 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCR-Reasoning Benchmark: Unveiling the True Capabilities of MLLMs in Complex Text-Rich Image Reasoning
May 22, 2025Recent advancements in multimodal slow-thinking systems have demonstrated remarkable performance across diverse visual reasoning tasks. However, their capabilities in text-rich image reasoning tasks remain understudied due to the lack of a systematic benchmark. To address this gap, we propose OCR-Reasoning, a comprehensive benchmark designed to systematically assess Multimodal Large Language Models on text-rich image reasoning tasks. The benchmark comprises 1,069 human-annotated examples spanning 6 core reasoning abilities and 18 practical reasoning tasks in text-rich visual scenarios. Furthermore, unlike other text-rich image understanding benchmarks that only annotate the final answers, OCR-Reasoning also annotates the reasoning process simultaneously. With the annotated reasoning process and the final answers, OCR-Reasoning evaluates not only the final answers generated by models but also their reasoning processes, enabling a holistic analysis of their problem-solving abilities. Leveraging this benchmark, we conducted a comprehensive evaluation of state-of-the-art MLLMs. Our results demonstrate the limitations of existing methodologies. Notably, even state-of-the-art MLLMs exhibit substantial difficulties, with none achieving accuracy surpassing 50\% across OCR-Reasoning, indicating that the challenges of text-rich image reasoning are an urgent issue to be addressed. The benchmark and evaluation scripts are available at https://github.com/SCUT-DLVCLab/OCR-Reasoning.
OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning
Dec 31, 2024



Scoring the Optical Character Recognition (OCR) capabilities of Large Multimodal Models (LMMs) has witnessed growing interest recently. Existing benchmarks have highlighted the impressive performance of LMMs in text recognition; however, their abilities on certain challenging tasks, such as text localization, handwritten content extraction, and logical reasoning, remain underexplored. To bridge this gap, we introduce OCRBench v2, a large-scale bilingual text-centric benchmark with currently the most comprehensive set of tasks (4x more tasks than the previous multi-scene benchmark OCRBench), the widest coverage of scenarios (31 diverse scenarios including street scene, receipt, formula, diagram, and so on), and thorough evaluation metrics, with a total of 10,000 human-verified question-answering pairs and a high proportion of difficult samples. After carefully benchmarking state-of-the-art LMMs on OCRBench v2, we find that 20 out of 22 LMMs score below 50 (100 in total) and suffer from five-type limitations, including less frequently encountered text recognition, fine-grained perception, layout perception, complex element parsing, and logical reasoning. The benchmark and evaluation scripts are available at https://github.com/Yuliang-liu/MultimodalOCR.
Creating a Microstructure Latent Space with Rich Material Information for Multiphase Alloy Design
Sep 04, 2024The intricate microstructure serves as the cornerstone for the composition/processing-structure-property (CPSP) connection in multiphase alloys. Traditional alloy design methods often overlook microstructural details, which diminishes the reliability and effectiveness of the outcomes. This study introduces an improved alloy design algorithm that integrates authentic microstructural information to establish precise CPSP relationships. The approach utilizes a deep-learning framework based on a variational autoencoder to map real microstructural data to a latent space, enabling the prediction of composition, processing steps, and material properties from the latent space vector. By integrating this deep learning model with a specific sampling strategy in the latent space, a novel, microstructure-centered algorithm for multiphase alloy design is developed. This algorithm is demonstrated through the design of a unified dual-phase steel, and the results are assessed at three performance levels. Moreover, an exploration into the latent vector space of the model highlights its seamless interpolation ability and its rich material information content. Notably, the current configuration of the latent space is particularly advantageous for alloy design, offering an exhaustive representation of microstructure, composition, processing, and property variations essential for multiphase alloys.
Mini-Monkey: Multi-Scale Adaptive Cropping for Multimodal Large Language Models
Aug 09, 2024



Recently, there has been significant interest in enhancing the capability of multimodal large language models (MLLMs) to process high-resolution images. Most existing methods focus on adopting a cropping strategy to improve the ability of multimodal large language models to understand image details. However, this cropping operation inevitably causes the segmentation of objects and connected areas, which impairs the MLLM's ability to recognize small or irregularly shaped objects or text. This issue is particularly evident in lightweight MLLMs. Addressing this issue, we propose Mini-Monkey, a lightweight MLLM that incorporates a plug-and-play method called multi-scale adaptive crop strategy (MSAC). Mini-Monkey adaptively generates multi-scale representations, allowing it to select non-segmented objects from various scales. To mitigate the computational overhead introduced by MSAC, we propose a Scale Compression Mechanism (SCM), which effectively compresses image tokens. Mini-Monkey achieves state-of-the-art performance among 2B-parameter MLLMs. It not only demonstrates leading performance on a variety of general multimodal understanding tasks but also shows consistent improvements in document understanding capabilities. On the OCRBench, Mini-Monkey achieves a score of 802, outperforming 8B-parameter state-of-the-art model InternVL2-8B. Besides, our model and training strategy are very efficient, which can be trained with only eight RTX 3090. The code is available at https://github.com/Yuliang-Liu/Monkey.
Mini-Monkey: Alleviate the Sawtooth Effect by Multi-Scale Adaptive Cropping
Aug 04, 2024Recently, there has been significant interest in enhancing the capability of multimodal large language models (MLLMs) to process high-resolution images. Most existing methods focus on adopting a cropping strategy to improve the ability of multimodal large language models to understand image details. However, this cropping operation inevitably causes the segmentation of objects and connected areas, which impairs the MLLM's ability to recognize small or irregularly shaped objects or text. This issue is particularly evident in lightweight MLLMs. Addressing this issue, we propose Mini-Monkey, a lightweight MLLM that incorporates a plug-and-play method called multi-scale adaptive crop strategy (MSAC). Mini-Monkey adaptively generates multi-scale representations, allowing it to select non-segmented objects from various scales. To mitigate the computational overhead introduced by MSAC, we propose a Scale Compression Mechanism (SCM), which effectively compresses image tokens. Mini-Monkey achieves state-of-the-art performance among 2B-parameter MLLMs. It not only demonstrates leading performance on a variety of general multimodal understanding tasks but also shows consistent improvements in document understanding capabilities. On the OCRBench, Mini-Monkey achieves a score of 802, outperforming 8B-parameter state-of-the-art model InternVL2-8B. Besides, our model and training strategy are very efficient, which can be trained with only eight RTX 3090. The code is available at https://github.com/Yuliang-Liu/Monkey.
VimTS: A Unified Video and Image Text Spotter for Enhancing the Cross-domain Generalization
Apr 30, 2024



Text spotting, a task involving the extraction of textual information from image or video sequences, faces challenges in cross-domain adaption, such as image-to-image and image-to-video generalization. In this paper, we introduce a new method, termed VimTS, which enhances the generalization ability of the model by achieving better synergy among different tasks. Typically, we propose a Prompt Queries Generation Module and a Tasks-aware Adapter to effectively convert the original single-task model into a multi-task model suitable for both image and video scenarios with minimal additional parameters. The Prompt Queries Generation Module facilitates explicit interaction between different tasks, while the Tasks-aware Adapter helps the model dynamically learn suitable features for each task. Additionally, to further enable the model to learn temporal information at a lower cost, we propose a synthetic video text dataset (VTD-368k) by leveraging the Content Deformation Fields (CoDeF) algorithm. Notably, our method outperforms the state-of-the-art method by an average of 2.6% in six cross-domain benchmarks such as TT-to-IC15, CTW1500-to-TT, and TT-to-CTW1500. For video-level cross-domain adaption, our method even surpasses the previous end-to-end video spotting method in ICDAR2015 video and DSText v2 by an average of 5.5% on the MOTA metric, using only image-level data. We further demonstrate that existing Large Multimodal Models exhibit limitations in generating cross-domain scene text spotting, in contrast to our VimTS model which requires significantly fewer parameters and data. The code and datasets will be made available at the https://VimTextSpotter.github.io.
Bridging the Gap Between End-to-End and Two-Step Text Spotting
Apr 06, 2024Modularity plays a crucial role in the development and maintenance of complex systems. While end-to-end text spotting efficiently mitigates the issues of error accumulation and sub-optimal performance seen in traditional two-step methodologies, the two-step methods continue to be favored in many competitions and practical settings due to their superior modularity. In this paper, we introduce Bridging Text Spotting, a novel approach that resolves the error accumulation and suboptimal performance issues in two-step methods while retaining modularity. To achieve this, we adopt a well-trained detector and recognizer that are developed and trained independently and then lock their parameters to preserve their already acquired capabilities. Subsequently, we introduce a Bridge that connects the locked detector and recognizer through a zero-initialized neural network. This zero-initialized neural network, initialized with weights set to zeros, ensures seamless integration of the large receptive field features in detection into the locked recognizer. Furthermore, since the fixed detector and recognizer cannot naturally acquire end-to-end optimization features, we adopt the Adapter to facilitate their efficient learning of these features. We demonstrate the effectiveness of the proposed method through extensive experiments: Connecting the latest detector and recognizer through Bridging Text Spotting, we achieved an accuracy of 83.3% on Total-Text, 69.8% on CTW1500, and 89.5% on ICDAR 2015. The code is available at https://github.com/mxin262/Bridging-Text-Spotting.
SwinTextSpotter v2: Towards Better Synergy for Scene Text Spotting
Jan 15, 2024End-to-end scene text spotting, which aims to read the text in natural images, has garnered significant attention in recent years. However, recent state-of-the-art methods usually incorporate detection and recognition simply by sharing the backbone, which does not directly take advantage of the feature interaction between the two tasks. In this paper, we propose a new end-to-end scene text spotting framework termed SwinTextSpotter v2, which seeks to find a better synergy between text detection and recognition. Specifically, we enhance the relationship between two tasks using novel Recognition Conversion and Recognition Alignment modules. Recognition Conversion explicitly guides text localization through recognition loss, while Recognition Alignment dynamically extracts text features for recognition through the detection predictions. This simple yet effective design results in a concise framework that requires neither an additional rectification module nor character-level annotations for the arbitrarily-shaped text. Furthermore, the parameters of the detector are greatly reduced without performance degradation by introducing a Box Selection Schedule. Qualitative and quantitative experiments demonstrate that SwinTextSpotter v2 achieved state-of-the-art performance on various multilingual (English, Chinese, and Vietnamese) benchmarks. The code will be available at \href{https://github.com/mxin262/SwinTextSpotterv2}{SwinTextSpotter v2}.
Progressive Evolution from Single-Point to Polygon for Scene Text
Dec 21, 2023The advancement of text shape representations towards compactness has enhanced text detection and spotting performance, but at a high annotation cost. Current models use single-point annotations to reduce costs, yet they lack sufficient localization information for downstream applications. To overcome this limitation, we introduce Point2Polygon, which can efficiently transform single-points into compact polygons. Our method uses a coarse-to-fine process, starting with creating and selecting anchor points based on recognition confidence, then vertically and horizontally refining the polygon using recognition information to optimize its shape. We demonstrate the accuracy of the generated polygons through extensive experiments: 1) By creating polygons from ground truth points, we achieved an accuracy of 82.0% on ICDAR 2015; 2) In training detectors with polygons generated by our method, we attained 86% of the accuracy relative to training with ground truth (GT); 3) Additionally, the proposed Point2Polygon can be seamlessly integrated to empower single-point spotters to generate polygons. This integration led to an impressive 82.5% accuracy for the generated polygons. It is worth mentioning that our method relies solely on synthetic recognition information, eliminating the need for any manual annotation beyond single points.
Hierarchical Side-Tuning for Vision Transformers
Oct 10, 2023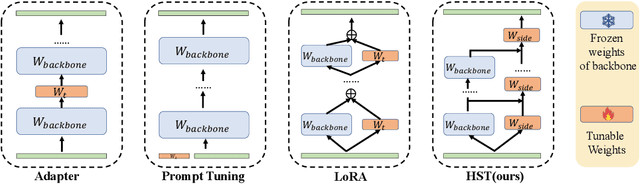
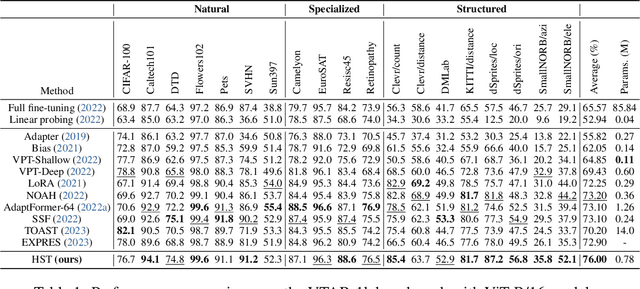
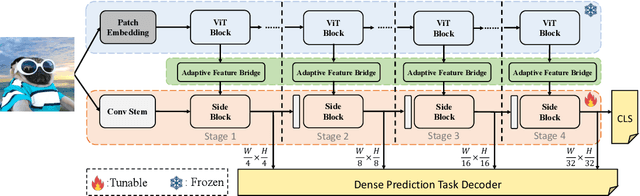
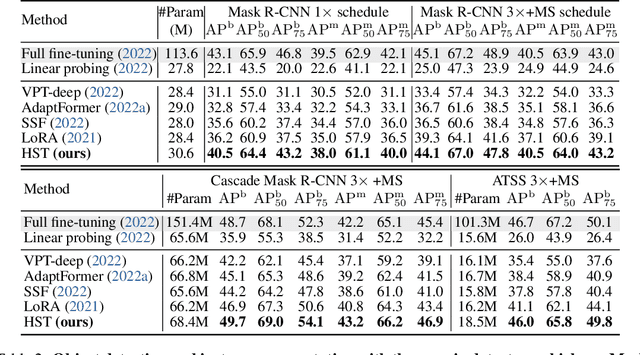
Fine-tuning pre-trained Vision Transformers (ViT) has consistently demonstrated promising performance in the realm of visual recognition. However, adapting large pre-trained models to various tasks poses a significant challenge. This challenge arises from the need for each model to undergo an independent and comprehensive fine-tuning process, leading to substantial computational and memory demands. While recent advancements in Parameter-efficient Transfer Learning (PETL) have demonstrated their ability to achieve superior performance compared to full fine-tuning with a smaller subset of parameter updates, they tend to overlook dense prediction tasks such as object detection and segmentation. In this paper, we introduce Hierarchical Side-Tuning (HST), a novel PETL approach that enables ViT transfer to various downstream tasks effectively. Diverging from existing methods that exclusively fine-tune parameters within input spaces or certain modules connected to the backbone, we tune a lightweight and hierarchical side network (HSN) that leverages intermediate activations extracted from the backbone and generates multi-scale features to make predictions. To validate HST, we conducted extensive experiments encompassing diverse visual tasks, including classification, object detection, instance segmentation, and semantic segmentation. Notably, our method achieves state-of-the-art average Top-1 accuracy of 76.0% on VTAB-1k, all while fine-tuning a mere 0.78M parameters. When applied to object detection tasks on COCO testdev benchmark, HST even surpasses full fine-tuning and obtains better performance with 49.7 box AP and 43.2 mask AP using Cascade Mask R-CNN.