 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Masked Face Recognition under Different Backbones
Jan 23, 2026Erratum to the paper (Zhang et al., 2025): corrections to Table IV and the data in Page 3, Section A. In the post-pandemic era, a high proportion of civil aviation passengers wear masks during security checks, posing significant challenges to traditional face recognition models. The backbone network serves as the core component of face recognition models. In standard tests, r100 series models excelled (98%+ accuracy at 0.01% FAR in face comparison, high top1/top5 in search). r50 ranked second, r34_mask_v1 lagged. In masked tests, r100_mask_v2 led (90.07% accuracy), r50_mask_v3 performed best among r50 but trailed r100. Vit-Small/Tiny showed strong masked performance with gains in effectiveness. Through extensive comparative experiments, this paper conducts a comprehensive evaluation of several core backbone networks, aiming to reveal the impacts of different models on face recognition with and without masks, and provide specific deployment recommendations.
RoboMIND 2.0: A Multimodal, Bimanual Mobile Manipulation Dataset for Generalizable Embodied Intelligence
Dec 31, 2025While data-driven imitation learning has revolutionized robotic manipulation, current approaches remain constrained by the scarcity of large-scale, diverse real-world demonstrations. Consequently, the ability of existing models to generalize across long-horizon bimanual tasks and mobile manipulation in unstructured environments remains limited. To bridge this gap, we present RoboMIND 2.0, a comprehensive real-world dataset comprising over 310K dual-arm manipulation trajectories collected across six distinct robot embodiments and 739 complex tasks. Crucially, to support research in contact-rich and spatially extended tasks, the dataset incorporates 12K tactile-enhanced episodes and 20K mobile manipulation trajectories. Complementing this physical data, we construct high-fidelity digital twins of our real-world environments, releasing an additional 20K-trajectory simulated dataset to facilitate robust sim-to-real transfer. To fully exploit the potential of RoboMIND 2.0, we propose MIND-2 system, a hierarchical dual-system frame-work optimized via offline reinforcement learning. MIND-2 integrates a high-level semantic planner (MIND-2-VLM) to decompose abstract natural language instructions into grounded subgoals, coupled with a low-level Vision-Language-Action executor (MIND-2-VLA), which generates precise, proprioception-aware motor actions.
Real-world Reinforcement Learning from Suboptimal Interventions
Dec 30, 2025Real-world reinforcement learning (RL) offers a promising approach to training precise and dexterous robotic manipulation policies in an online manner, enabling robots to learn from their own experience while gradually reducing human labor. However, prior real-world RL methods often assume that human interventions are optimal across the entire state space, overlooking the fact that even expert operators cannot consistently provide optimal actions in all states or completely avoid mistakes. Indiscriminately mixing intervention data with robot-collected data inherits the sample inefficiency of RL, while purely imitating intervention data can ultimately degrade the final performance achievable by RL. The question of how to leverage potentially suboptimal and noisy human interventions to accelerate learning without being constrained by them thus remains open. To address this challenge, we propose SiLRI, a state-wise Lagrangian reinforcement learning algorithm for real-world robot manipulation tasks. Specifically, we formulate the online manipulation problem as a constrained RL optimization, where the constraint bound at each state is determined by the uncertainty of human interventions. We then introduce a state-wise Lagrange multiplier and solve the problem via a min-max optimization, jointly optimizing the policy and the Lagrange multiplier to reach a saddle point. Built upon a human-as-copilot teleoperation system, our algorithm is evaluated through real-world experiments on diverse manipulation tasks. Experimental results show that SiLRI effectively exploits human suboptimal interventions, reducing the time required to reach a 90% success rate by at least 50% compared with the state-of-the-art RL method HIL-SERL, and achieving a 100% success rate on long-horizon manipulation tasks where other RL methods struggle to succeed. Project website: https://silri-rl.github.io/.
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
MLA: A Multisensory Language-Action Model for Multimodal Understanding and Forecasting in Robotic Manipulation
Sep 30, 2025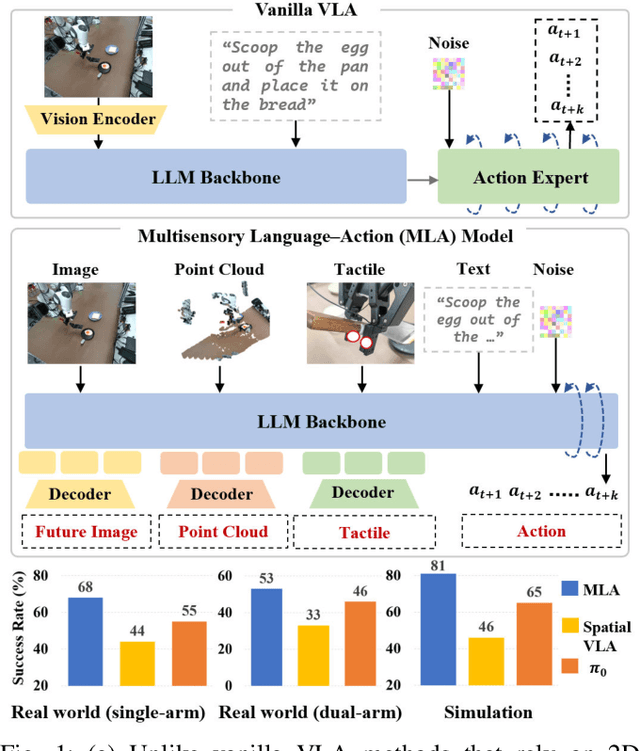
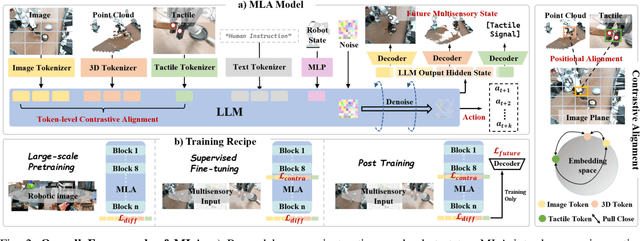
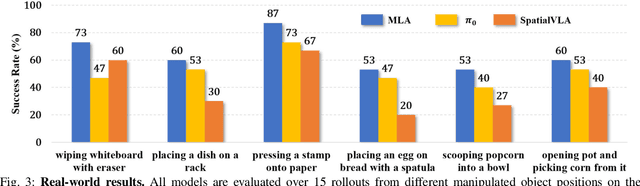

Vision-language-action models (VLAs) have shown generalization capabilities in robotic manipulation tasks by inheriting from vision-language models (VLMs) and learning action generation. Most VLA models focus on interpreting vision and language to generate actions, whereas robots must perceive and interact within the spatial-physical world. This gap highlights the need for a comprehensive understanding of robotic-specific multisensory information, which is crucial for achieving complex and contact-rich control. To this end, we introduce a multisensory language-action (MLA) model that collaboratively perceives heterogeneous sensory modalities and predicts future multisensory objectives to facilitate physical world modeling. Specifically, to enhance perceptual representations, we propose an encoder-free multimodal alignment scheme that innovatively repurposes the large language model itself as a perception module, directly interpreting multimodal cues by aligning 2D images, 3D point clouds, and tactile tokens through positional correspondence. To further enhance MLA's understanding of physical dynamics, we design a future multisensory generation post-training strategy that enables MLA to reason about semantic, geometric, and interaction information, providing more robust conditions for action generation. For evaluation, the MLA model outperforms the previous state-of-the-art 2D and 3D VLA methods by 12% and 24% in complex, contact-rich real-world tasks, respectively, while also demonstrating improved generalization to unseen configurations. Project website: https://sites.google.com/view/open-mla
Ideal Registration? Segmentation is All You Need
Sep 19, 2025Deep learning has revolutionized image registration by its ability to handle diverse tasks while achieving significant speed advantages over conventional approaches. Current approaches, however, often employ globally uniform smoothness constraints that fail to accommodate the complex, regionally varying deformations characteristic of anatomical motion. To address this limitation, we propose SegReg, a Segmentation-driven Registration framework that implements anatomically adaptive regularization by exploiting region-specific deformation patterns. Our SegReg first decomposes input moving and fixed images into anatomically coherent subregions through segmentation. These localized domains are then processed by the same registration backbone to compute optimized partial deformation fields, which are subsequently integrated into a global deformation field. SegReg achieves near-perfect structural alignment (98.23% Dice on critical anatomies) using ground-truth segmentation, and outperforms existing methods by 2-12% across three clinical registration scenarios (cardiac, abdominal, and lung images) even with automatic segmentation. Our SegReg demonstrates a near-linear dependence of registration accuracy on segmentation quality, transforming the registration challenge into a segmentation problem. The source code will be released upon manuscript acceptance.
Region-based Cluster Discrimination for Visual Representation Learning
Jul 26, 2025Learning visual representations is foundational for a broad spectrum of downstream tasks. Although recent vision-language contrastive models, such as CLIP and SigLIP, have achieved impressive zero-shot performance via large-scale vision-language alignment, their reliance on global representations constrains their effectiveness for dense prediction tasks, such as grounding, OCR, and segmentation. To address this gap, we introduce Region-Aware Cluster Discrimination (RICE), a novel method that enhances region-level visual and OCR capabilities. We first construct a billion-scale candidate region dataset and propose a Region Transformer layer to extract rich regional semantics. We further design a unified region cluster discrimination loss that jointly supports object and OCR learning within a single classification framework, enabling efficient and scalable distributed training on large-scale data. Extensive experiments show that RICE consistently outperforms previous methods on tasks, including segmentation, dense detection, and visual perception for Multimodal Large Language Models (MLLMs). The pre-trained models have been released at https://github.com/deepglint/MVT.
FreqPolicy: Efficient Flow-based Visuomotor Policy via Frequency Consistency
Jun 10, 2025Generative modeling-based visuomotor policies have been widely adopted in robotic manipulation attributed to their ability to model multimodal action distributions. However, the high inference cost of multi-step sampling limits their applicability in real-time robotic systems. To address this issue, existing approaches accelerate the sampling process in generative modeling-based visuomotor policies by adapting acceleration techniques originally developed for image generation. Despite this progress, a major distinction remains: image generation typically involves producing independent samples without temporal dependencies, whereas robotic manipulation involves generating time-series action trajectories that require continuity and temporal coherence. To effectively exploit temporal information in robotic manipulation, we propose FreqPolicy, a novel approach that first imposes frequency consistency constraints on flow-based visuomotor policies. Our work enables the action model to capture temporal structure effectively while supporting efficient, high-quality one-step action generation. We introduce a frequency consistency constraint that enforces alignment of frequency-domain action features across different timesteps along the flow, thereby promoting convergence of one-step action generation toward the target distribution. In addition, we design an adaptive consistency loss to capture structural temporal variations inherent in robotic manipulation tasks. We assess FreqPolicy on 53 tasks across 3 simulation benchmarks, proving its superiority over existing one-step action generators. We further integrate FreqPolicy into the vision-language-action (VLA) model and achieve acceleration without performance degradation on the 40 tasks of Libero. Besides, we show efficiency and effectiveness in real-world robotic scenarios with an inference frequency 93.5Hz. The code will be publicly available.
ArtVIP: Articulated Digital Assets of Visual Realism, Modular Interaction, and Physical Fidelity for Robot Learning
Jun 06, 2025Robot learning increasingly relies on simulation to advance complex ability such as dexterous manipulations and precise interactions, necessitating high-quality digital assets to bridge the sim-to-real gap. However, existing open-source articulated-object datasets for simulation are limited by insufficient visual realism and low physical fidelity, which hinder their utility for training models mastering robotic tasks in real world. To address these challenges, we introduce ArtVIP, a comprehensive open-source dataset comprising high-quality digital-twin articulated objects, accompanied by indoor-scene assets. Crafted by professional 3D modelers adhering to unified standards, ArtVIP ensures visual realism through precise geometric meshes and high-resolution textures, while physical fidelity is achieved via fine-tuned dynamic parameters. Meanwhile, the dataset pioneers embedded modular interaction behaviors within assets and pixel-level affordance annotations. Feature-map visualization and optical motion capture are employed to quantitatively demonstrate ArtVIP's visual and physical fidelity, with its applicability validated across imitation learning and reinforcement learning experiments. Provided in USD format with detailed production guidelines, ArtVIP is fully open-source, benefiting the research community and advancing robot learning research. Our project is at https://x-humanoid-artvip.github.io/ .