 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Before Acting: Enhancing Vision Foundation Representations for Vision-Language-Action Models
Mar 17, 2026Vision-Language-Action (VLA) models have recently emerged as a promising paradigm for robotic manipulation, in which reliable action prediction critically depends on accurately interpreting and integrating visual observations conditioned on language instructions. Although recent works have sought to enhance the visual capabilities of VLA models, most approaches treat the LLM backbone as a black box, providing limited insight into how visual information is grounded into action generation. Therefore, we perform a systematic analysis of multiple VLA models across different action-generation paradigms and observe that sensitivity to visual tokens progressively decreases in deeper layers during action generation. Motivated by this observation, we propose \textbf{DeepVision-VLA}, built on a \textbf{Vision-Language Mixture-of-Transformers (VL-MoT)} framework. This framework enables shared attention between the vision foundation model and the VLA backbone, injecting multi-level visual features from the vision expert into deeper layers of the VLA backbone to enhance visual representations for precise and complex manipulation. In addition, we introduce \textbf{Action-Guided Visual Pruning (AGVP)}, which leverages shallow-layer attention to prune irrelevant visual tokens while preserving task-relevant ones, reinforcing critical visual cues for manipulation with minimal computational overhead. DeepVision-VLA outperforms prior state-of-the-art methods by 9.0\% and 7.5\% on simulated and real-world tasks, respectively, providing new insights for the design of visually enhanced VLA models.
Wow, wo, val! A Comprehensive Embodied World Model Evaluation Turing Test
Jan 07, 2026As world models gain momentum in Embodied AI, an increasing number of works explore using video foundation models as predictive world models for downstream embodied tasks like 3D prediction or interactive generation. However, before exploring these downstream tasks, video foundation models still have two critical questions unanswered: (1) whether their generative generalization is sufficient to maintain perceptual fidelity in the eyes of human observers, and (2) whether they are robust enough to serve as a universal prior for real-world embodied agents. To provide a standardized framework for answering these questions, we introduce the Embodied Turing Test benchmark: WoW-World-Eval (Wow,wo,val). Building upon 609 robot manipulation data, Wow-wo-val examines five core abilities, including perception, planning, prediction, generalization, and execution. We propose a comprehensive evaluation protocol with 22 metrics to assess the models' generation ability, which achieves a high Pearson Correlation between the overall score and human preference (>0.93) and establishes a reliable foundation for the Human Turing Test. On Wow-wo-val, models achieve only 17.27 on long-horizon planning and at best 68.02 on physical consistency, indicating limited spatiotemporal consistency and physical reasoning. For the Inverse Dynamic Model Turing Test, we first use an IDM to evaluate the video foundation models' execution accuracy in the real world. However, most models collapse to $\approx$ 0% success, while WoW maintains a 40.74% success rate. These findings point to a noticeable gap between the generated videos and the real world, highlighting the urgency and necessity of benchmarking World Model in Embodied AI.
Jarvis: Towards Personalized AI Assistant via Personal KV-Cache Retrieval
Oct 26, 2025
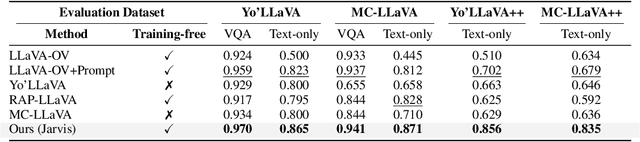
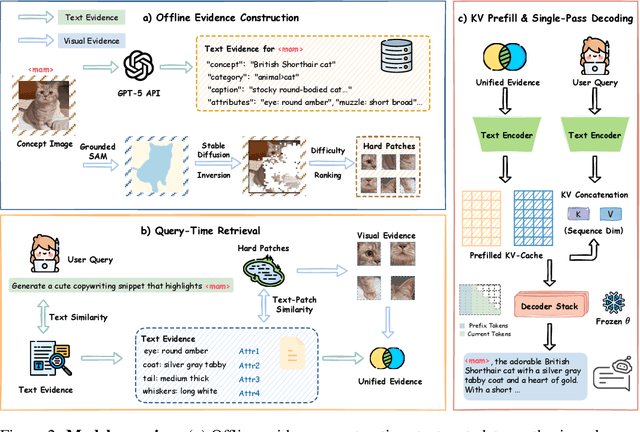
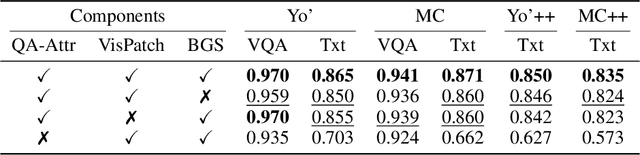
The rapid development of Vision-language models (VLMs) enables open-ended perception and reasoning. Recent works have started to investigate how to adapt general-purpose VLMs into personalized assistants. Even commercial models such as ChatGPT now support model personalization by incorporating user-specific information. However, existing methods either learn a set of concept tokens or train a VLM to utilize user-specific information. However, both pipelines struggle to generate accurate answers as personalized assistants. We introduce Jarvis, an innovative framework for a personalized AI assistant through personal KV-Cache retrieval, which stores user-specific information in the KV-Caches of both textual and visual tokens. The textual tokens are created by summarizing user information into metadata, while the visual tokens are produced by extracting distinct image patches from the user's images. When answering a question, Jarvis first retrieves related KV-Caches from personal storage and uses them to ensure accuracy in responses. We also introduce a fine-grained benchmark built with the same distinct image patch mining pipeline, emphasizing accurate question answering based on fine-grained user-specific information. Jarvis is capable of providing more accurate responses, particularly when they depend on specific local details. Jarvis achieves state-of-the-art results in both visual question answering and text-only tasks across multiple datasets, indicating a practical path toward personalized AI assistants. The code and dataset will be released.
WoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
UniCTokens: Boosting Personalized Understanding and Generation via Unified Concept Tokens
May 20, 2025Personalized models have demonstrated remarkable success in understanding and generating concepts provided by users. However, existing methods use separate concept tokens for understanding and generation, treating these tasks in isolation. This may result in limitations for generating images with complex prompts. For example, given the concept $\langle bo\rangle$, generating "$\langle bo\rangle$ wearing its hat" without additional textual descriptions of its hat. We call this kind of generation personalized knowledge-driven generation. To address the limitation, we present UniCTokens, a novel framework that effectively integrates personalized information into a unified vision language model (VLM) for understanding and generation. UniCTokens trains a set of unified concept tokens to leverage complementary semantics, boosting two personalized tasks. Moreover, we propose a progressive training strategy with three stages: understanding warm-up, bootstrapping generation from understanding, and deepening understanding from generation to enhance mutual benefits between both tasks. To quantitatively evaluate the unified VLM personalization, we present UnifyBench, the first benchmark for assessing concept understanding, concept generation, and knowledge-driven generation. Experimental results on UnifyBench indicate that UniCTokens shows competitive performance compared to leading methods in concept understanding, concept generation, and achieving state-of-the-art results in personalized knowledge-driven generation. Our research demonstrates that enhanced understanding improves generation, and the generation process can yield valuable insights into understanding. Our code and dataset will be released at: \href{https://github.com/arctanxarc/UniCTokens}{https://github.com/arctanxarc/UniCTokens}.
Concept-as-Tree: Synthetic Data is All You Need for VLM Personalization
Mar 17, 2025Vision-Language Models (VLMs) have demonstrated exceptional performance in various multi-modal tasks. Recently, there has been an increasing interest in improving the personalization capabilities of VLMs. To better integrate user-provided concepts into VLMs, many methods use positive and negative samples to fine-tune these models. However, the scarcity of user-provided positive samples and the low quality of retrieved negative samples pose challenges for fine-tuning. To reveal the relationship between sample and model performance, we systematically investigate the impact of positive and negative samples (easy and hard) and their diversity on VLM personalization tasks. Based on the detailed analysis, we introduce Concept-as-Tree (CaT), which represents a concept as a tree structure, thereby enabling the data generation of positive and negative samples with varying difficulty and diversity for VLM personalization. With a well-designed data filtering strategy, our CaT framework can ensure the quality of generated data, constituting a powerful pipeline. We perform thorough experiments with various VLM personalization baselines to assess the effectiveness of the pipeline, alleviating the lack of positive samples and the low quality of negative samples. Our results demonstrate that CaT equipped with the proposed data filter significantly enhances the personalization capabilities of VLMs across the MyVLM, Yo'LLaVA, and MC-LLaVA datasets. To our knowledge, this work is the first controllable synthetic data pipeline for VLM personalization. The code is released at \href{https://github.com/zengkaiya/CaT}{https://github.com/zengkaiya/CaT}.
SCBench: A Sports Commentary Benchmark for Video LLMs
Dec 23, 2024Recently, significant advances have been made in Video Large Language Models (Video LLMs) in both academia and industry. However, methods to evaluate and benchmark the performance of different Video LLMs, especially their fine-grained, temporal visual capabilities, remain very limited. On one hand, current benchmarks use relatively simple videos (e.g., subtitled movie clips) where the model can understand the entire video by processing just a few frames. On the other hand, their datasets lack diversity in task format, comprising only QA or multi-choice QA, which overlooks the models' capacity for generating in-depth and precise texts. Sports videos, which feature intricate visual information, sequential events, and emotionally charged commentary, present a critical challenge for Video LLMs, making sports commentary an ideal benchmarking task. Inspired by these challenges, we propose a novel task: sports video commentary generation, developed $\textbf{SCBench}$ for Video LLMs. To construct such a benchmark, we introduce (1) $\textbf{SCORES}$, a six-dimensional metric specifically designed for our task, upon which we propose a GPT-based evaluation method, and (2) $\textbf{CommentarySet}$, a dataset consisting of 5,775 annotated video clips and ground-truth labels tailored to our metric. Based on SCBench, we conduct comprehensive evaluations on multiple Video LLMs (e.g. VILA, Video-LLaVA, etc.) and chain-of-thought baseline methods. Our results found that InternVL-Chat-2 achieves the best performance with 5.44, surpassing the second-best by 1.04. Our work provides a fresh perspective for future research, aiming to enhance models' overall capabilities in complex visual understanding tasks. Our dataset will be released soon.
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Dec 18, 2024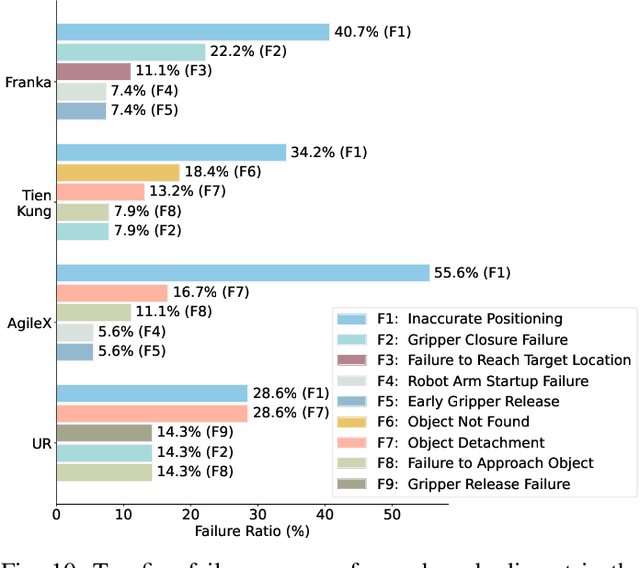
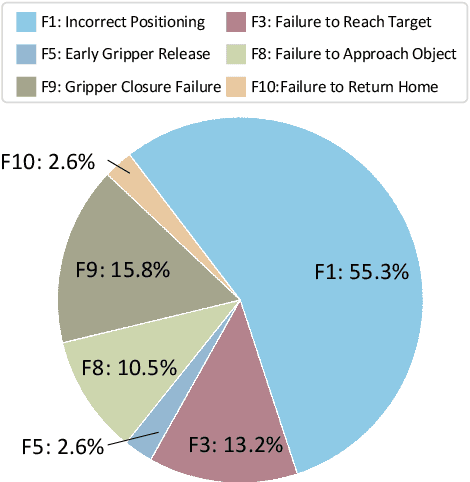
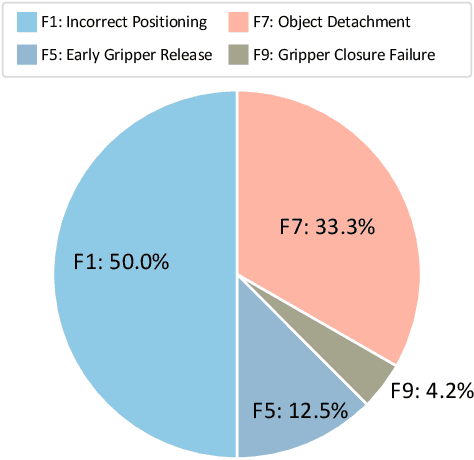
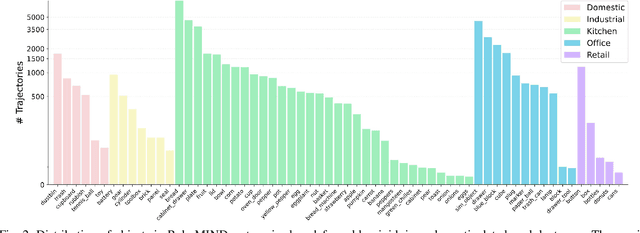
Developing robust and general-purpose robotic manipulation policies is a key goal in the field of robotics. To achieve effective generalization, it is essential to construct comprehensive datasets that encompass a large number of demonstration trajectories and diverse tasks. Unlike vision or language data that can be collected from the Internet, robotic datasets require detailed observations and manipulation actions, necessitating significant investment in hardware-software infrastructure and human labor. While existing works have focused on assembling various individual robot datasets, there remains a lack of a unified data collection standard and insufficient diversity in tasks, scenarios, and robot types. In this paper, we introduce RoboMIND (Multi-embodiment Intelligence Normative Data for Robot manipulation), featuring 55k real-world demonstration trajectories across 279 diverse tasks involving 61 different object classes. RoboMIND is collected through human teleoperation and encompasses comprehensive robotic-related information, including multi-view RGB-D images, proprioceptive robot state information, end effector details, and linguistic task descriptions. To ensure dataset consistency and reliability during policy learning, RoboMIND is built on a unified data collection platform and standardized protocol, covering four distinct robotic embodiments. We provide a thorough quantitative and qualitative analysis of RoboMIND across multiple dimensions, offering detailed insights into the diversity of our datasets. In our experiments, we conduct extensive real-world testing with four state-of-the-art imitation learning methods, demonstrating that training with RoboMIND data results in a high manipulation success rate and strong generalization. Our project is at https://x-humanoid-robomind.github.io/.
MC-LLaVA: Multi-Concept Personalized Vision-Language Model
Nov 18, 2024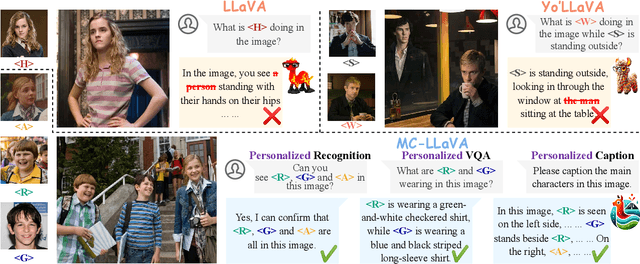

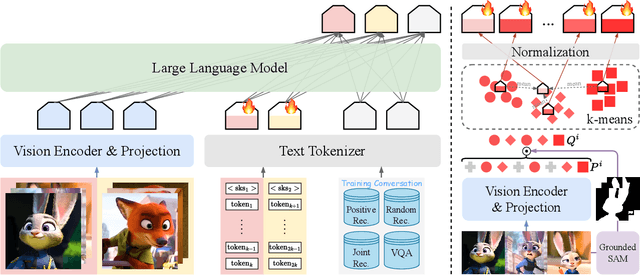
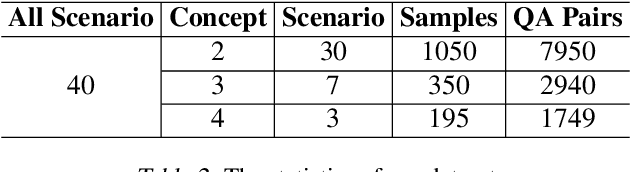
Current vision-language models (VLMs) show exceptional abilities across diverse tasks including visual question answering. To enhance user experience in practical applications, recent studies investigate VLM personalization to understand user-provided concepts. However, existing studies mainly focus on single-concept personalization, neglecting the existence and interplay of multiple concepts, which limits the real-world applicability of personalized VLMs. In this paper, we propose the first multi-concept personalization method named MC-LLaVA along with a high-quality multi-concept personalization dataset. Specifically, MC-LLaVA uses a joint training strategy incorporating multiple concepts in a single training step, allowing VLMs to perform accurately in multi-concept personalization. To reduce the cost of joint training, MC-LLaVA leverages visual token information for concept token initialization, yielding improved concept representation and accelerating joint training. To advance multi-concept personalization research, we further contribute a high-quality dataset. We carefully collect images from various movies that contain multiple characters and manually generate the multi-concept question-answer samples. Our dataset features diverse movie types and question-answer types. We conduct comprehensive qualitative and quantitative experiments to demonstrate that MC-LLaVA can achieve impressive multi-concept personalized responses, paving the way for VLMs to become better user-specific assistants. The code and dataset will be publicly available at https://github.com/arctanxarc/MC-LLaVA.
Expert-level vision-language foundation model for real-world radiology and comprehensive evaluation
Sep 24, 2024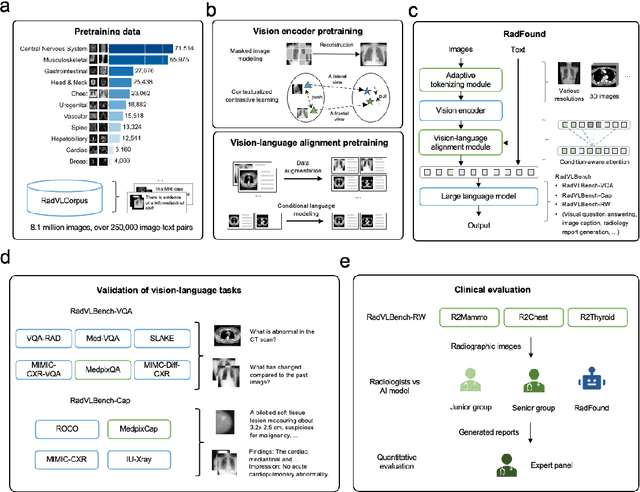
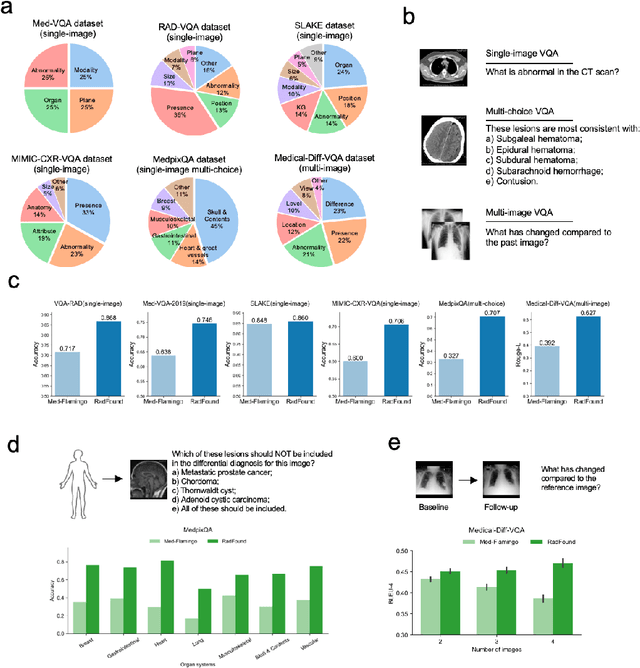
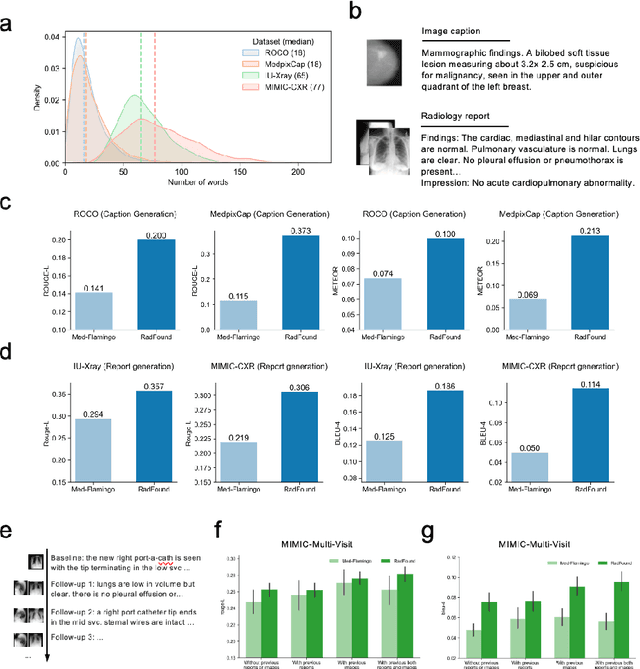
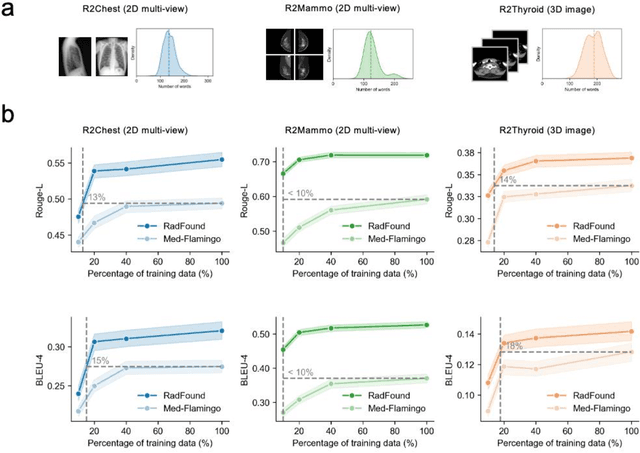
Radiology is a vital and complex component of modern clinical workflow and covers many tasks. Recently, vision-language (VL) foundation models in medicine have shown potential in processing multimodal information, offering a unified solution for various radiology tasks. However, existing studies either pre-trained VL models on natural data or did not fully integrate vision-language architecture and pretraining, often neglecting the unique multimodal complexity in radiology images and their textual contexts. Additionally, their practical applicability in real-world scenarios remains underexplored. Here, we present RadFound, a large and open-source vision-language foundation model tailored for radiology, that is trained on the most extensive dataset of over 8.1 million images and 250,000 image-text pairs, covering 19 major organ systems and 10 imaging modalities. To establish expert-level multimodal perception and generation capabilities, RadFound introduces an enhanced vision encoder to capture intra-image local features and inter-image contextual information, and a unified cross-modal learning design tailored to radiology. To fully assess the models' capability, we construct a benchmark, RadVLBench, including radiology interpretation tasks like medical vision-language question-answering, as well as text generation tasks ranging from captioning to report generation. We also propose a human evaluation framework. When evaluated on the real-world benchmark involving three representative modalities, 2D images (chest X-rays), multi-view images (mammograms), and 3D images (thyroid CT scans), RadFound significantly outperforms other VL foundation models on both quantitative metrics and human evaluation. In summary, the development of RadFound represents an advancement in radiology generalists, demonstrating broad applicability potential for integration into clinical workflows.