 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Diffusion LLMs with Entropy-Guided Step Selection and Stepwise Advantages
Mar 13, 2026Reinforcement learning (RL) has been effective for post-training autoregressive (AR) language models, but extending these methods to diffusion language models (DLMs) is challenging due to intractable sequence-level likelihoods. Existing approaches therefore rely on surrogate likelihoods or heuristic approximations, which can introduce bias and obscure the sequential structure of denoising. We formulate diffusion-based sequence generation as a finite-horizon Markov decision process over the denoising trajectory and derive an exact, unbiased policy gradient that decomposes over denoising steps and is expressed in terms of intermediate advantages, without requiring explicit evaluation of the sequence likelihood. To obtain a practical and compute-efficient estimator, we (i) select denoising steps for policy updates via an entropy-guided approximation bound, and (ii) estimate intermediate advantages using a one-step denoising reward naturally provided by the diffusion model, avoiding costly multi-step rollouts. Experiments on coding and logical reasoning benchmarks demonstrate state-of-the-art results, with strong competitive performance on mathematical reasoning, outperforming existing RL post-training approaches for DLMs. Code is available at https://github.com/vishnutez/egspo-dllm-rl.
Optimistic World Models: Efficient Exploration in Model-Based Deep Reinforcement Learning
Feb 10, 2026Efficient exploration remains a central challenge in reinforcement learning (RL), particularly in sparse-reward environments. We introduce Optimistic World Models (OWMs), a principled and scalable framework for optimistic exploration that brings classical reward-biased maximum likelihood estimation (RBMLE) from adaptive control into deep RL. In contrast to upper confidence bound (UCB)-style exploration methods, OWMs incorporate optimism directly into model learning by augmentation with an optimistic dynamics loss that biases imagined transitions toward higher-reward outcomes. This fully gradient-based loss requires neither uncertainty estimates nor constrained optimization. Our approach is plug-and-play with existing world model frameworks, preserving scalability while requiring only minimal modifications to standard training procedures. We instantiate OWMs within two state-of-the-art world model architectures, leading to Optimistic DreamerV3 and Optimistic STORM, which demonstrate significant improvements in sample efficiency and cumulative return compared to their baseline counterparts.
In-Context Learning for Gradient-Free Receiver Adaptation: Principles, Applications, and Theory
Jun 18, 2025In recent years, deep learning has facilitated the creation of wireless receivers capable of functioning effectively in conditions that challenge traditional model-based designs. Leveraging programmable hardware architectures, deep learning-based receivers offer the potential to dynamically adapt to varying channel environments. However, current adaptation strategies, including joint training, hypernetwork-based methods, and meta-learning, either demonstrate limited flexibility or necessitate explicit optimization through gradient descent. This paper presents gradient-free adaptation techniques rooted in the emerging paradigm of in-context learning (ICL). We review architectural frameworks for ICL based on Transformer models and structured state-space models (SSMs), alongside theoretical insights into how sequence models effectively learn adaptation from contextual information. Further, we explore the application of ICL to cell-free massive MIMO networks, providing both theoretical analyses and empirical evidence. Our findings indicate that ICL represents a principled and efficient approach to real-time receiver adaptation using pilot signals and auxiliary contextual information-without requiring online retraining.
Curriculum Reinforcement Learning from Easy to Hard Tasks Improves LLM Reasoning
Jun 07, 2025We aim to improve the reasoning capabilities of language models via reinforcement learning (RL). Recent RL post-trained models like DeepSeek-R1 have demonstrated reasoning abilities on mathematical and coding tasks. However, prior studies suggest that using RL alone to improve reasoning on inherently difficult tasks is less effective. Here, we draw inspiration from curriculum learning and propose to schedule tasks from easy to hard (E2H), allowing LLMs to build reasoning skills gradually. Our method is termed E2H Reasoner. Empirically, we observe that, although easy tasks are important initially, fading them out through appropriate scheduling is essential in preventing overfitting. Theoretically, we establish convergence guarantees for E2H Reasoner within an approximate policy iteration framework. We derive finite-sample complexity bounds and show that when tasks are appropriately decomposed and conditioned, learning through curriculum stages requires fewer total samples than direct learning. Experiments across multiple domains show that E2H Reasoner significantly improves the reasoning ability of small LLMs (1.5B to 3B), which otherwise struggle when trained with vanilla RL alone, highlighting the effectiveness of our method.
Diffusion Blend: Inference-Time Multi-Preference Alignment for Diffusion Models
May 24, 2025
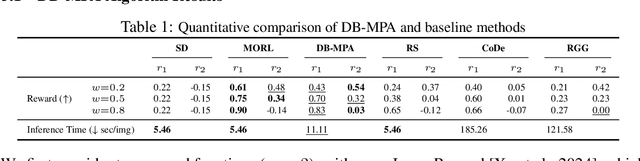


Reinforcement learning (RL) algorithms have been used recently to align diffusion models with downstream objectives such as aesthetic quality and text-image consistency by fine-tuning them to maximize a single reward function under a fixed KL regularization. However, this approach is inherently restrictive in practice, where alignment must balance multiple, often conflicting objectives. Moreover, user preferences vary across prompts, individuals, and deployment contexts, with varying tolerances for deviation from a pre-trained base model. We address the problem of inference-time multi-preference alignment: given a set of basis reward functions and a reference KL regularization strength, can we design a fine-tuning procedure so that, at inference time, it can generate images aligned with any user-specified linear combination of rewards and regularization, without requiring additional fine-tuning? We propose Diffusion Blend, a novel approach to solve inference-time multi-preference alignment by blending backward diffusion processes associated with fine-tuned models, and we instantiate this approach with two algorithms: DB-MPA for multi-reward alignment and DB-KLA for KL regularization control. Extensive experiments show that Diffusion Blend algorithms consistently outperform relevant baselines and closely match or exceed the performance of individually fine-tuned models, enabling efficient, user-driven alignment at inference-time. The code is available at https://github.com/bluewoods127/DB-2025}{github.com/bluewoods127/DB-2025.
Distributionally Robust Direct Preference Optimization
Feb 04, 2025



A major challenge in aligning large language models (LLMs) with human preferences is the issue of distribution shift. LLM alignment algorithms rely on static preference datasets, assuming that they accurately represent real-world user preferences. However, user preferences vary significantly across geographical regions, demographics, linguistic patterns, and evolving cultural trends. This preference distribution shift leads to catastrophic alignment failures in many real-world applications. We address this problem using the principled framework of distributionally robust optimization, and develop two novel distributionally robust direct preference optimization (DPO) algorithms, namely, Wasserstein DPO (WDPO) and Kullback-Leibler DPO (KLDPO). We characterize the sample complexity of learning the optimal policy parameters for WDPO and KLDPO. Moreover, we propose scalable gradient descent-style learning algorithms by developing suitable approximations for the challenging minimax loss functions of WDPO and KLDPO. Our empirical experiments demonstrate the superior performance of WDPO and KLDPO in substantially improving the alignment when there is a preference distribution shift.
Risk-Averse Finetuning of Large Language Models
Jan 12, 2025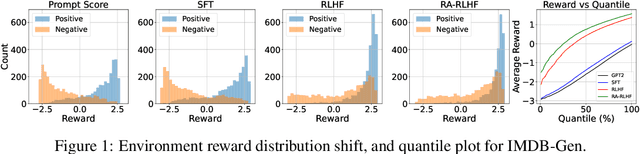
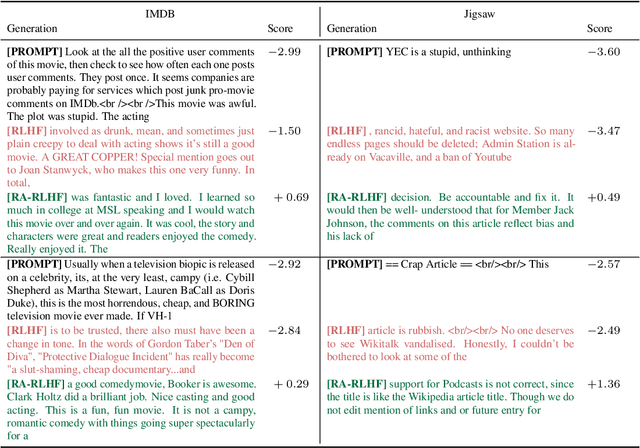
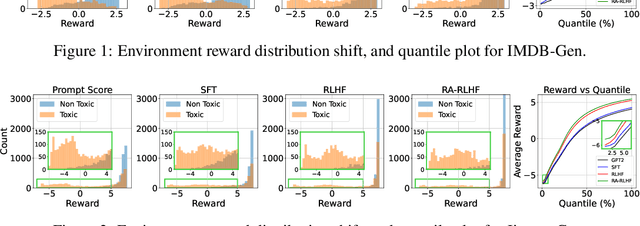
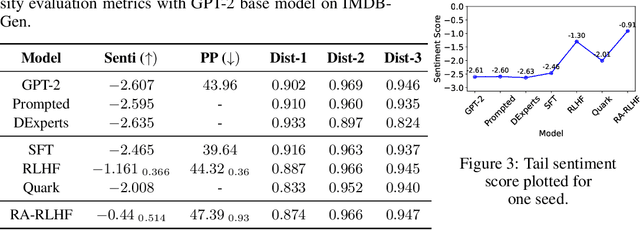
We consider the challenge of mitigating the generation of negative or toxic content by the Large Language Models (LLMs) in response to certain prompts. We propose integrating risk-averse principles into LLM fine-tuning to minimize the occurrence of harmful outputs, particularly rare but significant events. By optimizing the risk measure of Conditional Value at Risk (CVaR), our methodology trains LLMs to exhibit superior performance in avoiding toxic outputs while maintaining effectiveness in generative tasks. Empirical evaluations on sentiment modification and toxicity mitigation tasks demonstrate the efficacy of risk-averse reinforcement learning with human feedback (RLHF) in promoting a safer and more constructive online discourse environment.
PowerMamba: A Deep State Space Model and Comprehensive Benchmark for Time Series Prediction in Electric Power Systems
Dec 09, 2024



The electricity sector is undergoing substantial transformations due to the rising electrification of demand, enhanced integration of renewable energy resources, and the emergence of new technologies. These changes are rendering the electric grid more volatile and unpredictable, making it difficult to maintain reliable operations. In order to address these issues, advanced time series prediction models are needed for closing the gap between the forecasted and actual grid outcomes. In this paper, we introduce a multivariate time series prediction model that combines traditional state space models with deep learning methods to simultaneously capture and predict the underlying dynamics of multiple time series. Additionally, we design a time series processing module that incorporates high-resolution external forecasts into sequence-to-sequence prediction models, achieving this with negligible increases in size and no loss of accuracy. We also release an extended dataset spanning five years of load, electricity price, ancillary service price, and renewable generation. To complement this dataset, we provide an open-access toolbox that includes our proposed model, the dataset itself, and several state-of-the-art prediction models, thereby creating a unified framework for benchmarking advanced machine learning approaches. Our findings indicate that the proposed model outperforms existing models across various prediction tasks, improving state-of-the-art prediction error by an average of 7% and decreasing model parameters by 43%.
Structured Reinforcement Learning for Media Streaming at the Wireless Edge
Apr 10, 2024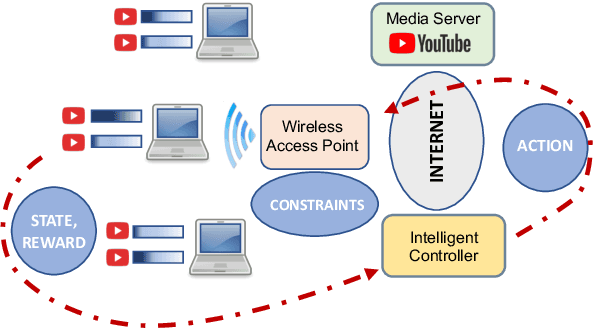
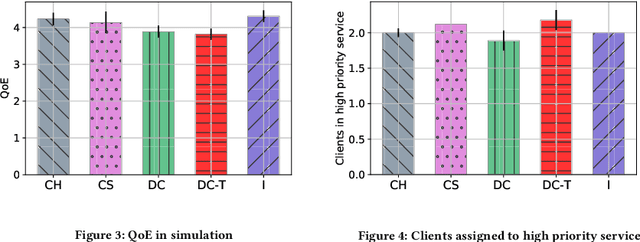
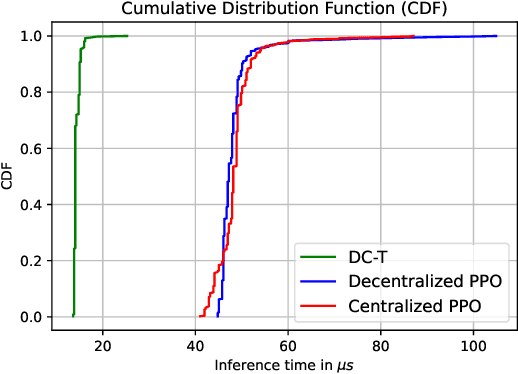
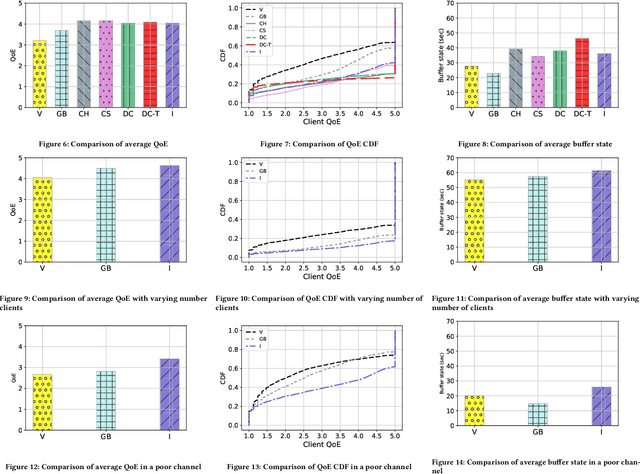
Media streaming is the dominant application over wireless edge (access) networks. The increasing softwarization of such networks has led to efforts at intelligent control, wherein application-specific actions may be dynamically taken to enhance the user experience. The goal of this work is to develop and demonstrate learning-based policies for optimal decision making to determine which clients to dynamically prioritize in a video streaming setting. We formulate the policy design question as a constrained Markov decision problem (CMDP), and observe that by using a Lagrangian relaxation we can decompose it into single-client problems. Further, the optimal policy takes a threshold form in the video buffer length, which enables us to design an efficient constrained reinforcement learning (CRL) algorithm to learn it. Specifically, we show that a natural policy gradient (NPG) based algorithm that is derived using the structure of our problem converges to the globally optimal policy. We then develop a simulation environment for training, and a real-world intelligent controller attached to a WiFi access point for evaluation. We empirically show that the structured learning approach enables fast learning. Furthermore, such a structured policy can be easily deployed due to low computational complexity, leading to policy execution taking only about 15$\mu$s. Using YouTube streaming experiments in a resource constrained scenario, we demonstrate that the CRL approach can increase QoE by over 30%.
AttackGNN: Red-Teaming GNNs in Hardware Security Using Reinforcement Learning
Feb 26, 2024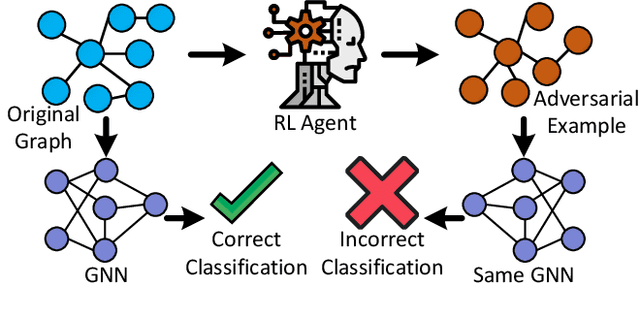

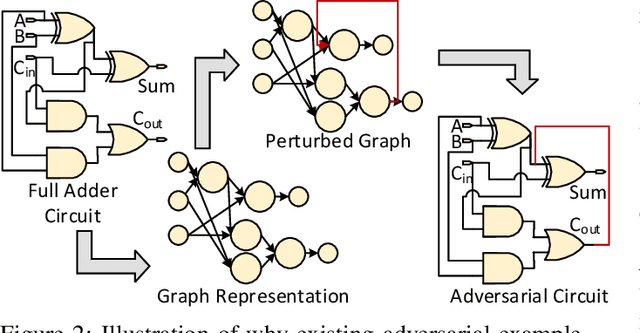
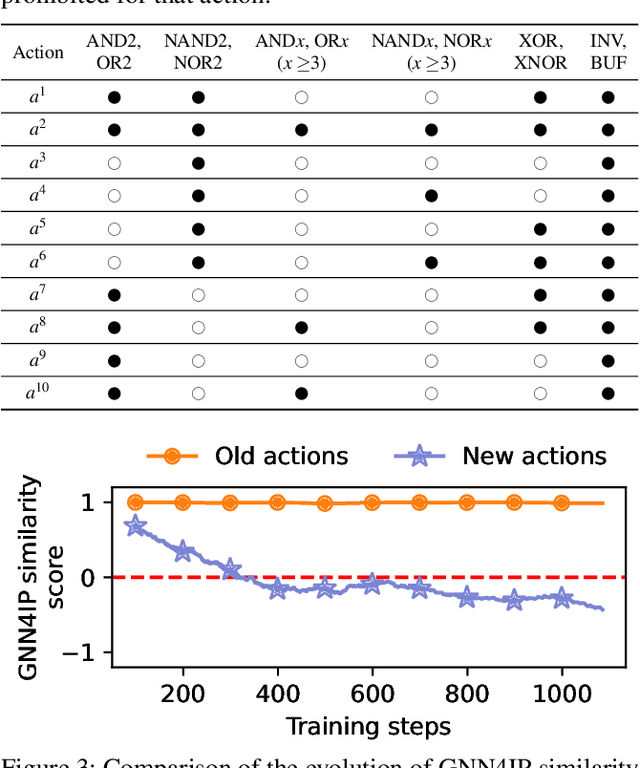
Machine learning has shown great promise in addressing several critical hardware security problems. In particular, researchers have developed novel graph neural network (GNN)-based techniques for detecting intellectual property (IP) piracy, detecting hardware Trojans (HTs), and reverse engineering circuits, to name a few. These techniques have demonstrated outstanding accuracy and have received much attention in the community. However, since these techniques are used for security applications, it is imperative to evaluate them thoroughly and ensure they are robust and do not compromise the security of integrated circuits. In this work, we propose AttackGNN, the first red-team attack on GNN-based techniques in hardware security. To this end, we devise a novel reinforcement learning (RL) agent that generates adversarial examples, i.e., circuits, against the GNN-based techniques. We overcome three challenges related to effectiveness, scalability, and generality to devise a potent RL agent. We target five GNN-based techniques for four crucial classes of problems in hardware security: IP piracy, detecting/localizing HTs, reverse engineering, and hardware obfuscation. Through our approach, we craft circuits that fool all GNNs considered in this work. For instance, to evade IP piracy detection, we generate adversarial pirated circuits that fool the GNN-based defense into classifying our crafted circuits as not pirated. For attacking HT localization GNN, our attack generates HT-infested circuits that fool the defense on all tested circuits. We obtain a similar 100% success rate against GNNs for all classes of problems.