 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARMA: Context-Aware Runtime Reconfiguration for Energy-Efficient Sensor Fusion
Jun 27, 2023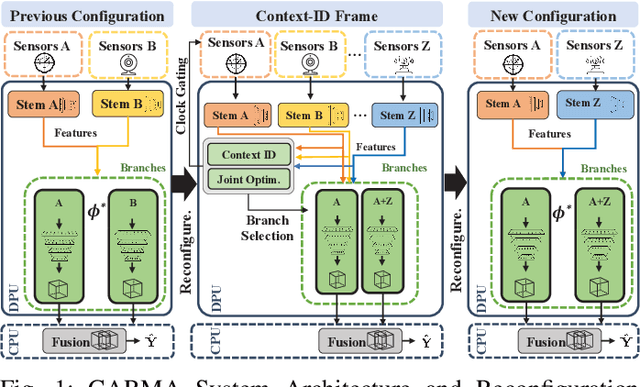
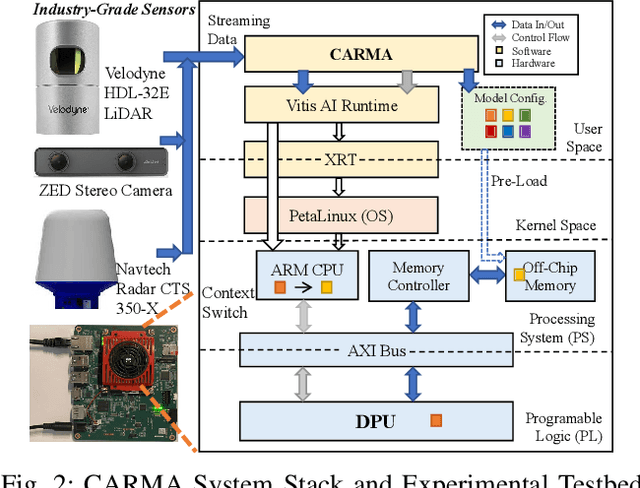
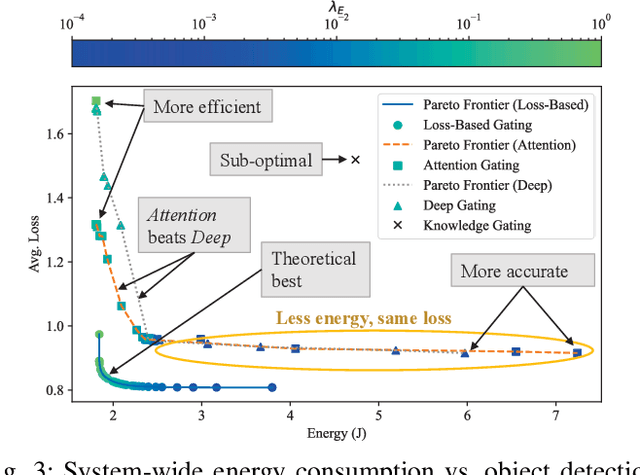
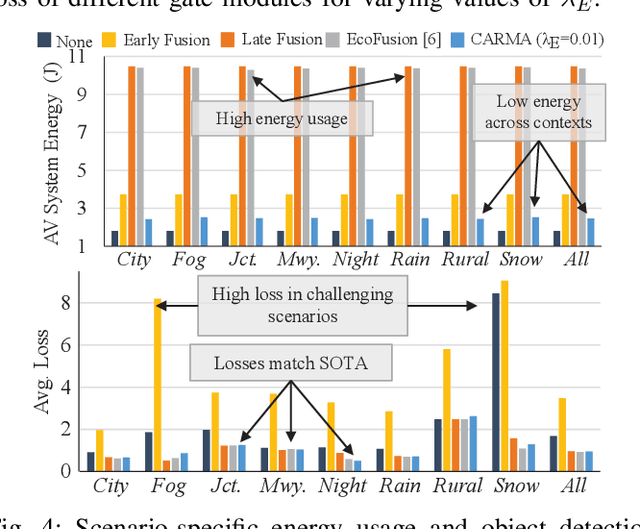
Autonomous systems (AS) are systems that can adapt and change their behavior in response to unanticipated events and include systems such as aerial drones, autonomous vehicles, and ground/aquatic robots. AS require a wide array of sensors, deep-learning models, and powerful hardware platforms to perceive and safely operate in real-time. However, in many contexts, some sensing modalities negatively impact perception while increasing the system's overall energy consumption. Since AS are often energy-constrained edge devices, energy-efficient sensor fusion methods have been proposed. However, existing methods either fail to adapt to changing scenario conditions or to optimize energy efficiency system-wide. We propose CARMA: a context-aware sensor fusion approach that uses context to dynamically reconfigure the computation flow on a Field-Programmable Gate Array (FPGA) at runtime. By clock-gating unused sensors and model sub-components, CARMA significantly reduces the energy used by a multi-sensory object detector without compromising performance. We use a Deep-learning Processor Unit (DPU) based reconfiguration approach to minimize the latency of model reconfiguration. We evaluate multiple context-identification strategies, propose a novel system-wide energy-performance joint optimization, and evaluate scenario-specific perception performance. Across challenging real-world sensing contexts, CARMA outperforms state-of-the-art methods with up to 1.3x speedup and 73% lower energy consumption.
RS2G: Data-Driven Scene-Graph Extraction and Embedding for Robust Autonomous Perception and Scenario Understanding
Apr 17, 2023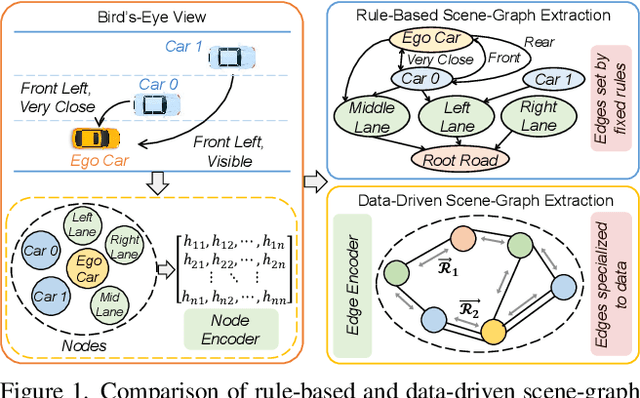
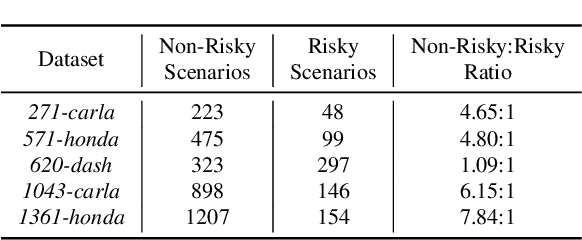
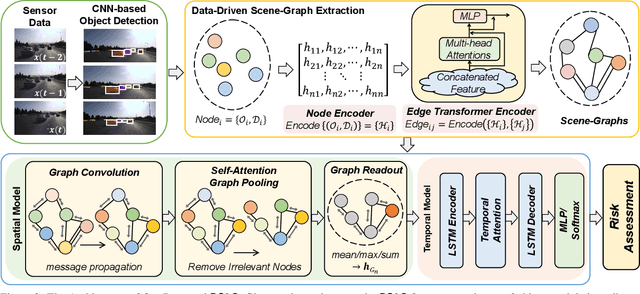
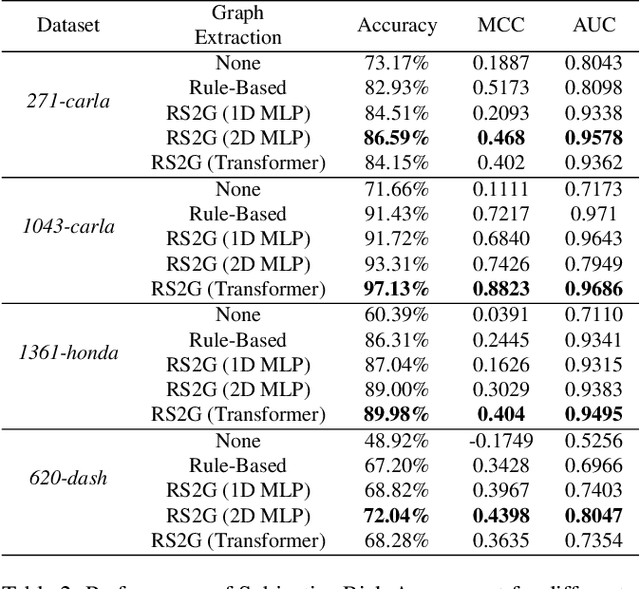
Human drivers naturally reason about interactions between road users to understand and safely navigate through traffic. Thus, developing autonomous vehicles necessitates the ability to mimic such knowledge and model interactions between road users to understand and navigate unpredictable, dynamic environments. However, since real-world scenarios often differ from training datasets, effectively modeling the behavior of various road users in an environment remains a significant research challenge. This reality necessitates models that generalize to a broad range of domains and explicitly model interactions between road users and the environment to improve scenario understanding. Graph learning methods address this problem by modeling interactions using graph representations of scenarios. However, existing methods cannot effectively transfer knowledge gained from the training domain to real-world scenarios. This constraint is caused by the domain-specific rules used for graph extraction that can vary in effectiveness across domains, limiting generalization ability. To address these limitations, we propose RoadScene2Graph (RS2G): a data-driven graph extraction and modeling approach that learns to extract the best graph representation of a road scene for solving autonomous scene understanding tasks. We show that RS2G enables better performance at subjective risk assessment than rule-based graph extraction methods and deep-learning-based models. RS2G also improves generalization and Sim2Real transfer learning, which denotes the ability to transfer knowledge gained from simulation datasets to unseen real-world scenarios. We also present ablation studies showing how RS2G produces a more useful graph representation for downstream classifiers. Finally, we show how RS2G can identify the relative importance of rule-based graph edges and enables intelligent graph sparsity tuning.
EcoFusion: Energy-Aware Adaptive Sensor Fusion for Efficient Autonomous Vehicle Perception
Feb 23, 2022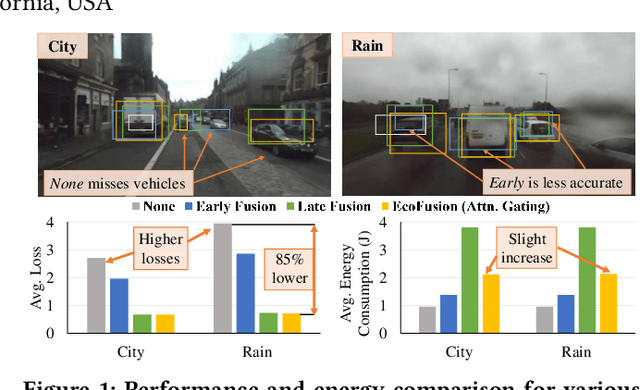
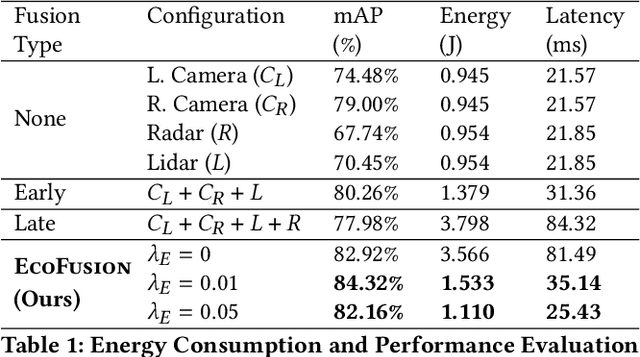
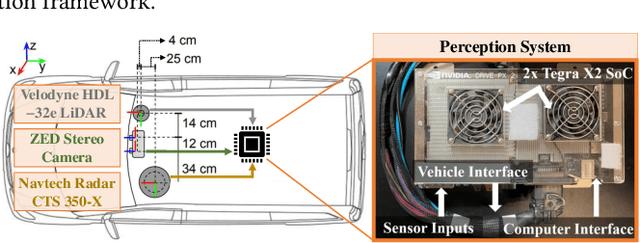
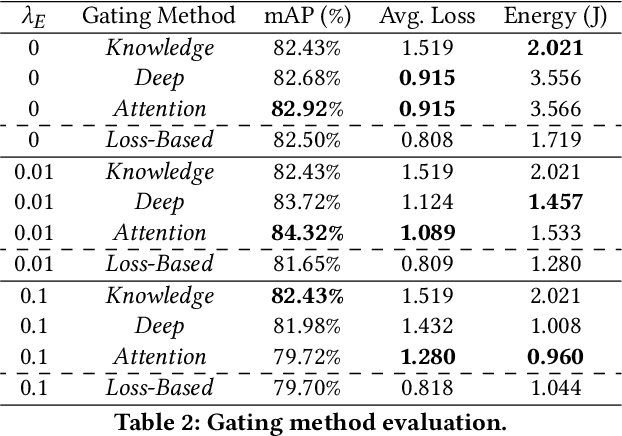
Autonomous vehicles use multiple sensors, large deep-learning models, and powerful hardware platforms to perceive the environment and navigate safely. In many contexts, some sensing modalities negatively impact perception while increasing energy consumption. We propose EcoFusion: an energy-aware sensor fusion approach that uses context to adapt the fusion method and reduce energy consumption without affecting perception performance. EcoFusion performs up to 9.5% better at object detection than existing fusion methods with approximately 60% less energy and 58% lower latency on the industry-standard Nvidia Drive PX2 hardware platform. We also propose several context-identification strategies, implement a joint optimization between energy and performance, and present scenario-specific results.
HydraFusion: Context-Aware Selective Sensor Fusion for Robust and Efficient Autonomous Vehicle Perception
Jan 17, 2022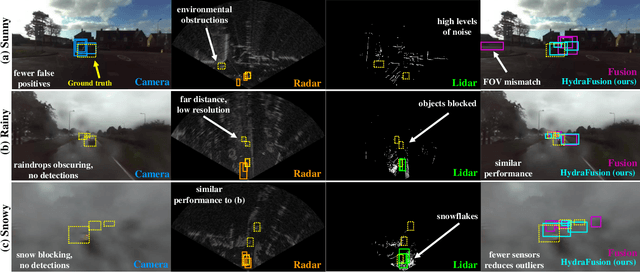
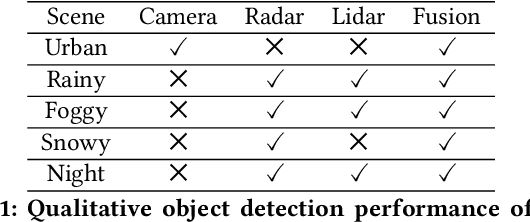

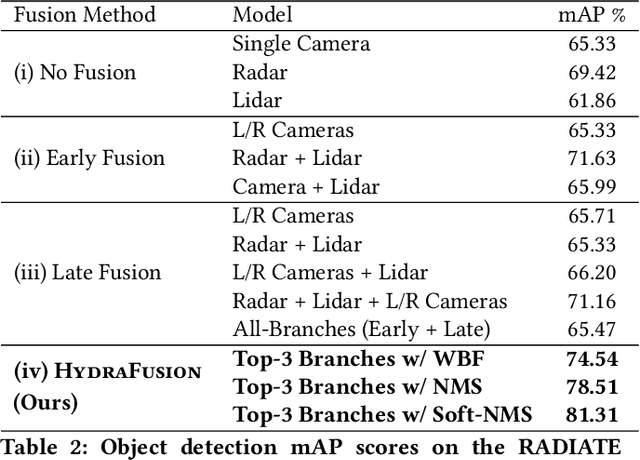
Although autonomous vehicles (AVs) are expected to revolutionize transportation, robust perception across a wide range of driving contexts remains a significant challenge. Techniques to fuse sensor data from camera, radar, and lidar sensors have been proposed to improve AV perception. However, existing methods are insufficiently robust in difficult driving contexts (e.g., bad weather, low light, sensor obstruction) due to rigidity in their fusion implementations. These methods fall into two broad categories: (i) early fusion, which fails when sensor data is noisy or obscured, and (ii) late fusion, which cannot leverage features from multiple sensors and thus produces worse estimates. To address these limitations, we propose HydraFusion: a selective sensor fusion framework that learns to identify the current driving context and fuses the best combination of sensors to maximize robustness without compromising efficiency. HydraFusion is the first approach to propose dynamically adjusting between early fusion, late fusion, and combinations in-between, thus varying both how and when fusion is applied. We show that, on average, HydraFusion outperforms early and late fusion approaches by 13.66% and 14.54%, respectively, without increasing computational complexity or energy consumption on the industry-standard Nvidia Drive PX2 AV hardware platform. We also propose and evaluate both static and deep-learning-based context identification strategies. Our open-source code and model implementation are available at https://github.com/AICPS/hydrafusion.
roadscene2vec: A Tool for Extracting and Embedding Road Scene-Graphs
Sep 02, 2021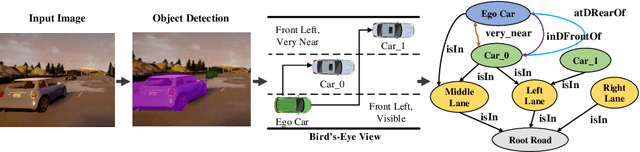
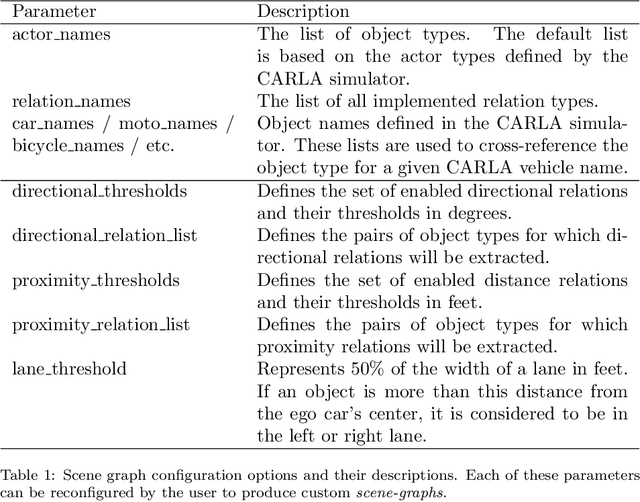
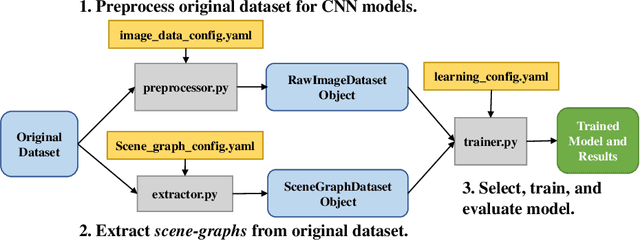
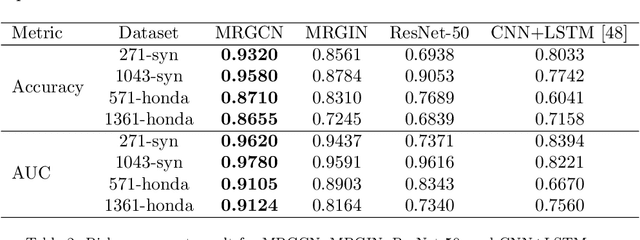
Recently, road scene-graph representations used in conjunction with graph learning techniques have been shown to outperform state-of-the-art deep learning techniques in tasks including action classification, risk assessment, and collision prediction. To enable the exploration of applications of road scene-graph representations, we introduce roadscene2vec: an open-source tool for extracting and embedding road scene-graphs. The goal of roadscene2vec is to enable research into the applications and capabilities of road scene-graphs by providing tools for generating scene-graphs, graph learning models to generate spatio-temporal scene-graph embeddings, and tools for visualizing and analyzing scene-graph-based methodologies. The capabilities of roadscene2vec include (i) customized scene-graph generation from either video clips or data from the CARLA simulator, (ii) multiple configurable spatio-temporal graph embedding models and baseline CNN-based models, (iii) built-in functionality for using graph and sequence embeddings for risk assessment and collision prediction applications, (iv) tools for evaluating transfer learning, and (v) utilities for visualizing scene-graphs and analyzing the explainability of graph learning models. We demonstrate the utility of roadscene2vec for these use cases with experimental results and qualitative evaluations for both graph learning models and CNN-based models. roadscene2vec is available at https://github.com/AICPS/roadscene2vec.