 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLEAM: Learning to Match and Explain in Cross-View Geo-Localization
Sep 09, 2025Cross-View Geo-Localization (CVGL) focuses on identifying correspondences between images captured from distinct perspectives of the same geographical location. However, existing CVGL approaches are typically restricted to a single view or modality, and their direct visual matching strategy lacks interpretability: they merely predict whether two images correspond, without explaining the rationale behind the match. In this paper, we present GLEAM-C, a foundational CVGL model that unifies multiple views and modalities-including UAV imagery, street maps, panoramic views, and ground photographs-by aligning them exclusively with satellite imagery. Our framework enhances training efficiency through optimized implementation while achieving accuracy comparable to prior modality-specific CVGL models through a two-phase training strategy. Moreover, to address the lack of interpretability in traditional CVGL methods, we leverage the reasoning capabilities of multimodal large language models (MLLMs) to propose a new task, GLEAM-X, which combines cross-view correspondence prediction with explainable reasoning. To support this task, we construct a bilingual benchmark using GPT-4o and Doubao-1.5-Thinking-Vision-Pro to generate training and testing data. The test set is further refined through detailed human revision, enabling systematic evaluation of explainable cross-view reasoning and advancing transparency and scalability in geo-localization. Together, GLEAM-C and GLEAM-X form a comprehensive CVGL pipeline that integrates multi-modal, multi-view alignment with interpretable correspondence analysis, unifying accurate cross-view matching with explainable reasoning and advancing Geo-Localization by enabling models to better Explain And Match. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/GLEAM.
MINT-CoT: Enabling Interleaved Visual Tokens in Mathematical Chain-of-Thought Reasoning
Jun 05, 2025Chain-of-Thought (CoT) has widely enhanced mathematical reasoning in Large Language Models (LLMs), but it still remains challenging for extending it to multimodal domains. Existing works either adopt a similar textual reasoning for image input, or seek to interleave visual signals into mathematical CoT. However, they face three key limitations for math problem-solving: reliance on coarse-grained box-shaped image regions, limited perception of vision encoders on math content, and dependence on external capabilities for visual modification. In this paper, we propose MINT-CoT, introducing Mathematical INterleaved Tokens for Chain-of-Thought visual reasoning. MINT-CoT adaptively interleaves relevant visual tokens into textual reasoning steps via an Interleave Token, which dynamically selects visual regions of any shapes within math figures. To empower this capability, we construct the MINT-CoT dataset, containing 54K mathematical problems aligning each reasoning step with visual regions at the token level, accompanied by a rigorous data generation pipeline. We further present a three-stage MINT-CoT training strategy, progressively combining text-only CoT SFT, interleaved CoT SFT, and interleaved CoT RL, which derives our MINT-CoT-7B model. Extensive experiments demonstrate the effectiveness of our method for effective visual interleaved reasoning in mathematical domains, where MINT-CoT-7B outperforms the baseline model by +34.08% on MathVista, +28.78% on GeoQA, and +23.2% on MMStar, respectively. Our code and data are available at https://github.com/xinyan-cxy/MINT-CoT
Perceive Anything: Recognize, Explain, Caption, and Segment Anything in Images and Videos
Jun 05, 2025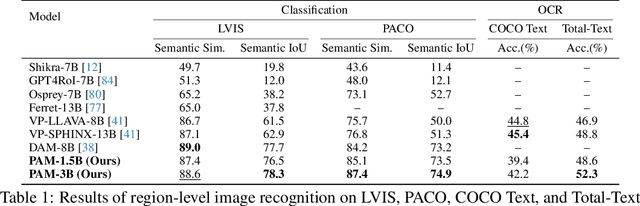
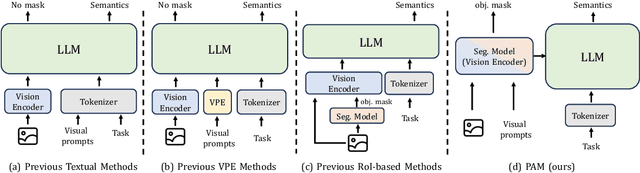
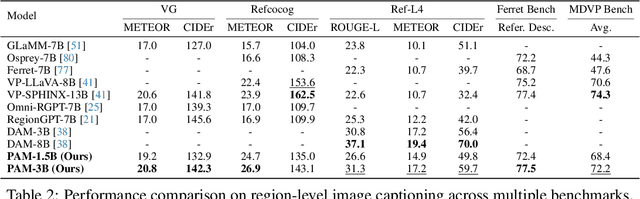
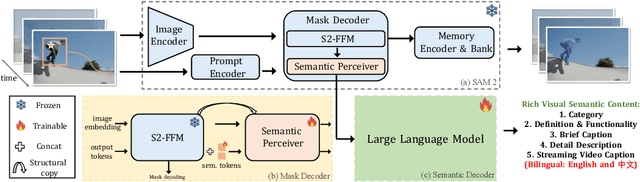
We present Perceive Anything Model (PAM), a conceptually straightforward and efficient framework for comprehensive region-level visual understanding in images and videos. Our approach extends the powerful segmentation model SAM 2 by integrating Large Language Models (LLMs), enabling simultaneous object segmentation with the generation of diverse, region-specific semantic outputs, including categories, label definition, functional explanations, and detailed captions. A key component, Semantic Perceiver, is introduced to efficiently transform SAM 2's rich visual features, which inherently carry general vision, localization, and semantic priors into multi-modal tokens for LLM comprehension. To support robust multi-granularity understanding, we also develop a dedicated data refinement and augmentation pipeline, yielding a high-quality dataset of 1.5M image and 0.6M video region-semantic annotations, including novel region-level streaming video caption data. PAM is designed for lightweightness and efficiency, while also demonstrates strong performance across a diverse range of region understanding tasks. It runs 1.2-2.4x faster and consumes less GPU memory than prior approaches, offering a practical solution for real-world applications. We believe that our effective approach will serve as a strong baseline for future research in region-level visual understanding.
UI-Genie: A Self-Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents
May 27, 2025In this paper, we introduce UI-Genie, a self-improving framework addressing two key challenges in GUI agents: verification of trajectory outcome is challenging and high-quality training data are not scalable. These challenges are addressed by a reward model and a self-improving pipeline, respectively. The reward model, UI-Genie-RM, features an image-text interleaved architecture that efficiently pro- cesses historical context and unifies action-level and task-level rewards. To sup- port the training of UI-Genie-RM, we develop deliberately-designed data genera- tion strategies including rule-based verification, controlled trajectory corruption, and hard negative mining. To address the second challenge, a self-improvement pipeline progressively expands solvable complex GUI tasks by enhancing both the agent and reward models through reward-guided exploration and outcome verification in dynamic environments. For training the model, we generate UI- Genie-RM-517k and UI-Genie-Agent-16k, establishing the first reward-specific dataset for GUI agents while demonstrating high-quality synthetic trajectory gen- eration without manual annotation. Experimental results show that UI-Genie achieves state-of-the-art performance across multiple GUI agent benchmarks with three generations of data-model self-improvement. We open-source our complete framework implementation and generated datasets to facilitate further research in https://github.com/Euphoria16/UI-Genie.
IMAGINE-E: Image Generation Intelligence Evaluation of State-of-the-art Text-to-Image Models
Jan 23, 2025



With the rapid development of diffusion models, text-to-image(T2I) models have made significant progress, showcasing impressive abilities in prompt following and image generation. Recently launched models such as FLUX.1 and Ideogram2.0, along with others like Dall-E3 and Stable Diffusion 3, have demonstrated exceptional performance across various complex tasks, raising questions about whether T2I models are moving towards general-purpose applicability. Beyond traditional image generation, these models exhibit capabilities across a range of fields, including controllable generation, image editing, video, audio, 3D, and motion generation, as well as computer vision tasks like semantic segmentation and depth estimation. However, current evaluation frameworks are insufficient to comprehensively assess these models' performance across expanding domains. To thoroughly evaluate these models, we developed the IMAGINE-E and tested six prominent models: FLUX.1, Ideogram2.0, Midjourney, Dall-E3, Stable Diffusion 3, and Jimeng. Our evaluation is divided into five key domains: structured output generation, realism, and physical consistency, specific domain generation, challenging scenario generation, and multi-style creation tasks. This comprehensive assessment highlights each model's strengths and limitations, particularly the outstanding performance of FLUX.1 and Ideogram2.0 in structured and specific domain tasks, underscoring the expanding applications and potential of T2I models as foundational AI tools. This study provides valuable insights into the current state and future trajectory of T2I models as they evolve towards general-purpose usability. Evaluation scripts will be released at https://github.com/jylei16/Imagine-e.
Lumina-mGPT: Illuminate Flexible Photorealistic Text-to-Image Generation with Multimodal Generative Pretraining
Aug 05, 2024



We present Lumina-mGPT, a family of multimodal autoregressive models capable of various vision and language tasks, particularly excelling in generating flexible photorealistic images from text descriptions. Unlike existing autoregressive image generation approaches, Lumina-mGPT employs a pretrained decoder-only transformer as a unified framework for modeling multimodal token sequences. Our key insight is that a simple decoder-only transformer with multimodal Generative PreTraining (mGPT), utilizing the next-token prediction objective on massive interleaved text-image sequences, can learn broad and general multimodal capabilities, thereby illuminating photorealistic text-to-image generation. Building on these pretrained models, we propose Flexible Progressive Supervised Finetuning (FP-SFT) on high-quality image-text pairs to fully unlock their potential for high-aesthetic image synthesis at any resolution while maintaining their general multimodal capabilities. Furthermore, we introduce Ominiponent Supervised Finetuning (Omni-SFT), transforming Lumina-mGPT into a foundation model that seamlessly achieves omnipotent task unification. The resulting model demonstrates versatile multimodal capabilities, including visual generation tasks like flexible text-to-image generation and controllable generation, visual recognition tasks like segmentation and depth estimation, and vision-language tasks like multiturn visual question answering. Additionally, we analyze the differences and similarities between diffusion-based and autoregressive methods in a direct comparison.
Draw-and-Understand: Leveraging Visual Prompts to Enable MLLMs to Comprehend What You Want
Apr 01, 2024
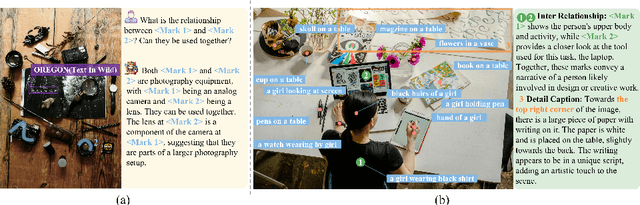

The interaction between humans and artificial intelligence (AI) is a crucial factor that reflects the effectiveness of multimodal large language models (MLLMs). However, current MLLMs primarily focus on image-level comprehension and limit interaction to textual instructions, thereby constraining their flexibility in usage and depth of response. In this paper, we introduce the Draw-and-Understand project: a new model, a multi-domain dataset, and a challenging benchmark for visual prompting. Specifically, we propose SPHINX-V, a new end-to-end trained Multimodal Large Language Model (MLLM) that connects a vision encoder, a visual prompt encoder and an LLM for various visual prompts (points, bounding boxes, and free-form shape) and language understanding. To advance visual prompting research for MLLMs, we introduce MDVP-Data and MDVP-Bench. MDVP-Data features a multi-domain dataset containing 1.6M unique image-visual prompt-text instruction-following samples, including natural images, document images, OCR images, mobile screenshots, web screenshots, and multi-panel images. Furthermore, we present MDVP-Bench, a comprehensive and challenging benchmark to assess a model's capability in understanding visual prompting instructions. Our experiments demonstrate SPHINX-V's impressive multimodal interaction capabilities through visual prompting, revealing significant improvements in detailed pixel-level description and question-answering abilities.
SPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models
Feb 08, 2024



We propose SPHINX-X, an extensive Multimodality Large Language Model (MLLM) series developed upon SPHINX. To improve the architecture and training efficiency, we modify the SPHINX framework by removing redundant visual encoders, bypassing fully-padded sub-images with skip tokens, and simplifying multi-stage training into a one-stage all-in-one paradigm. To fully unleash the potential of MLLMs, we assemble a comprehensive multi-domain and multimodal dataset covering publicly available resources in language, vision, and vision-language tasks. We further enrich this collection with our curated OCR intensive and Set-of-Mark datasets, extending the diversity and generality. By training over different base LLMs including TinyLlama1.1B, InternLM2-7B, LLaMA2-13B, and Mixtral8x7B, we obtain a spectrum of MLLMs that vary in parameter size and multilingual capabilities. Comprehensive benchmarking reveals a strong correlation between the multi-modal performance with the data and parameter scales. Code and models are released at https://github.com/Alpha-VLLM/LLaMA2-Accessory
Hierarchical Side-Tuning for Vision Transformers
Oct 10, 2023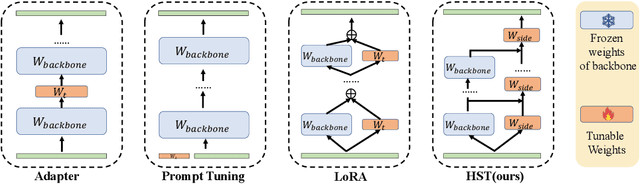
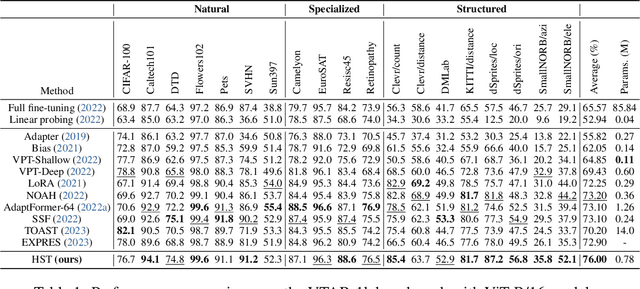
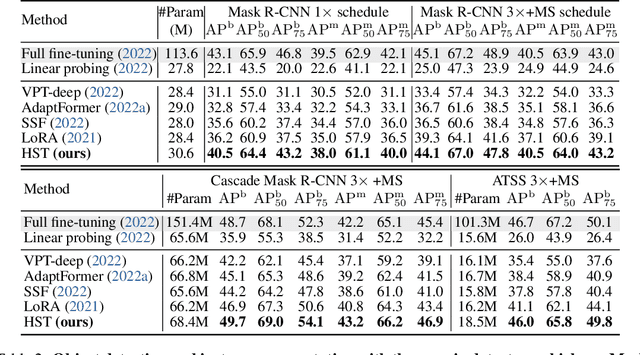
Fine-tuning pre-trained Vision Transformers (ViT) has consistently demonstrated promising performance in the realm of visual recognition. However, adapting large pre-trained models to various tasks poses a significant challenge. This challenge arises from the need for each model to undergo an independent and comprehensive fine-tuning process, leading to substantial computational and memory demands. While recent advancements in Parameter-efficient Transfer Learning (PETL) have demonstrated their ability to achieve superior performance compared to full fine-tuning with a smaller subset of parameter updates, they tend to overlook dense prediction tasks such as object detection and segmentation. In this paper, we introduce Hierarchical Side-Tuning (HST), a novel PETL approach that enables ViT transfer to various downstream tasks effectively. Diverging from existing methods that exclusively fine-tune parameters within input spaces or certain modules connected to the backbone, we tune a lightweight and hierarchical side network (HSN) that leverages intermediate activations extracted from the backbone and generates multi-scale features to make predictions. To validate HST, we conducted extensive experiments encompassing diverse visual tasks, including classification, object detection, instance segmentation, and semantic segmentation. Notably, our method achieves state-of-the-art average Top-1 accuracy of 76.0% on VTAB-1k, all while fine-tuning a mere 0.78M parameters. When applied to object detection tasks on COCO testdev benchmark, HST even surpasses full fine-tuning and obtains better performance with 49.7 box AP and 43.2 mask AP using Cascade Mask R-CNN.
Scale-Aware Modulation Meet Transformer
Jul 26, 2023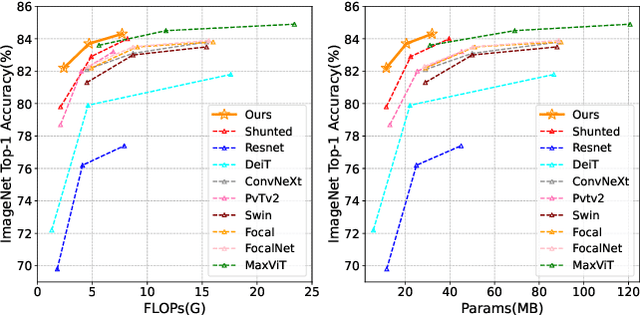
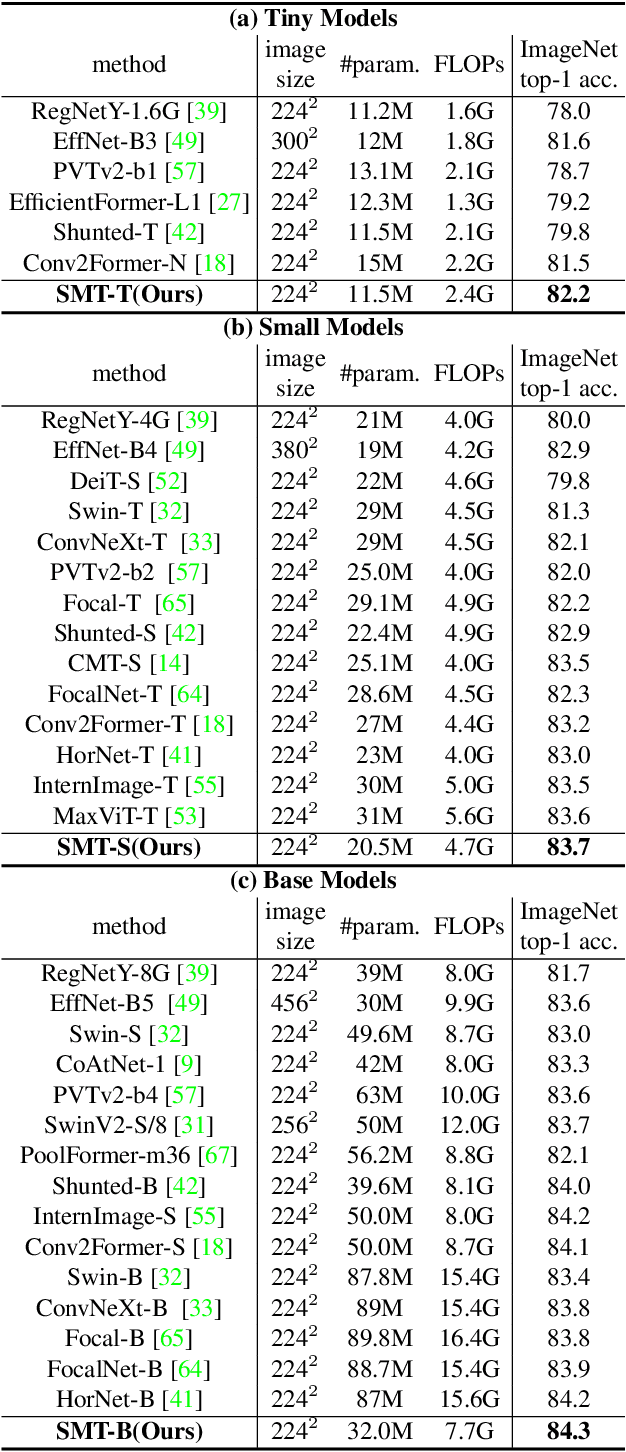
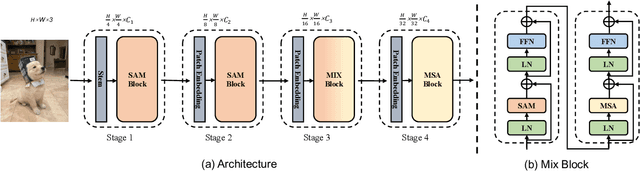
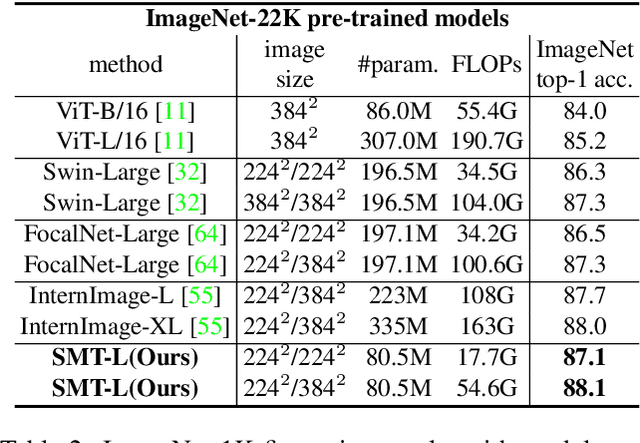
This paper presents a new vision Transformer, Scale-Aware Modulation Transformer (SMT), that can handle various downstream tasks efficiently by combining the convolutional network and vision Transformer. The proposed Scale-Aware Modulation (SAM) in the SMT includes two primary novel designs. Firstly, we introduce the Multi-Head Mixed Convolution (MHMC) module, which can capture multi-scale features and expand the receptive field. Secondly, we propose the Scale-Aware Aggregation (SAA) module, which is lightweight but effective, enabling information fusion across different heads. By leveraging these two modules, convolutional modulation is further enhanced. Furthermore, in contrast to prior works that utilized modulations throughout all stages to build an attention-free network, we propose an Evolutionary Hybrid Network (EHN), which can effectively simulate the shift from capturing local to global dependencies as the network becomes deeper, resulting in superior performance. Extensive experiments demonstrate that SMT significantly outperforms existing state-of-the-art models across a wide range of visual tasks. Specifically, SMT with 11.5M / 2.4GFLOPs and 32M / 7.7GFLOPs can achieve 82.2% and 84.3% top-1 accuracy on ImageNet-1K, respectively. After pretrained on ImageNet-22K in 224^2 resolution, it attains 87.1% and 88.1% top-1 accuracy when finetuned with resolution 224^2 and 384^2, respectively. For object detection with Mask R-CNN, the SMT base trained with 1x and 3x schedule outperforms the Swin Transformer counterpart by 4.2 and 1.3 mAP on COCO, respectively. For semantic segmentation with UPerNet, the SMT base test at single- and multi-scale surpasses Swin by 2.0 and 1.1 mIoU respectively on the ADE20K.