 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPTS: Single-Point Text Spotting
Paper and Code

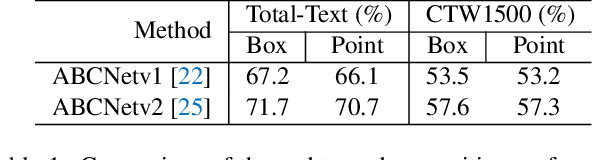

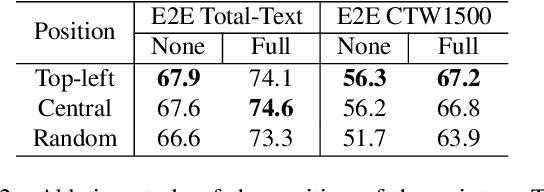
Almost all scene text spotting (detection and recognition) methods rely on costly box annotation (e.g., text-line box, word-level box, and character-level box). For the first time, we demonstrate that training scene text spotting models can be achieved with an extremely low-cost annotation of a single-point for each instance. We propose an end-to-end scene text spotting method that tackles scene text spotting as a sequence prediction task, like language modeling. Given an image as input, we formulate the desired detection and recognition results as a sequence of discrete tokens and use an auto-regressive transformer to predict the sequence. We achieve promising results on several horizontal, multi-oriented, and arbitrarily shaped scene text benchmarks. Most significantly, we show that the performance is not very sensitive to the positions of the point annotation, meaning that it can be much easier to be annotated and automatically generated than the bounding box that requires precise positions. We believe that such a pioneer attempt indicates a significant opportunity for scene text spotting applications of a much larger scale than previously possible.