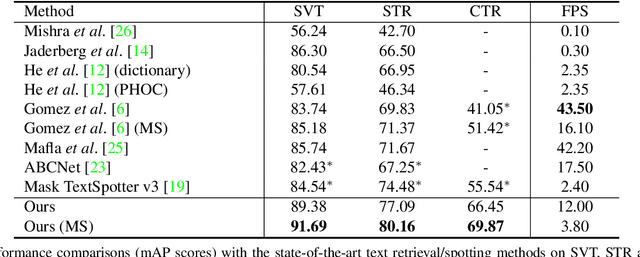
Scene text retrieval aims to localize and search all text instances from an image gallery, which are the same or similar to a given query text. Such a task is usually realized by matching a query text to the recognized words, outputted by an end-to-end scene text spotter. In this paper, we address this problem by directly learning a cross-modal similarity between a query text and each text instance from natural images. Specifically, we establish an end-to-end trainable network, jointly optimizing the procedures of scene text detection and cross-modal similarity learning. In this way, scene text retrieval can be simply performed by ranking the detected text instances with the learned similarity. Experiments on three benchmark datasets demonstrate our method consistently outperforms the state-of-the-art scene text spotting/retrieval approaches. In particular, the proposed framework of joint detection and similarity learning achieves significantly better performance than separated methods. Code is available at: https://github.com/lanfeng4659/STR-TDSL.