 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-ROAR: Outlier-Aware Rescaling for RoPE Position Interpolation in Quantized Long-Context LLMs
Sep 17, 2025Extending LLM context windows is crucial for long range tasks. RoPE-based position interpolation (PI) methods like linear and frequency-aware scaling extend input lengths without retraining, while post-training quantization (PTQ) enables practical deployment. We show that combining PI with PTQ degrades accuracy due to coupled effects long context aliasing, dynamic range dilation, axis grid anisotropy, and outlier shifting that induce position-dependent logit noise. We provide the first systematic analysis of PI plus PTQ and introduce two diagnostics: Interpolation Pressure (per-band phase scaling sensitivity) and Tail Inflation Ratios (outlier shift from short to long contexts). To address this, we propose Q-ROAR, a RoPE-aware, weight-only stabilization that groups RoPE dimensions into a few frequency bands and performs a small search over per-band scales for W_Q,W_K, with an optional symmetric variant to preserve logit scale. The diagnostics guided search uses a tiny long-context dev set and requires no fine-tuning, kernel, or architecture changes. Empirically, Q-ROAR recovers up to 0.7% accuracy on standard tasks and reduces GovReport perplexity by more than 10%, while preserving short-context performance and compatibility with existing inference stacks.
Characterizing State Space Model (SSM) and SSM-Transformer Hybrid Language Model Performance with Long Context Length
Jul 16, 2025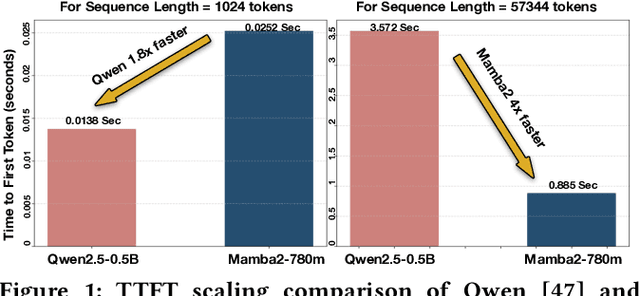

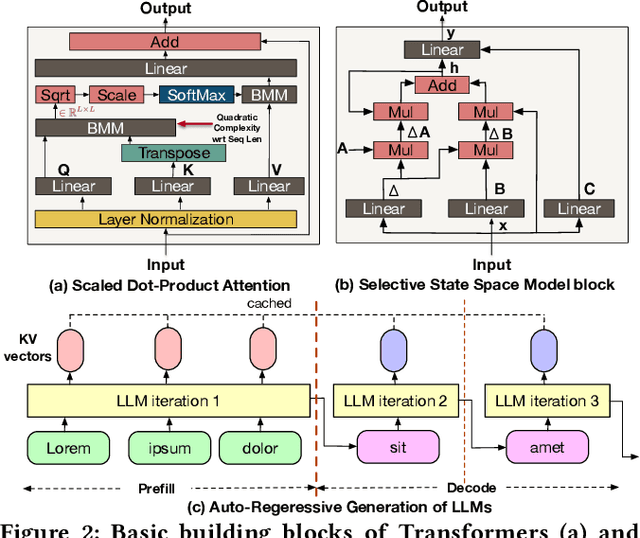
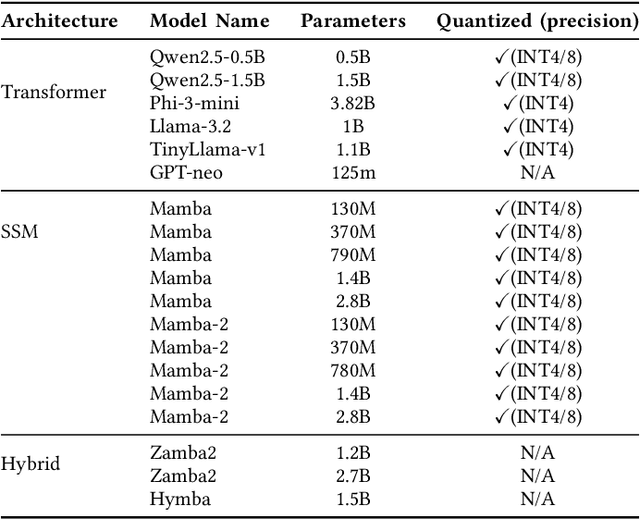
The demand for machine intelligence capable of processing continuous, long-context inputs on local devices is growing rapidly. However, the quadratic complexity and memory requirements of traditional Transformer architectures make them inefficient and often unusable for these tasks. This has spurred a paradigm shift towards new architectures like State Space Models (SSMs) and hybrids, which promise near-linear scaling. While most current research focuses on the accuracy and theoretical throughput of these models, a systematic performance characterization on practical consumer hardware is critically needed to guide system-level optimization and unlock new applications. To address this gap, we present a comprehensive, comparative benchmarking of carefully selected Transformer, SSM, and hybrid models specifically for long-context inference on consumer and embedded GPUs. Our analysis reveals that SSMs are not only viable but superior for this domain, capable of processing sequences up to 220K tokens on a 24GB consumer GPU-approximately 4x longer than comparable Transformers. While Transformers may be up to 1.8x faster at short sequences, SSMs demonstrate a dramatic performance inversion, becoming up to 4x faster at very long contexts (~57K tokens). Our operator-level analysis reveals that custom, hardware-aware SSM kernels dominate the inference runtime, accounting for over 55% of latency on edge platforms, identifying them as a primary target for future hardware acceleration. We also provide detailed, device-specific characterization results to guide system co-design for the edge. To foster further research, we will open-source our characterization framework.
TeLLMe: An Energy-Efficient Ternary LLM Accelerator for Prefilling and Decoding on Edge FPGAs
Apr 22, 2025Deploying large language models (LLMs) on edge platforms is challenged by their high computational and memory demands. Although recent low-bit quantization methods (e.g., BitNet, DeepSeek) compress weights to as little as 1.58 bits with minimal accuracy loss, edge deployment is still constrained by limited on-chip resources, power budgets, and the often-neglected latency of the prefill phase. We present TeLLMe, the first ternary LLM accelerator for low-power FPGAs (e.g., AMD KV260) that fully supports both prefill and autoregressive decoding using 1.58-bit weights and 8-bit activations. Our contributions include: (1) a table-lookup matrix engine for ternary matmul that merges grouped activations with online precomputation to minimize resource use; (2) a fused, bandwidth-efficient attention module featuring a reversed reordering scheme to accelerate prefill; and (3) a tightly integrated normalization and quantization--dequantization unit optimized for ultra-low-bit inference. Under a 7W power budget, TeLLMe delivers up to 9 tokens/s throughput over 1,024-token contexts and prefill latencies of 0.55--1.15 s for 64--128 token prompts, marking a significant energy-efficiency advance and establishing a new edge FPGA benchmark for generative AI.
COBRA: Algorithm-Architecture Co-optimized Binary Transformer Accelerator for Edge Inference
Apr 22, 2025



Transformer-based models have demonstrated superior performance in various fields, including natural language processing and computer vision. However, their enormous model size and high demands in computation, memory, and communication limit their deployment to edge platforms for local, secure inference. Binary transformers offer a compact, low-complexity solution for edge deployment with reduced bandwidth needs and acceptable accuracy. However, existing binary transformers perform inefficiently on current hardware due to the lack of binary specific optimizations. To address this, we introduce COBRA, an algorithm-architecture co-optimized binary Transformer accelerator for edge computing. COBRA features a real 1-bit binary multiplication unit, enabling matrix operations with -1, 0, and +1 values, surpassing ternary methods. With further hardware-friendly optimizations in the attention block, COBRA achieves up to 3,894.7 GOPS throughput and 448.7 GOPS/Watt energy efficiency on edge FPGAs, delivering a 311x energy efficiency improvement over GPUs and a 3.5x throughput improvement over the state-of-the-art binary accelerator, with only negligible inference accuracy degradation.
MONAS: Efficient Zero-Shot Neural Architecture Search for MCUs
Aug 26, 2024



Neural Architecture Search (NAS) has proven effective in discovering new Convolutional Neural Network (CNN) architectures, particularly for scenarios with well-defined accuracy optimization goals. However, previous approaches often involve time-consuming training on super networks or intensive architecture sampling and evaluations. Although various zero-cost proxies correlated with CNN model accuracy have been proposed for efficient architecture search without training, their lack of hardware consideration makes it challenging to target highly resource-constrained edge devices such as microcontroller units (MCUs). To address these challenges, we introduce MONAS, a novel hardware-aware zero-shot NAS framework specifically designed for MCUs in edge computing. MONAS incorporates hardware optimality considerations into the search process through our proposed MCU hardware latency estimation model. By combining this with specialized performance indicators (proxies), MONAS identifies optimal neural architectures without incurring heavy training and evaluation costs, optimizing for both hardware latency and accuracy under resource constraints. MONAS achieves up to a 1104x improvement in search efficiency over previous work targeting MCUs and can discover CNN models with over 3.23x faster inference on MCUs while maintaining similar accuracy compared to more general NAS approaches.
TBA: Faster Large Language Model Training Using SSD-Based Activation Offloading
Aug 19, 2024



The growth rate of the GPU memory capacity has not been able to keep up with that of the size of large language models (LLMs), hindering the model training process. In particular, activations -- the intermediate tensors produced during forward propagation and reused in backward propagation -- dominate the GPU memory use. To address this challenge, we propose TBA to efficiently offload activations to high-capacity NVMe SSDs. This approach reduces GPU memory usage without impacting performance by adaptively overlapping data transfers with computation. TBA is compatible with popular deep learning frameworks like PyTorch, Megatron, and DeepSpeed, and it employs techniques such as tensor deduplication, forwarding, and adaptive offloading to further enhance efficiency. We conduct extensive experiments on GPT, BERT, and T5. Results demonstrate that TBA effectively reduces 47% of the activation peak memory usage. At the same time, TBA perfectly overlaps the I/O with the computation and incurs negligible performance overhead. We introduce the recompute-offload-keep (ROK) curve to compare the TBA offloading with other two tensor placement strategies, keeping activations in memory and layerwise full recomputation. We find that TBA achieves better memory savings than layerwise full recomputation while retaining the performance of keeping the activations in memory.
RSEND: Retinex-based Squeeze and Excitation Network with Dark Region Detection for Efficient Low Light Image Enhancement
Jun 14, 2024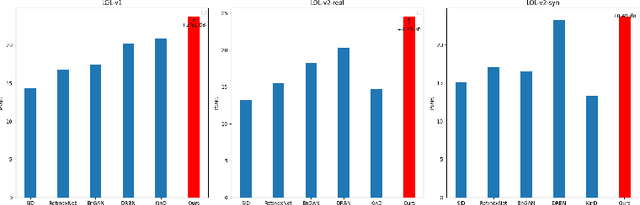
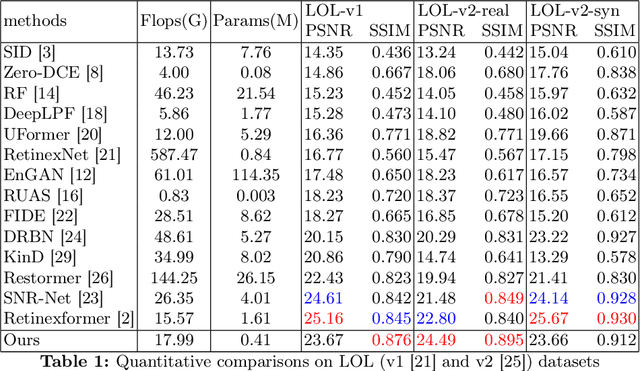
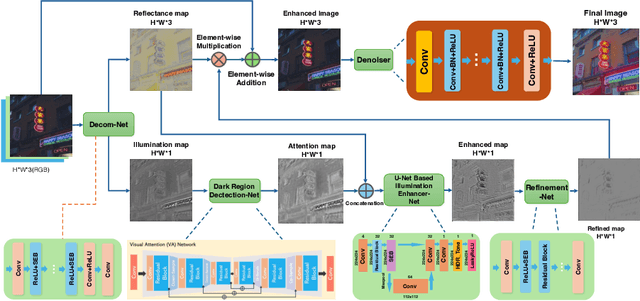

Images captured under low-light scenarios often suffer from low quality. Previous CNN-based deep learning methods often involve using Retinex theory. Nevertheless, most of them cannot perform well in more complicated datasets like LOL-v2 while consuming too much computational resources. Besides, some of these methods require sophisticated training at different stages, making the procedure even more time-consuming and tedious. In this paper, we propose a more accurate, concise, and one-stage Retinex theory based framework, RSEND. RSEND first divides the low-light image into the illumination map and reflectance map, then captures the important details in the illumination map and performs light enhancement. After this step, it refines the enhanced gray-scale image and does element-wise matrix multiplication with the reflectance map. By denoising the output it has from the previous step, it obtains the final result. In all the steps, RSEND utilizes Squeeze and Excitation network to better capture the details. Comprehensive quantitative and qualitative experiments show that our Efficient Retinex model significantly outperforms other CNN-based models, achieving a PSNR improvement ranging from 0.44 dB to 4.2 dB in different datasets and even outperforms transformer-based models in the LOL-v2-real dataset.
TG-NAS: Leveraging Zero-Cost Proxies with Transformer and Graph Convolution Networks for Efficient Neural Architecture Search
Mar 30, 2024Neural architecture search (NAS) is an effective method for discovering new convolutional neural network (CNN) architectures. However, existing approaches often require time-consuming training or intensive sampling and evaluations. Zero-shot NAS aims to create training-free proxies for architecture performance prediction. However, existing proxies have suboptimal performance, and are often outperformed by simple metrics such as model parameter counts or the number of floating-point operations. Besides, existing model-based proxies cannot be generalized to new search spaces with unseen new types of operators without golden accuracy truth. A universally optimal proxy remains elusive. We introduce TG-NAS, a novel model-based universal proxy that leverages a transformer-based operator embedding generator and a graph convolution network (GCN) to predict architecture performance. This approach guides neural architecture search across any given search space without the need of retraining. Distinct from other model-based predictor subroutines, TG-NAS itself acts as a zero-cost (ZC) proxy, guiding architecture search with advantages in terms of data independence, cost-effectiveness, and consistency across diverse search spaces. Our experiments showcase its advantages over existing proxies across various NAS benchmarks, suggesting its potential as a foundational element for efficient architecture search. TG-NAS achieves up to 300X improvements in search efficiency compared to previous SOTA ZC proxy methods. Notably, it discovers competitive models with 93.75% CIFAR-10 accuracy on the NAS-Bench-201 space and 74.5% ImageNet top-1 accuracy on the DARTS space.
MicroNAS: Zero-Shot Neural Architecture Search for MCUs
Jan 17, 2024Neural Architecture Search (NAS) effectively discovers new Convolutional Neural Network (CNN) architectures, particularly for accuracy optimization. However, prior approaches often require resource-intensive training on super networks or extensive architecture evaluations, limiting practical applications. To address these challenges, we propose MicroNAS, a hardware-aware zero-shot NAS framework designed for microcontroller units (MCUs) in edge computing. MicroNAS considers target hardware optimality during the search, utilizing specialized performance indicators to identify optimal neural architectures without high computational costs. Compared to previous works, MicroNAS achieves up to 1104x improvement in search efficiency and discovers models with over 3.23x faster MCU inference while maintaining similar accuracy
CARMA: Context-Aware Runtime Reconfiguration for Energy-Efficient Sensor Fusion
Jun 27, 2023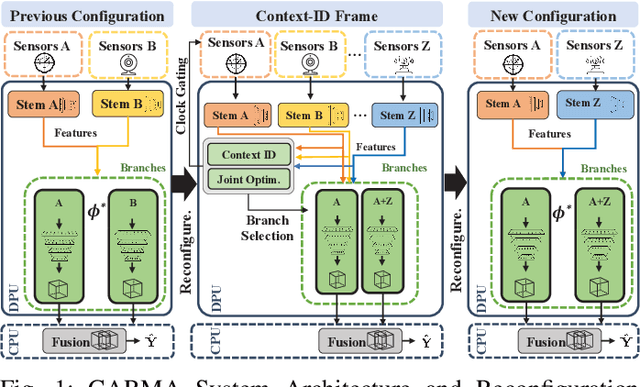
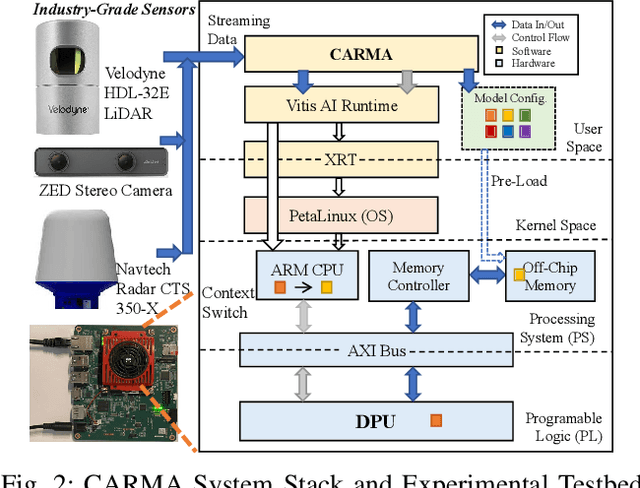
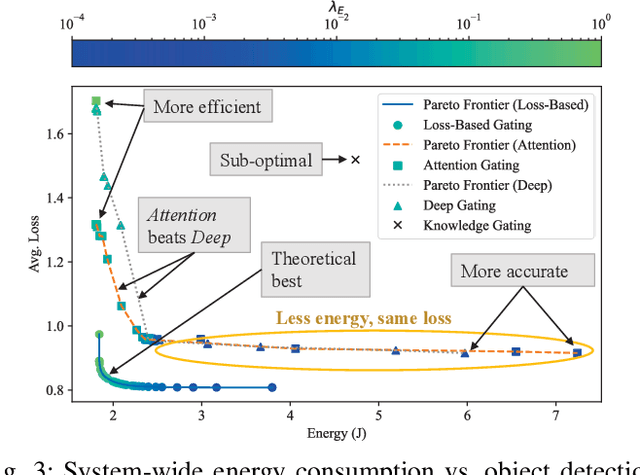
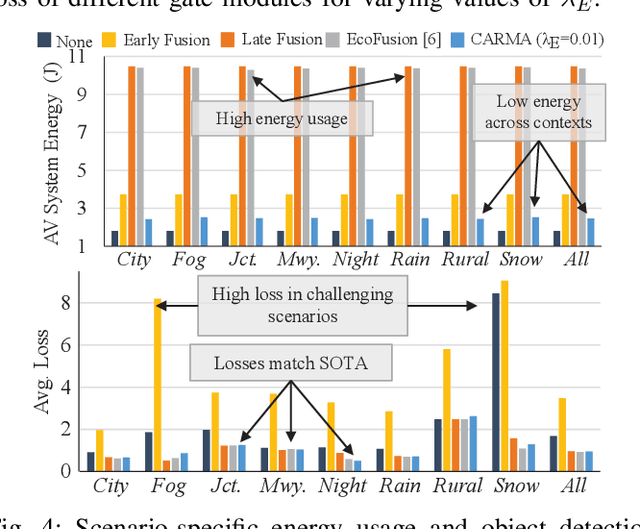
Autonomous systems (AS) are systems that can adapt and change their behavior in response to unanticipated events and include systems such as aerial drones, autonomous vehicles, and ground/aquatic robots. AS require a wide array of sensors, deep-learning models, and powerful hardware platforms to perceive and safely operate in real-time. However, in many contexts, some sensing modalities negatively impact perception while increasing the system's overall energy consumption. Since AS are often energy-constrained edge devices, energy-efficient sensor fusion methods have been proposed. However, existing methods either fail to adapt to changing scenario conditions or to optimize energy efficiency system-wide. We propose CARMA: a context-aware sensor fusion approach that uses context to dynamically reconfigure the computation flow on a Field-Programmable Gate Array (FPGA) at runtime. By clock-gating unused sensors and model sub-components, CARMA significantly reduces the energy used by a multi-sensory object detector without compromising performance. We use a Deep-learning Processor Unit (DPU) based reconfiguration approach to minimize the latency of model reconfiguration. We evaluate multiple context-identification strategies, propose a novel system-wide energy-performance joint optimization, and evaluate scenario-specific perception performance. Across challenging real-world sensing contexts, CARMA outperforms state-of-the-art methods with up to 1.3x speedup and 73% lower energy consumption.