 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Text Transmission via LLM-Based Entropy Coding over Fixed-Rate Channels
May 03, 2026Learning, prediction, and compression are intimately connected: a model that accurately predicts the next symbol in a sequence can be coupled with a source coder to compress that sequence near its information-theoretic limit. When tokenized characters arriving at a fixed reading pace are encoded into variable-length codewords and streamed over a fixed-rate channel, a queue forms whose per-token delay depends on the mean and variance of the bit lengths and on the coder's algorithmic latency. This paper investigates the compression--delay tradeoff that arises when a causal language model serves as the sequential predictor within a predict-then-code architecture for real-time text transmission. Several coding schemes are compared: Shannon (ideal), Huffman, arithmetic coding, rANS at various block sizes, and gzip. The analysis separates algorithmic delay, inherent to the coder, from computational delay, which shrinks as hardware improves. Huffman is the practical choice for over-provisioned channels, with zero algorithmic delay and modest compression overhead. Arithmetic coding achieves near-optimal compression at the cost of decodability delay. Findings are validated across two scales: GPT-2 (124M) and Llama~3.2 (3B), a twenty-five-fold parameter range. This scaling yields an approximately 38\% reduction in bits per character, effectively over-provisioning the channel and thereby changing which coder is optimal.
Complex Approximate Message Passing with Non-separable Denoising
Apr 22, 2026Approximate Message Passing (AMP) is a general framework for iterative algorithms, originally developed for compressed sensing and later extended to a wide range of high-dimensional inference problems. Although recent work has advanced matrix AMP, complex AMP, and AMP for non-separable functions independently, a unified state evolution theory for complex AMP with non-separable denoisers has been lacking. This article fills that gap by establishing state evolution in the setting of complex, non-separable denoising functions. The proposed approach constructs an augmented real-valued system that lifts the problem to a higher-dimensional space, then recovers the complex domain through a many-to-one canonical transformation. Under this construction, the Onsager correction naturally involves Wirtinger derivatives, and the resulting state evolution reduces to scalar complex recursions despite the non-separable structure of the denoisers. The framework extends to the matrix-valued setting, accommodating multiple feature vectors simultaneously. This generalization enables AMP to exploit joint structural constraints, such as simultaneous group and element sparsity, in complex-valued recovery problems. The complex sparse group least absolute shrinkage and selection operator (LASSO) serves as a key instantiation, motivated by preamble detection in Orthogonal Time-Frequency Space (OTFS)-based unsourced random access. Numerical experiments confirm that state evolution accurately predicts performance and show that complex non-separable denoising can produce significant gains over separable and real-valued alternatives.
Reinforcement Learning for Diffusion LLMs with Entropy-Guided Step Selection and Stepwise Advantages
Mar 13, 2026Reinforcement learning (RL) has been effective for post-training autoregressive (AR) language models, but extending these methods to diffusion language models (DLMs) is challenging due to intractable sequence-level likelihoods. Existing approaches therefore rely on surrogate likelihoods or heuristic approximations, which can introduce bias and obscure the sequential structure of denoising. We formulate diffusion-based sequence generation as a finite-horizon Markov decision process over the denoising trajectory and derive an exact, unbiased policy gradient that decomposes over denoising steps and is expressed in terms of intermediate advantages, without requiring explicit evaluation of the sequence likelihood. To obtain a practical and compute-efficient estimator, we (i) select denoising steps for policy updates via an entropy-guided approximation bound, and (ii) estimate intermediate advantages using a one-step denoising reward naturally provided by the diffusion model, avoiding costly multi-step rollouts. Experiments on coding and logical reasoning benchmarks demonstrate state-of-the-art results, with strong competitive performance on mathematical reasoning, outperforming existing RL post-training approaches for DLMs. Code is available at https://github.com/vishnutez/egspo-dllm-rl.
Approximate Message Passing for Multi-Preamble Detection in OTFS Random Access
Sep 04, 2025This article addresses the problem of multiple preamble detection in random access systems based on orthogonal time frequency space (OTFS) signaling. This challenge is formulated as a structured sparse recovery problem in the complex domain. To tackle it, the authors propose a new approximate message passing (AMP) algorithm that enforces double sparsity: the sparse selection of preambles and the inherent sparsity of OTFS signals in the delay-Doppler domain. From an algorithmic standpoint, the non-separable complex sparsity constraint necessitates a careful derivation and leads to the design of a novel AMP denoiser. Simulation results demonstrate that the proposed method achieves robust detection performance and delivers significant gains over state-of-the-art techniques.
Camera-Based Localization and Enhanced Normalized Mutual Information
Dec 20, 2024



Robust and fine localization algorithms are crucial for autonomous driving. For the production of such vehicles as a commodity, affordable sensing solutions and reliable localization algorithms must be designed. This work considers scenarios where the sensor data comes from images captured by an inexpensive camera mounted on the vehicle and where the vehicle contains a fine global map. Such localization algorithms typically involve finding the section in the global map that best matches the captured image. In harsh environments, both the global map and the captured image can be noisy. Because of physical constraints on camera placement, the image captured by the camera can be viewed as a noisy perspective transformed version of the road in the global map. Thus, an optimal algorithm should take into account the unequal noise power in various regions of the captured image, and the intrinsic uncertainty in the global map due to environmental variations. This article briefly reviews two matching methods: (i) standard inner product (SIP) and (ii) normalized mutual information (NMI). It then proposes novel and principled modifications to improve the performance of these algorithms significantly in noisy environments. These enhancements are inspired by the physical constraints associated with autonomous vehicles. They are grounded in statistical signal processing and, in some context, are provably better. Numerical simulations demonstrate the effectiveness of such modifications.
Multi-User SR-LDPC Codes via Coded Demixing with Applications to Cell-Free Systems
Feb 10, 2024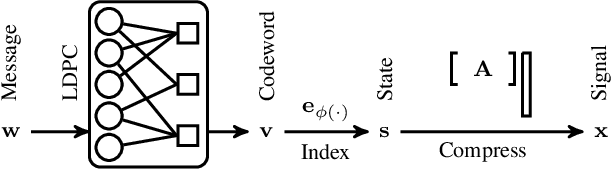
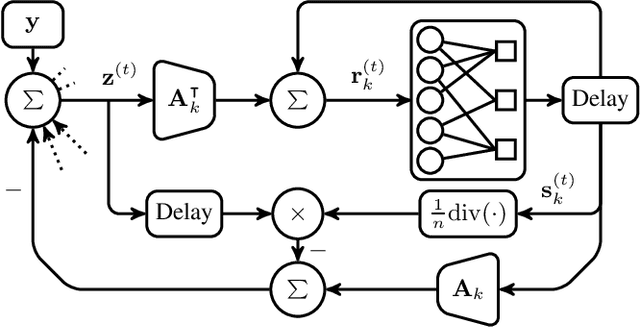


Novel sparse regression LDPC (SR-LDPC) codes exhibit excellent performance over additive white Gaussian noise (AWGN) channels in part due to their natural provision of shaping gains. Though SR-LDPC-like codes have been considered within the context of single-user error correction and massive random access, they are yet to be examined as candidates for coordinated multi-user communication scenarios. This article explores this gap in the literature and demonstrates that SR-LDPC codes, when combined with coded demixing techniques, offer a new framework for efficient non-orthogonal multiple access (NOMA) in the context of coordinated multi-user communication channels. The ensuing communication scheme is referred to as MU-SR-LDPC coding. Empirical evidence suggests that, for a fixed SNR, MU-SR-LDPC coding can achieve a target bit error rate (BER) at a higher sum rate than orthogonal multiple access (OMA) techniques such as time division multiple access (TDMA) and frequency division multiple access (FDMA). Importantly, MU-SR-LDPC codes enable a pragmatic solution path for user-centric cell-free communication systems with (local) joint decoding. Results are supported by numerical simulations.
Transformers are Efficient In-Context Estimators for Wireless Communication
Nov 01, 2023



Pre-trained transformers can perform in-context learning, where they adapt to a new task using only a small number of prompts without any explicit model optimization. Inspired by this attribute, we propose a novel approach, called in-context estimation, for the canonical communication problem of estimating transmitted symbols from received symbols. A communication channel is essentially a noisy function that maps transmitted symbols to received symbols, and this function can be represented by an unknown parameter whose statistics depend on an (also unknown) latent context. Conventional approaches ignore this hierarchical structure and simply attempt to use known transmissions, called pilots, to perform a least-squares estimate of the channel parameter, which is then used to estimate successive, unknown transmitted symbols. We make the basic connection that transformers show excellent contextual sequence completion with a few prompts, and so they should be able to implicitly determine the latent context from pilot symbols to perform end-to-end in-context estimation of transmitted symbols. Furthermore, the transformer should use information efficiently, i.e., it should utilize any pilots received to attain the best possible symbol estimates. Through extensive simulations, we show that in-context estimation not only significantly outperforms standard approaches, but also achieves the same performance as an estimator with perfect knowledge of the latent context within a few context examples. Thus, we make a strong case that transformers are efficient in-context estimators in the communication setting.
LLMZip: Lossless Text Compression using Large Language Models
Jun 26, 2023



We provide new estimates of an asymptotic upper bound on the entropy of English using the large language model LLaMA-7B as a predictor for the next token given a window of past tokens. This estimate is significantly smaller than currently available estimates in \cite{cover1978convergent}, \cite{lutati2023focus}. A natural byproduct is an algorithm for lossless compression of English text which combines the prediction from the large language model with a lossless compression scheme. Preliminary results from limited experiments suggest that our scheme outperforms state-of-the-art text compression schemes such as BSC, ZPAQ, and paq8h.
Scalable Cell-Free Massive MIMO Unsourced Random Access System
Apr 12, 2023



Cell-Free Massive MIMO systems aim to expand the coverage area of wireless networks by replacing a single high-performance Access Point (AP) with multiple small, distributed APs connected to a Central Processing Unit (CPU) through a fronthaul. Another novel wireless approach, known as the unsourced random access (URA) paradigm, enables a large number of devices to communicate concurrently on the uplink. This article considers a quasi-static Rayleigh fading channel paired to a scalable cell-free system, wherein a small number of receive antennas in the distributed APs serve devices equipped with a single antenna each. The goal of the study is to extend previous URA results to more realistic channels by examining the performance of a scalable cell-free system. To achieve this goal, we propose a coding scheme that adapts the URA paradigm to various cell-free scenarios. Empirical evidence suggests that using a cell-free architecture can improve the performance of a URA system, especially when taking into account large-scale attenuation and fading.
PolarAir: A Compressed Sensing Scheme for Over-the-Air Federated Learning
Jan 24, 2023



We explore a scheme that enables the training of a deep neural network in a Federated Learning configuration over an additive white Gaussian noise channel. The goal is to create a low complexity, linear compression strategy, called PolarAir, that reduces the size of the gradient at the user side to lower the number of channel uses needed to transmit it. The suggested approach belongs to the family of compressed sensing techniques, yet it constructs the sensing matrix and the recovery procedure using multiple access techniques. Simulations show that it can reduce the number of channel uses by ~30% when compared to conveying the gradient without compression. The main advantage of the proposed scheme over other schemes in the literature is its low time complexity. We also investigate the behavior of gradient updates and the performance of PolarAir throughout the training process to obtain insight on how best to construct this compression scheme based on compressed sensing.