 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-term Fairness For Real-time Decision Making: A Constrained Online Optimization Approach
Jan 04, 2024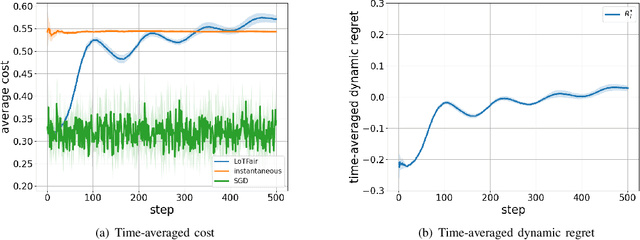
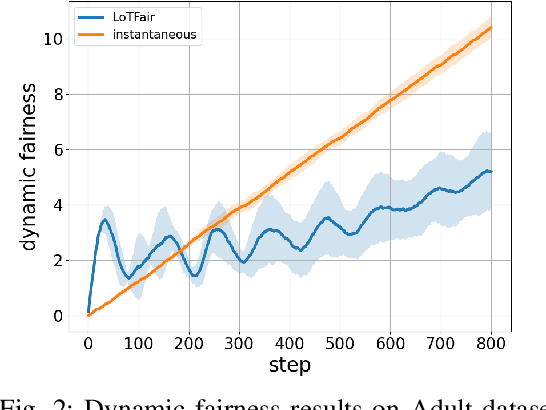
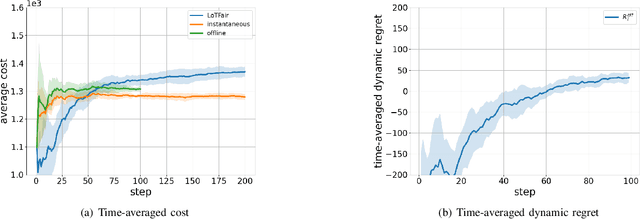
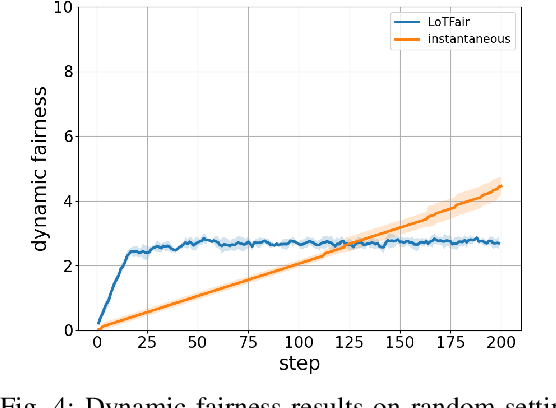
Machine learning (ML) has demonstrated remarkable capabilities across many real-world systems, from predictive modeling to intelligent automation. However, the widespread integration of machine learning also makes it necessary to ensure machine learning-driven decision-making systems do not violate ethical principles and values of society in which they operate. As ML-driven decisions proliferate, particularly in cases involving sensitive attributes such as gender, race, and age, to name a few, the need for equity and impartiality has emerged as a fundamental concern. In situations demanding real-time decision-making, fairness objectives become more nuanced and complex: instantaneous fairness to ensure equity in every time slot, and long-term fairness to ensure fairness over a period of time. There is a growing awareness that real-world systems that operate over long periods and require fairness over different timelines. However, existing approaches mainly address dynamic costs with time-invariant fairness constraints, often disregarding the challenges posed by time-varying fairness constraints. To bridge this gap, this work introduces a framework for ensuring long-term fairness within dynamic decision-making systems characterized by time-varying fairness constraints. We formulate the decision problem with fairness constraints over a period as a constrained online optimization problem. A novel online algorithm, named LoTFair, is presented that solves the problem 'on the fly'. We prove that LoTFair can make overall fairness violations negligible while maintaining the performance over the long run.
Online Learning for Incentive-Based Demand Response
Mar 27, 2023In this paper, we consider the problem of learning online to manage Demand Response (DR) resources. A typical DR mechanism requires the DR manager to assign a baseline to the participating consumer, where the baseline is an estimate of the counterfactual consumption of the consumer had it not been called to provide the DR service. A challenge in estimating baseline is the incentive the consumer has to inflate the baseline estimate. We consider the problem of learning online to estimate the baseline and to optimize the operating costs over a period of time under such incentives. We propose an online learning scheme that employs least-squares for estimation with a perturbation to the reward price (for the DR services or load curtailment) that is designed to balance the exploration and exploitation trade-off that arises with online learning. We show that, our proposed scheme is able to achieve a very low regret of $\mathcal{O}\left((\log{T})^2\right)$ with respect to the optimal operating cost over $T$ days of the DR program with full knowledge of the baseline, and is individually rational for the consumers to participate. Our scheme is significantly better than the averaging type approach, which only fetches $\mathcal{O}(T^{1/3})$ regret.
Online Convex Optimization with Long Term Constraints for Predictable Sequences
Oct 30, 2022In this paper, we investigate the framework of Online Convex Optimization (OCO) for online learning. OCO offers a very powerful online learning framework for many applications. In this context, we study a specific framework of OCO called {\it OCO with long term constraints}. Long term constraints are introduced typically as an alternative to reduce the complexity of the projection at every update step in online optimization. While many algorithmic advances have been made towards online optimization with long term constraints, these algorithms typically assume that the sequence of cost functions over a certain $T$ finite steps that determine the cost to the online learner are adversarially generated. In many circumstances, the sequence of cost functions may not be unrelated, and thus predictable from those observed till a point of time. In this paper, we study the setting where the sequences are predictable. We present a novel online optimization algorithm for online optimization with long term constraints that can leverage such predictability. We show that, with a predictor that can supply the gradient information of the next function in the sequence, our algorithm can achieve an overall regret and constraint violation rate that is strictly less than the rate that is achievable without prediction.
Meta-Learning Online Control for Linear Dynamical Systems
Aug 18, 2022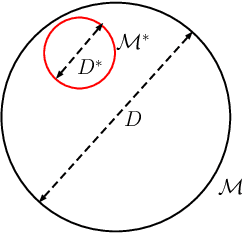
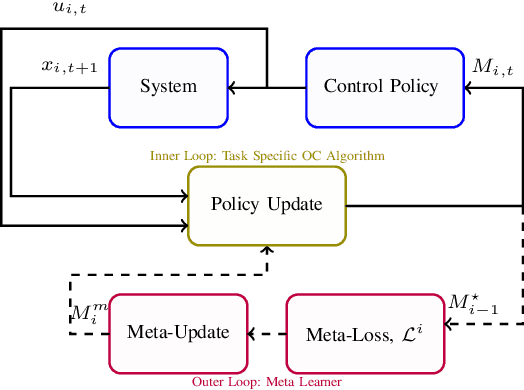
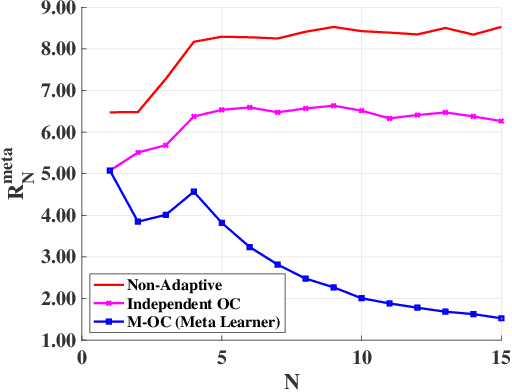
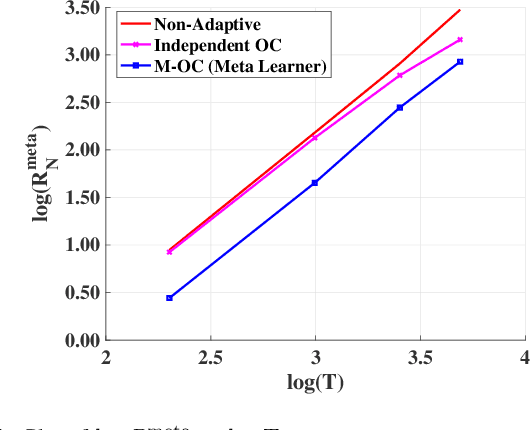
In this paper, we consider the problem of finding a meta-learning online control algorithm that can learn across the tasks when faced with a sequence of $N$ (similar) control tasks. Each task involves controlling a linear dynamical system for a finite horizon of $T$ time steps. The cost function and system noise at each time step are adversarial and unknown to the controller before taking the control action. Meta-learning is a broad approach where the goal is to prescribe an online policy for any new unseen task exploiting the information from other tasks and the similarity between the tasks. We propose a meta-learning online control algorithm for the control setting and characterize its performance by \textit{meta-regret}, the average cumulative regret across the tasks. We show that when the number of tasks are sufficiently large, our proposed approach achieves a meta-regret that is smaller by a factor $D/D^{*}$ compared to an independent-learning online control algorithm which does not perform learning across the tasks, where $D$ is a problem constant and $D^{*}$ is a scalar that decreases with increase in the similarity between tasks. Thus, when the sequence of tasks are similar the regret of the proposed meta-learning online control is significantly lower than that of the naive approaches without meta-learning. We also present experiment results to demonstrate the superior performance achieved by our meta-learning algorithm.
Online Learning for Receding Horizon Control with Provable Regret Guarantees
Nov 30, 2021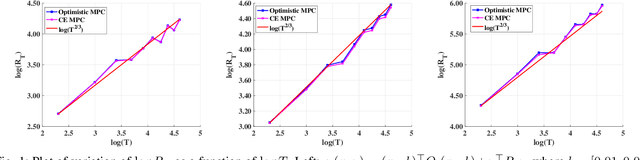
We address the problem of learning to control an unknown linear dynamical system with time varying cost functions through the framework of online Receding Horizon Control (RHC). We consider the setting where the control algorithm does not know the true system model and has only access to a fixed-length (that does not grow with the control horizon) preview of the future cost functions. We characterize the performance of an algorithm using the metric of dynamic regret, which is defined as the difference between the cumulative cost incurred by the algorithm and that of the best sequence of actions in hindsight. We propose two different online RHC algorithms to address this problem, namely Certainty Equivalence RHC (CE-RHC) algorithm and Optimistic RHC (O-RHC) algorithm. We show that under the standard stability assumption for the model estimate, the CE-RHC algorithm achieves $\mathcal{O}(T^{2/3})$ dynamic regret. We then extend this result to the setting where the stability assumption hold only for the true system model by proposing the O-RHC algorithm. We show that O-RHC algorithm achieves $\mathcal{O}(T^{2/3})$ dynamic regret but with some additional computation.
Spatio-Temporal Scene-Graph Embedding for Autonomous Vehicle Collision Prediction
Nov 11, 2021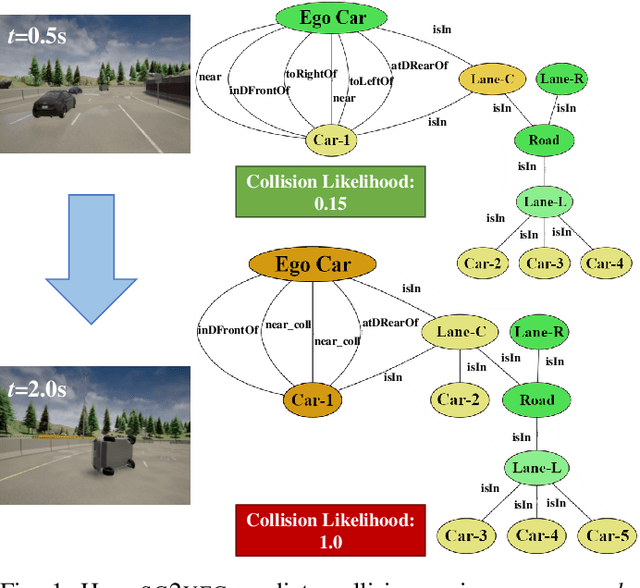
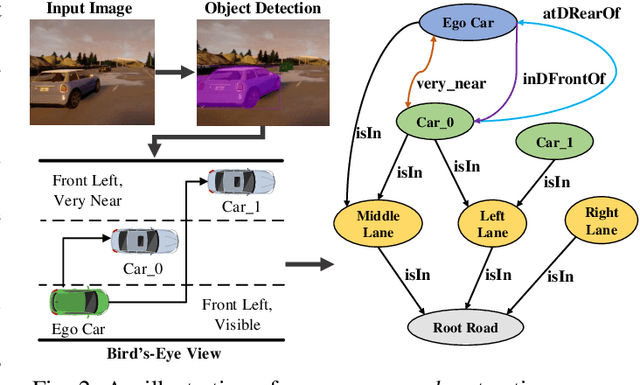
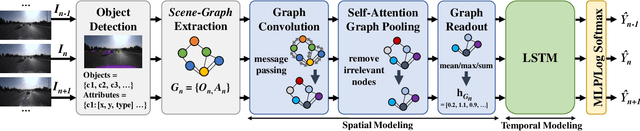

In autonomous vehicles (AVs), early warning systems rely on collision prediction to ensure occupant safety. However, state-of-the-art methods using deep convolutional networks either fail at modeling collisions or are too expensive/slow, making them less suitable for deployment on AV edge hardware. To address these limitations, we propose sg2vec, a spatio-temporal scene-graph embedding methodology that uses Graph Neural Network (GNN) and Long Short-Term Memory (LSTM) layers to predict future collisions via visual scene perception. We demonstrate that sg2vec predicts collisions 8.11% more accurately and 39.07% earlier than the state-of-the-art method on synthesized datasets, and 29.47% more accurately on a challenging real-world collision dataset. We also show that sg2vec is better than the state-of-the-art at transferring knowledge from synthetic datasets to real-world driving datasets. Finally, we demonstrate that sg2vec performs inference 9.3x faster with an 88.0% smaller model, 32.4% less power, and 92.8% less energy than the state-of-the-art method on the industry-standard Nvidia DRIVE PX 2 platform, making it more suitable for implementation on the edge.
Graph Learning for Cognitive Digital Twins in Manufacturing Systems
Sep 17, 2021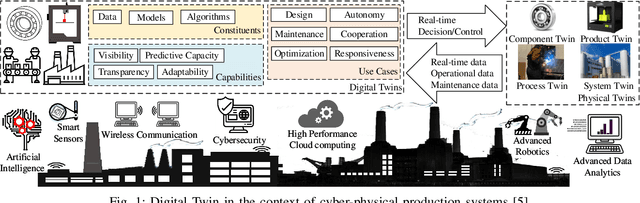
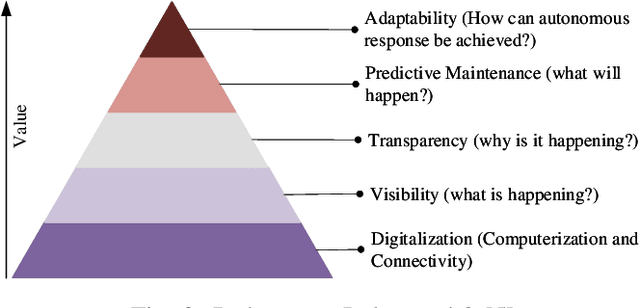
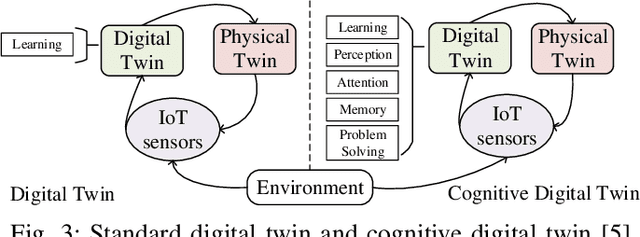
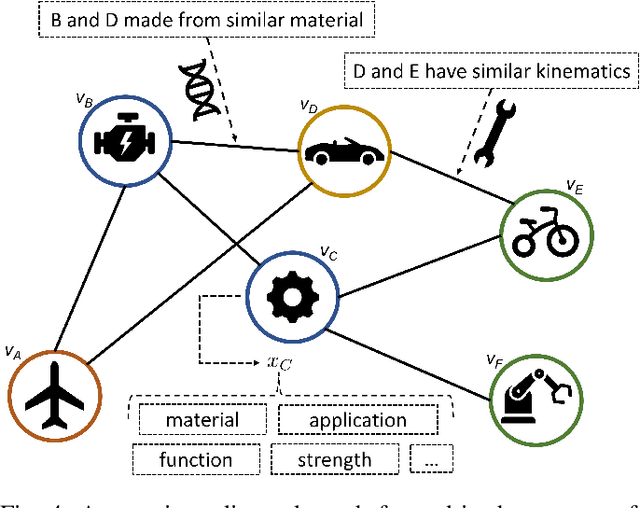
Future manufacturing requires complex systems that connect simulation platforms and virtualization with physical data from industrial processes. Digital twins incorporate a physical twin, a digital twin, and the connection between the two. Benefits of using digital twins, especially in manufacturing, are abundant as they can increase efficiency across an entire manufacturing life-cycle. The digital twin concept has become increasingly sophisticated and capable over time, enabled by rises in many technologies. In this paper, we detail the cognitive digital twin as the next stage of advancement of a digital twin that will help realize the vision of Industry 4.0. Cognitive digital twins will allow enterprises to creatively, effectively, and efficiently exploit implicit knowledge drawn from the experience of existing manufacturing systems. They also enable more autonomous decisions and control, while improving the performance across the enterprise (at scale). This paper presents graph learning as one potential pathway towards enabling cognitive functionalities in manufacturing digital twins. A novel approach to realize cognitive digital twins in the product design stage of manufacturing that utilizes graph learning is presented.
Generative Adversarial Imitation Learning for Empathy-based AI
May 27, 2021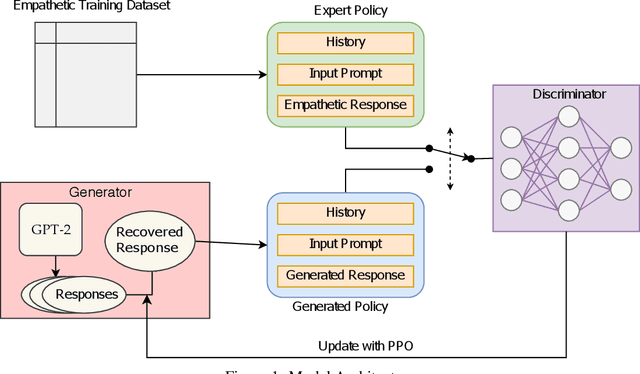


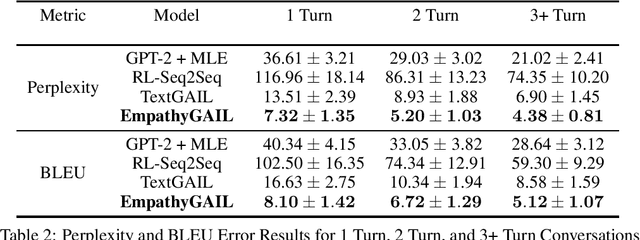
Generative adversarial imitation learning (GAIL) is a model-free algorithm that has been shown to provide strong results in imitating complex behaviors in high-dimensional environments. In this paper, we utilize the GAIL model for text generation to develop empathy-based context-aware conversational AI. Our model uses an expert trajectory of empathetic prompt-response dialogues which can accurately exhibit the correct empathetic emotion when generating a response. The Generator of the GAIL model uses the GPT-2 sequential pre-trained language model trained on 117 million parameters from 40 GB of internet data. We propose a novel application of an approach used in transfer learning to fine tune the GPT-2 model in order to generate concise, user-specific empathetic responses validated against the Discriminator. Our novel GAIL model utilizes a sentiment analysis history-based reinforcement learning approach to empathetically respond to human interactions in a personalized manner. We find that our model's response scores on various human-generated prompts collected from the Facebook Empathetic Dialogues dataset outperform baseline counterparts. Moreover, our model improves upon various history-based conversational AI models developed recently, as our model's performance over a sustained conversation of 3 or more interactions outperform similar conversational AI models.
Neuroscience-Inspired Algorithms for the Predictive Maintenance of Manufacturing Systems
Feb 23, 2021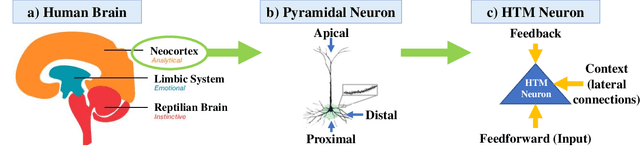
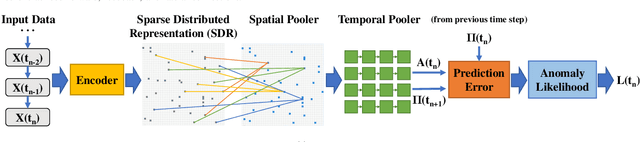


If machine failures can be detected preemptively, then maintenance and repairs can be performed more efficiently, reducing production costs. Many machine learning techniques for performing early failure detection using vibration data have been proposed; however, these methods are often power and data-hungry, susceptible to noise, and require large amounts of data preprocessing. Also, training is usually only performed once before inference, so they do not learn and adapt as the machine ages. Thus, we propose a method of performing online, real-time anomaly detection for predictive maintenance using Hierarchical Temporal Memory (HTM). Inspired by the human neocortex, HTMs learn and adapt continuously and are robust to noise. Using the Numenta Anomaly Benchmark, we empirically demonstrate that our approach outperforms state-of-the-art algorithms at preemptively detecting real-world cases of bearing failures and simulated 3D printer failures. Our approach achieves an average score of 64.71, surpassing state-of-the-art deep-learning (49.38) and statistical (61.06) methods.
Meta-Learning Guarantees for Online Receding Horizon Control
Nov 11, 2020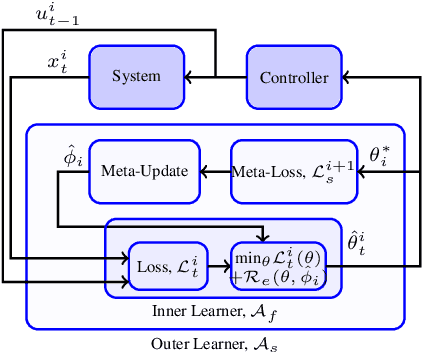
In this paper we provide provable regret guarantees for an online meta-learning receding horizon control algorithm in an iterative control setting, where in each iteration the system to be controlled is a linear deterministic system that is different and unknown, the cost for the controller in an iteration is a general additive cost function and the control input is required to be constrained, which if violated incurs an additional cost. We prove (i) that the algorithm achieves a regret for the controller cost and constraint violation that are $O(T^{3/4})$ for an episode of duration $T$ with respect to the best policy that satisfies the control input control constraints and (ii) that the average of the regret for the controller cost and constraint violation with respect to the same policy vary as $O((1+1/\sqrt{N})T^{3/4})$ with the number of iterations $N$, showing that the worst regret for the learning within an iteration continuously improves with experience of more iterations.