 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the PLC Binary Analysis Gap: A Cross-Compiler Dataset and Neural Framework for Industrial Control Systems
Feb 27, 2025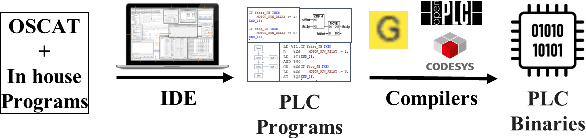
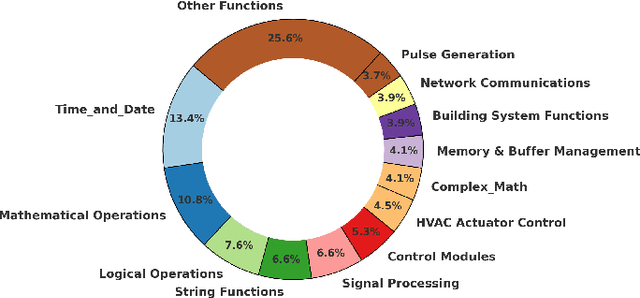
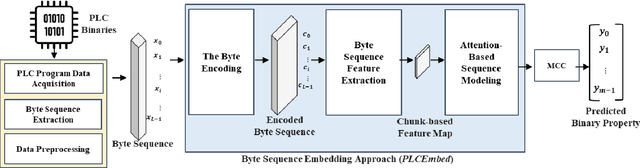
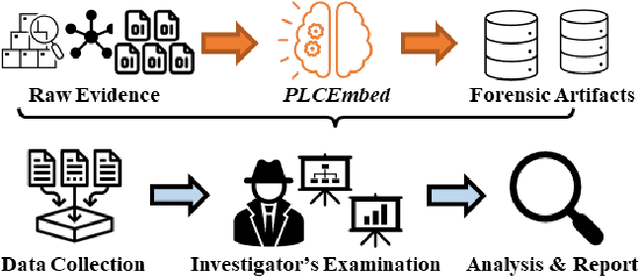
Industrial Control Systems (ICS) rely heavily on Programmable Logic Controllers (PLCs) to manage critical infrastructure, yet analyzing PLC executables remains challenging due to diverse proprietary compilers and limited access to source code. To bridge this gap, we introduce PLC-BEAD, a comprehensive dataset containing 2431 compiled binaries from 700+ PLC programs across four major industrial compilers (CoDeSys, GEB, OpenPLC-V2, OpenPLC-V3). This novel dataset uniquely pairs each binary with its original Structured Text source code and standardized functionality labels, enabling both binary-level and source-level analysis. We demonstrate the dataset's utility through PLCEmbed, a transformer-based framework for binary code analysis that achieves 93\% accuracy in compiler provenance identification and 42\% accuracy in fine-grained functionality classification across 22 industrial control categories. Through comprehensive ablation studies, we analyze how compiler optimization levels, code patterns, and class distributions influence model performance. We provide detailed documentation of the dataset creation process, labeling taxonomy, and benchmark protocols to ensure reproducibility. Both PLC-BEAD and PLCEmbed are released as open-source resources to foster research in PLC security, reverse engineering, and ICS forensics, establishing new baselines for data-driven approaches to industrial cybersecurity.
RS2G: Data-Driven Scene-Graph Extraction and Embedding for Robust Autonomous Perception and Scenario Understanding
Apr 17, 2023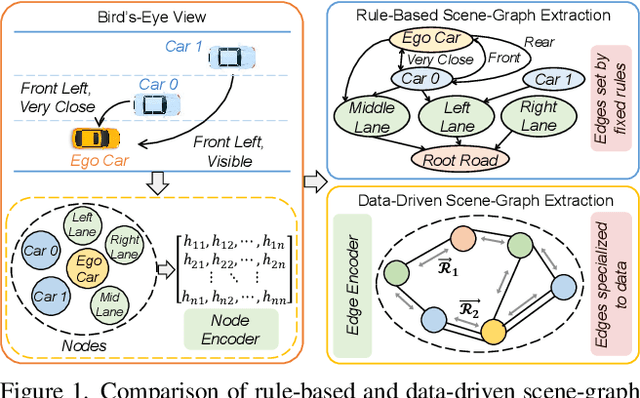
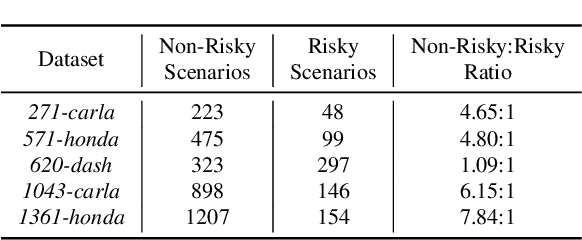
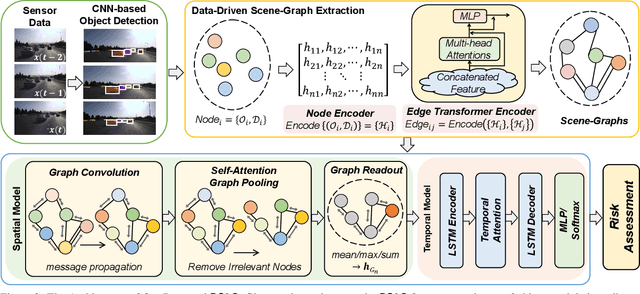
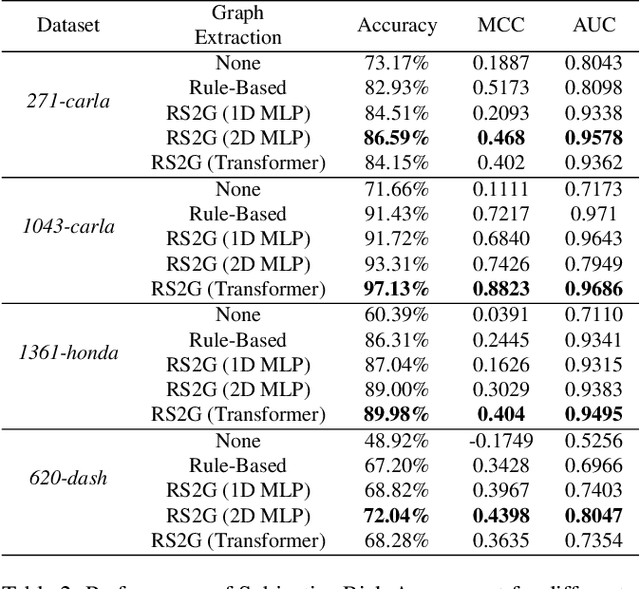
Human drivers naturally reason about interactions between road users to understand and safely navigate through traffic. Thus, developing autonomous vehicles necessitates the ability to mimic such knowledge and model interactions between road users to understand and navigate unpredictable, dynamic environments. However, since real-world scenarios often differ from training datasets, effectively modeling the behavior of various road users in an environment remains a significant research challenge. This reality necessitates models that generalize to a broad range of domains and explicitly model interactions between road users and the environment to improve scenario understanding. Graph learning methods address this problem by modeling interactions using graph representations of scenarios. However, existing methods cannot effectively transfer knowledge gained from the training domain to real-world scenarios. This constraint is caused by the domain-specific rules used for graph extraction that can vary in effectiveness across domains, limiting generalization ability. To address these limitations, we propose RoadScene2Graph (RS2G): a data-driven graph extraction and modeling approach that learns to extract the best graph representation of a road scene for solving autonomous scene understanding tasks. We show that RS2G enables better performance at subjective risk assessment than rule-based graph extraction methods and deep-learning-based models. RS2G also improves generalization and Sim2Real transfer learning, which denotes the ability to transfer knowledge gained from simulation datasets to unseen real-world scenarios. We also present ablation studies showing how RS2G produces a more useful graph representation for downstream classifiers. Finally, we show how RS2G can identify the relative importance of rule-based graph edges and enables intelligent graph sparsity tuning.
Spatio-Temporal Scene-Graph Embedding for Autonomous Vehicle Collision Prediction
Nov 11, 2021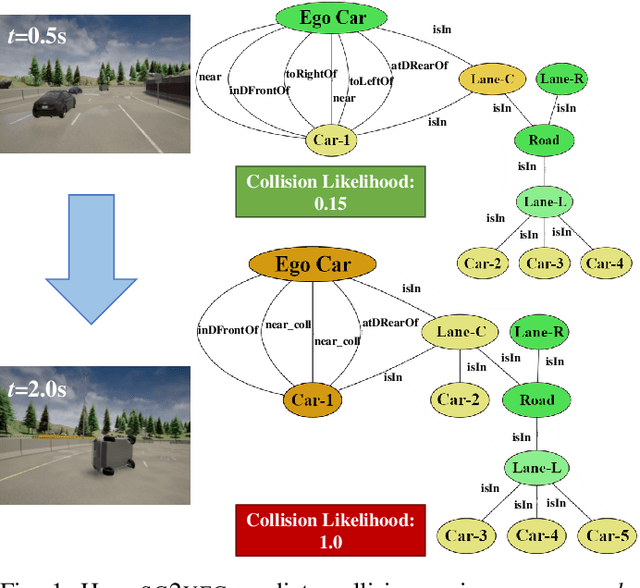
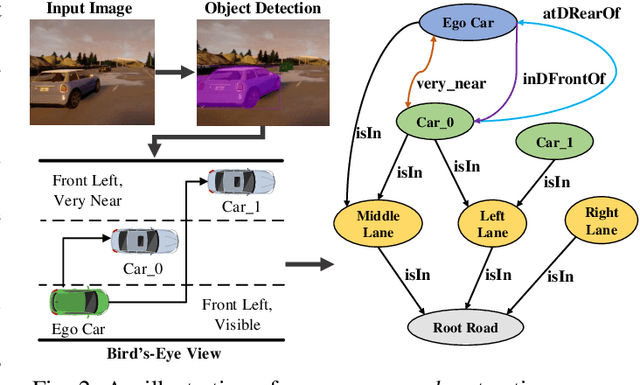
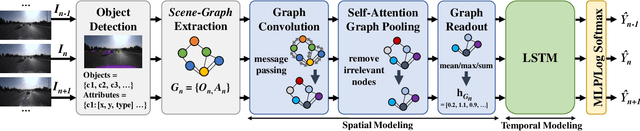

In autonomous vehicles (AVs), early warning systems rely on collision prediction to ensure occupant safety. However, state-of-the-art methods using deep convolutional networks either fail at modeling collisions or are too expensive/slow, making them less suitable for deployment on AV edge hardware. To address these limitations, we propose sg2vec, a spatio-temporal scene-graph embedding methodology that uses Graph Neural Network (GNN) and Long Short-Term Memory (LSTM) layers to predict future collisions via visual scene perception. We demonstrate that sg2vec predicts collisions 8.11% more accurately and 39.07% earlier than the state-of-the-art method on synthesized datasets, and 29.47% more accurately on a challenging real-world collision dataset. We also show that sg2vec is better than the state-of-the-art at transferring knowledge from synthetic datasets to real-world driving datasets. Finally, we demonstrate that sg2vec performs inference 9.3x faster with an 88.0% smaller model, 32.4% less power, and 92.8% less energy than the state-of-the-art method on the industry-standard Nvidia DRIVE PX 2 platform, making it more suitable for implementation on the edge.
Graph Learning for Cognitive Digital Twins in Manufacturing Systems
Sep 17, 2021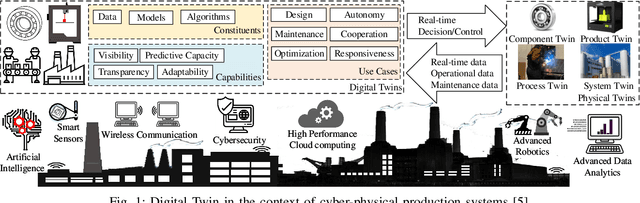
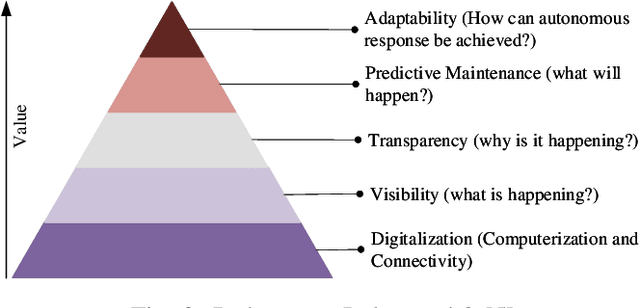
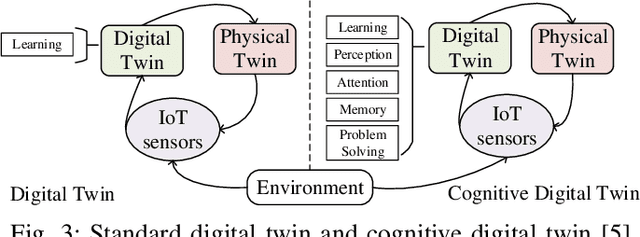
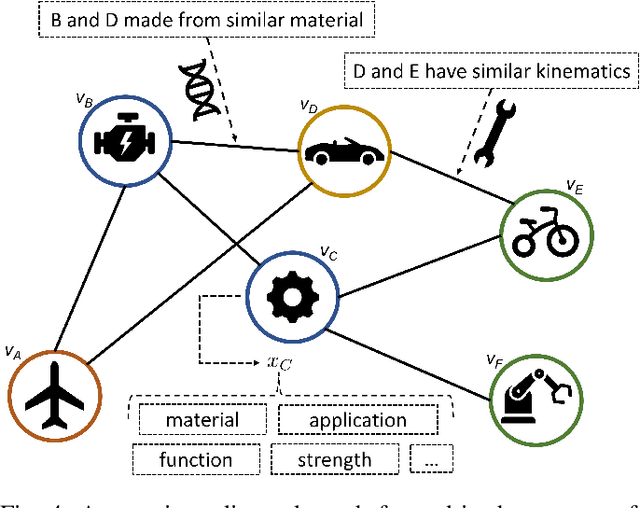
Future manufacturing requires complex systems that connect simulation platforms and virtualization with physical data from industrial processes. Digital twins incorporate a physical twin, a digital twin, and the connection between the two. Benefits of using digital twins, especially in manufacturing, are abundant as they can increase efficiency across an entire manufacturing life-cycle. The digital twin concept has become increasingly sophisticated and capable over time, enabled by rises in many technologies. In this paper, we detail the cognitive digital twin as the next stage of advancement of a digital twin that will help realize the vision of Industry 4.0. Cognitive digital twins will allow enterprises to creatively, effectively, and efficiently exploit implicit knowledge drawn from the experience of existing manufacturing systems. They also enable more autonomous decisions and control, while improving the performance across the enterprise (at scale). This paper presents graph learning as one potential pathway towards enabling cognitive functionalities in manufacturing digital twins. A novel approach to realize cognitive digital twins in the product design stage of manufacturing that utilizes graph learning is presented.
roadscene2vec: A Tool for Extracting and Embedding Road Scene-Graphs
Sep 02, 2021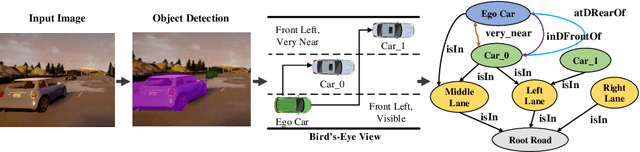
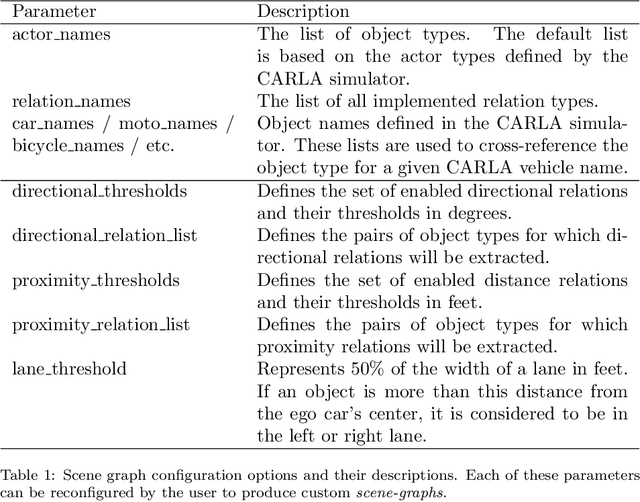
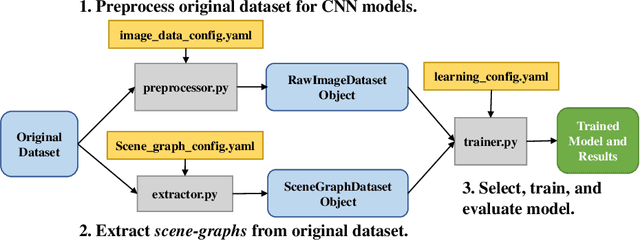
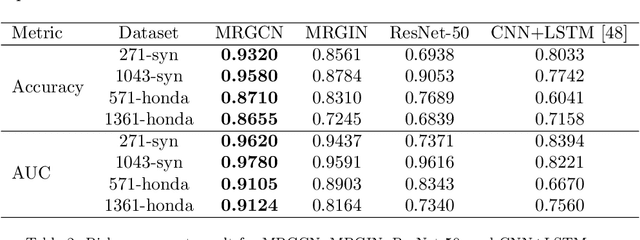
Recently, road scene-graph representations used in conjunction with graph learning techniques have been shown to outperform state-of-the-art deep learning techniques in tasks including action classification, risk assessment, and collision prediction. To enable the exploration of applications of road scene-graph representations, we introduce roadscene2vec: an open-source tool for extracting and embedding road scene-graphs. The goal of roadscene2vec is to enable research into the applications and capabilities of road scene-graphs by providing tools for generating scene-graphs, graph learning models to generate spatio-temporal scene-graph embeddings, and tools for visualizing and analyzing scene-graph-based methodologies. The capabilities of roadscene2vec include (i) customized scene-graph generation from either video clips or data from the CARLA simulator, (ii) multiple configurable spatio-temporal graph embedding models and baseline CNN-based models, (iii) built-in functionality for using graph and sequence embeddings for risk assessment and collision prediction applications, (iv) tools for evaluating transfer learning, and (v) utilities for visualizing scene-graphs and analyzing the explainability of graph learning models. We demonstrate the utility of roadscene2vec for these use cases with experimental results and qualitative evaluations for both graph learning models and CNN-based models. roadscene2vec is available at https://github.com/AICPS/roadscene2vec.
HW2VEC: A Graph Learning Tool for Automating Hardware Security
Jul 26, 2021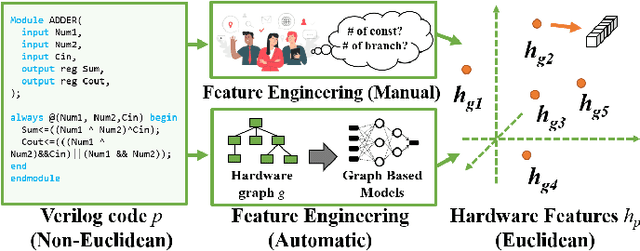
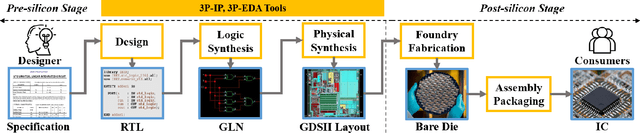
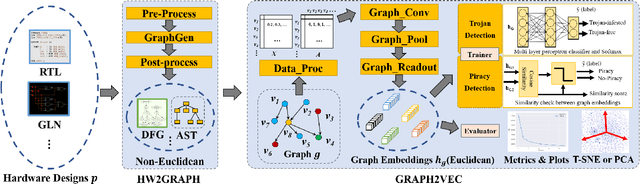
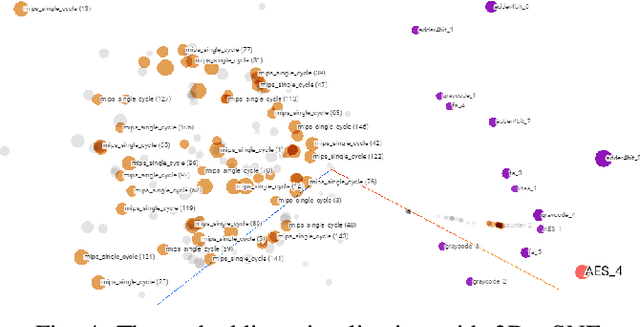
The time-to-market pressure and continuous growing complexity of hardware designs have promoted the globalization of the Integrated Circuit (IC) supply chain. However, such globalization also poses various security threats in each phase of the IC supply chain. Although the advancements of Machine Learning (ML) have pushed the frontier of hardware security, most conventional ML-based methods can only achieve the desired performance by manually finding a robust feature representation for circuits that are non-Euclidean data. As a result, modeling these circuits using graph learning to improve design flows has attracted research attention in the Electronic Design Automation (EDA) field. However, due to the lack of supporting tools, only a few existing works apply graph learning to resolve hardware security issues. To attract more attention, we propose HW2VEC, an open-source graph learning tool that lowers the threshold for newcomers to research hardware security applications with graphs. HW2VEC provides an automated pipeline for extracting a graph representation from a hardware design in various abstraction levels (register transfer level or gate-level netlist). Besides, HW2VEC users can automatically transform the non-Euclidean hardware designs into Euclidean graph embeddings for solving their problems. In this paper, we demonstrate that HW2VEC can achieve state-of-the-art performance on two hardware security-related tasks: Hardware Trojan Detection and Intellectual Property Piracy Detection. We provide the time profiling results for the graph extraction and the learning pipelines in HW2VEC.
GNN4IP: Graph Neural Network for Hardware Intellectual Property Piracy Detection
Jul 19, 2021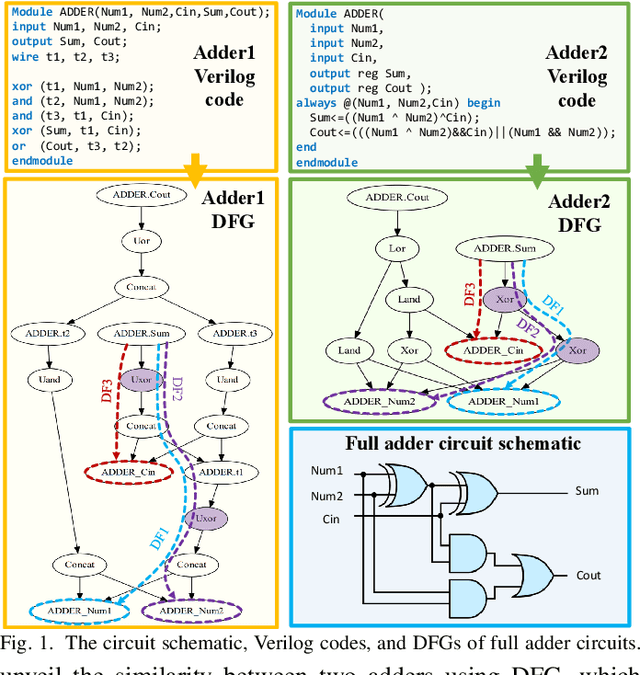
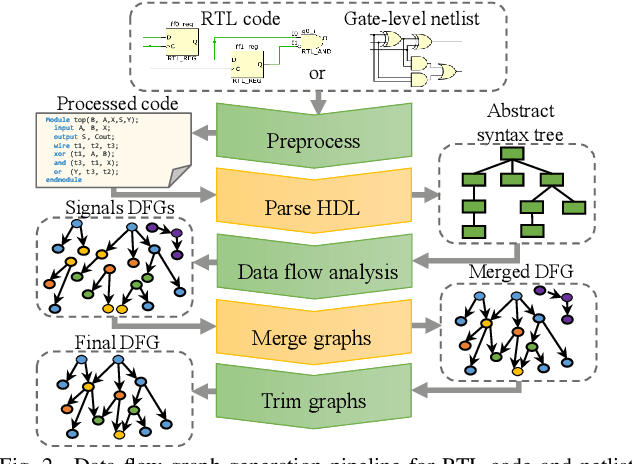
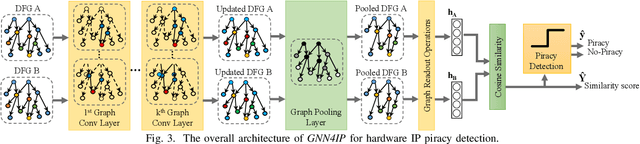
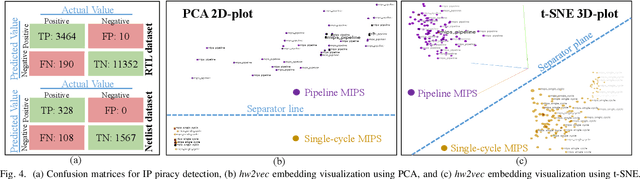
Aggressive time-to-market constraints and enormous hardware design and fabrication costs have pushed the semiconductor industry toward hardware Intellectual Properties (IP) core design. However, the globalization of the integrated circuits (IC) supply chain exposes IP providers to theft and illegal redistribution of IPs. Watermarking and fingerprinting are proposed to detect IP piracy. Nevertheless, they come with additional hardware overhead and cannot guarantee IP security as advanced attacks are reported to remove the watermark, forge, or bypass it. In this work, we propose a novel methodology, GNN4IP, to assess similarities between circuits and detect IP piracy. We model the hardware design as a graph and construct a graph neural network model to learn its behavior using the comprehensive dataset of register transfer level codes and gate-level netlists that we have gathered. GNN4IP detects IP piracy with 96% accuracy in our dataset and recognizes the original IP in its obfuscated version with 100% accuracy.
Scene-Graph Augmented Data-Driven Risk Assessment of Autonomous Vehicle Decisions
Aug 31, 2020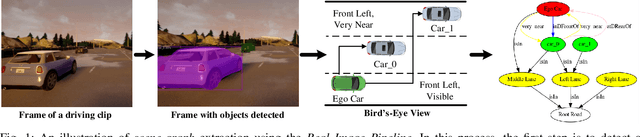
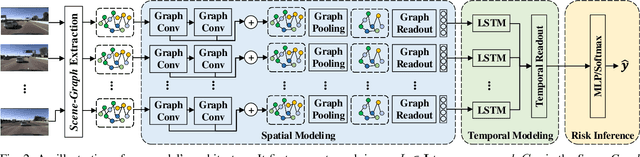
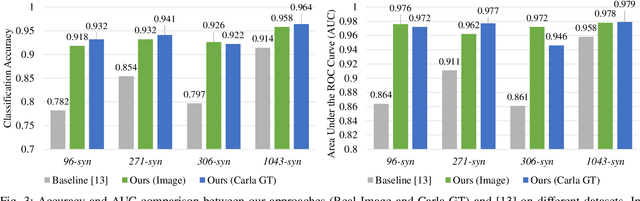
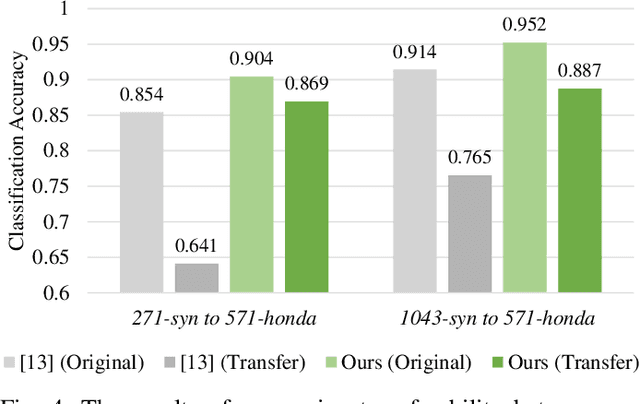
Despite impressive advancements in Autonomous Driving Systems (ADS), navigation in complex road conditions remains a challenging problem. There is considerable evidence that evaluating the subjective risk level of various decisions can improve ADS' safety in both normal and complex driving scenarios. However, existing deep learning-based methods often fail to model the relationships between traffic participants and can suffer when faced with complex real-world scenarios. Besides, these methods lack transferability and explainability. To address these limitations, we propose a novel data-driven approach that uses scene-graphs as intermediate representations. Our approach includes a Multi-Relation Graph Convolution Network, a Long-Short Term Memory Network, and attention layers for modeling the subjective risk of driving maneuvers. To train our model, we formulate this task as a supervised scene classification problem. We consider a typical use case to demonstrate our model's capabilities: lane changes. We show that our approach achieves a higher classification accuracy than the state-of-the-art approach on both large (96.4% vs. 91.2%) and small (91.8% vs. 71.2%) synthesized datasets, also illustrating that our approach can learn effectively even from smaller datasets. We also show that our model trained on a synthesized dataset achieves an average accuracy of 87.8% when tested on a real-world dataset compared to the 70.3% accuracy achieved by the state-of-the-art model trained on the same synthesized dataset, showing that our approach can more effectively transfer knowledge. Finally, we demonstrate that the use of spatial and temporal attention layers improves our model's performance by 2.7% and 0.7% respectively, and increases its explainability.