 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Scene-Graph Embedding for Autonomous Vehicle Collision Prediction
Paper and Code
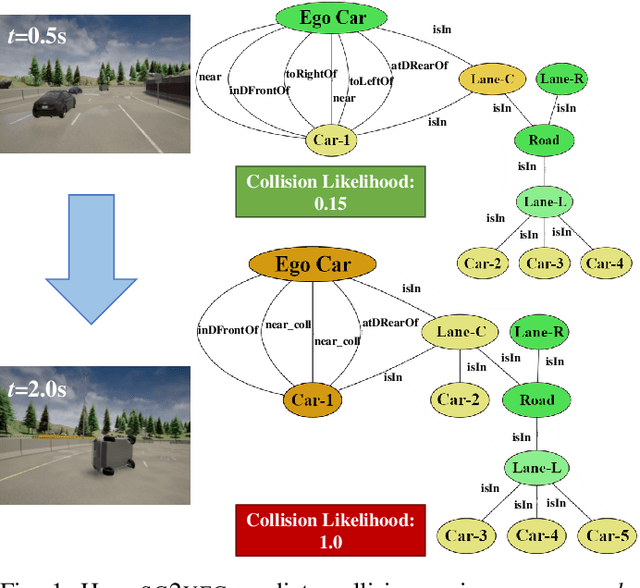
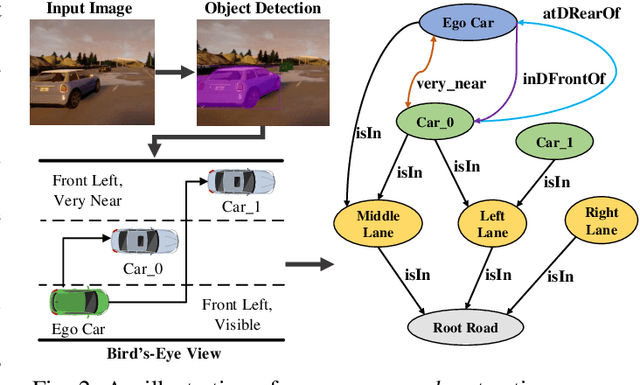
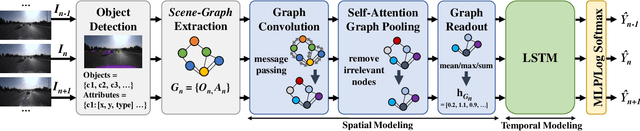

In autonomous vehicles (AVs), early warning systems rely on collision prediction to ensure occupant safety. However, state-of-the-art methods using deep convolutional networks either fail at modeling collisions or are too expensive/slow, making them less suitable for deployment on AV edge hardware. To address these limitations, we propose sg2vec, a spatio-temporal scene-graph embedding methodology that uses Graph Neural Network (GNN) and Long Short-Term Memory (LSTM) layers to predict future collisions via visual scene perception. We demonstrate that sg2vec predicts collisions 8.11% more accurately and 39.07% earlier than the state-of-the-art method on synthesized datasets, and 29.47% more accurately on a challenging real-world collision dataset. We also show that sg2vec is better than the state-of-the-art at transferring knowledge from synthetic datasets to real-world driving datasets. Finally, we demonstrate that sg2vec performs inference 9.3x faster with an 88.0% smaller model, 32.4% less power, and 92.8% less energy than the state-of-the-art method on the industry-standard Nvidia DRIVE PX 2 platform, making it more suitable for implementation on the edge.