 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Text Transmission via LLM-Based Entropy Coding over Fixed-Rate Channels
May 03, 2026Learning, prediction, and compression are intimately connected: a model that accurately predicts the next symbol in a sequence can be coupled with a source coder to compress that sequence near its information-theoretic limit. When tokenized characters arriving at a fixed reading pace are encoded into variable-length codewords and streamed over a fixed-rate channel, a queue forms whose per-token delay depends on the mean and variance of the bit lengths and on the coder's algorithmic latency. This paper investigates the compression--delay tradeoff that arises when a causal language model serves as the sequential predictor within a predict-then-code architecture for real-time text transmission. Several coding schemes are compared: Shannon (ideal), Huffman, arithmetic coding, rANS at various block sizes, and gzip. The analysis separates algorithmic delay, inherent to the coder, from computational delay, which shrinks as hardware improves. Huffman is the practical choice for over-provisioned channels, with zero algorithmic delay and modest compression overhead. Arithmetic coding achieves near-optimal compression at the cost of decodability delay. Findings are validated across two scales: GPT-2 (124M) and Llama~3.2 (3B), a twenty-five-fold parameter range. This scaling yields an approximately 38\% reduction in bits per character, effectively over-provisioning the channel and thereby changing which coder is optimal.
Multi-User SR-LDPC Codes via Coded Demixing with Applications to Cell-Free Systems
Feb 10, 2024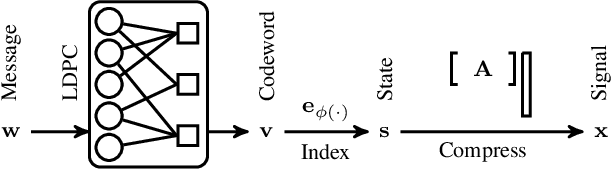
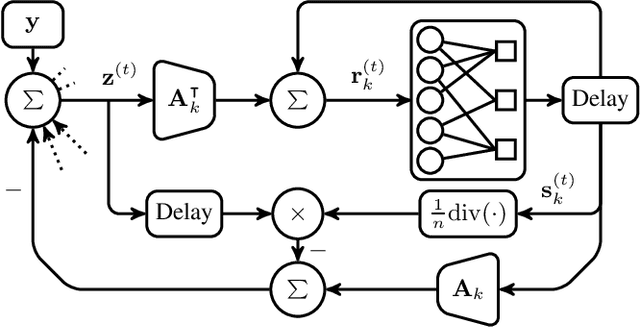


Novel sparse regression LDPC (SR-LDPC) codes exhibit excellent performance over additive white Gaussian noise (AWGN) channels in part due to their natural provision of shaping gains. Though SR-LDPC-like codes have been considered within the context of single-user error correction and massive random access, they are yet to be examined as candidates for coordinated multi-user communication scenarios. This article explores this gap in the literature and demonstrates that SR-LDPC codes, when combined with coded demixing techniques, offer a new framework for efficient non-orthogonal multiple access (NOMA) in the context of coordinated multi-user communication channels. The ensuing communication scheme is referred to as MU-SR-LDPC coding. Empirical evidence suggests that, for a fixed SNR, MU-SR-LDPC coding can achieve a target bit error rate (BER) at a higher sum rate than orthogonal multiple access (OMA) techniques such as time division multiple access (TDMA) and frequency division multiple access (FDMA). Importantly, MU-SR-LDPC codes enable a pragmatic solution path for user-centric cell-free communication systems with (local) joint decoding. Results are supported by numerical simulations.
Scalable Cell-Free Massive MIMO Unsourced Random Access System
Apr 12, 2023



Cell-Free Massive MIMO systems aim to expand the coverage area of wireless networks by replacing a single high-performance Access Point (AP) with multiple small, distributed APs connected to a Central Processing Unit (CPU) through a fronthaul. Another novel wireless approach, known as the unsourced random access (URA) paradigm, enables a large number of devices to communicate concurrently on the uplink. This article considers a quasi-static Rayleigh fading channel paired to a scalable cell-free system, wherein a small number of receive antennas in the distributed APs serve devices equipped with a single antenna each. The goal of the study is to extend previous URA results to more realistic channels by examining the performance of a scalable cell-free system. To achieve this goal, we propose a coding scheme that adapts the URA paradigm to various cell-free scenarios. Empirical evidence suggests that using a cell-free architecture can improve the performance of a URA system, especially when taking into account large-scale attenuation and fading.
PolarAir: A Compressed Sensing Scheme for Over-the-Air Federated Learning
Jan 24, 2023



We explore a scheme that enables the training of a deep neural network in a Federated Learning configuration over an additive white Gaussian noise channel. The goal is to create a low complexity, linear compression strategy, called PolarAir, that reduces the size of the gradient at the user side to lower the number of channel uses needed to transmit it. The suggested approach belongs to the family of compressed sensing techniques, yet it constructs the sensing matrix and the recovery procedure using multiple access techniques. Simulations show that it can reduce the number of channel uses by ~30% when compared to conveying the gradient without compression. The main advantage of the proposed scheme over other schemes in the literature is its low time complexity. We also investigate the behavior of gradient updates and the performance of PolarAir throughout the training process to obtain insight on how best to construct this compression scheme based on compressed sensing.
Noisy Group Testing with Side Information
Feb 24, 2022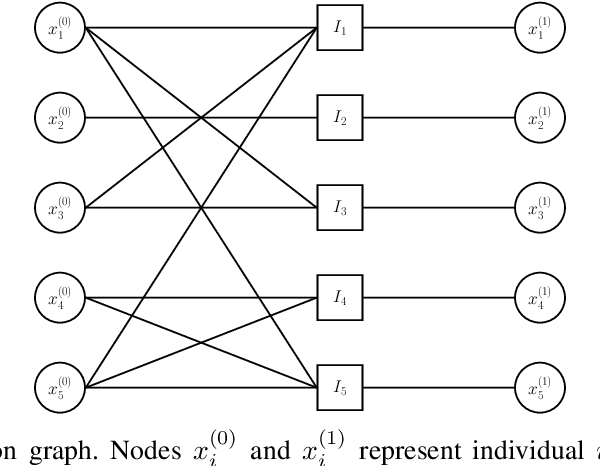
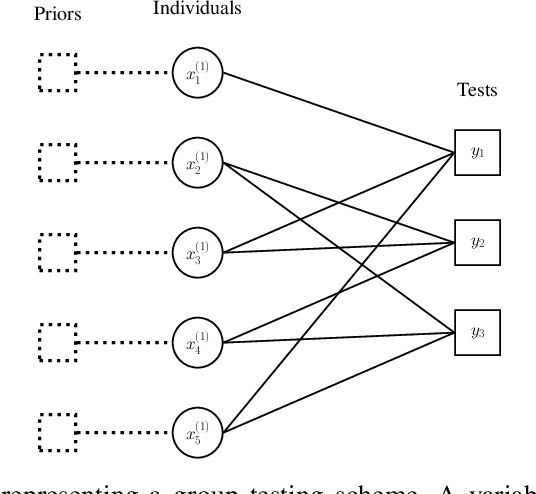
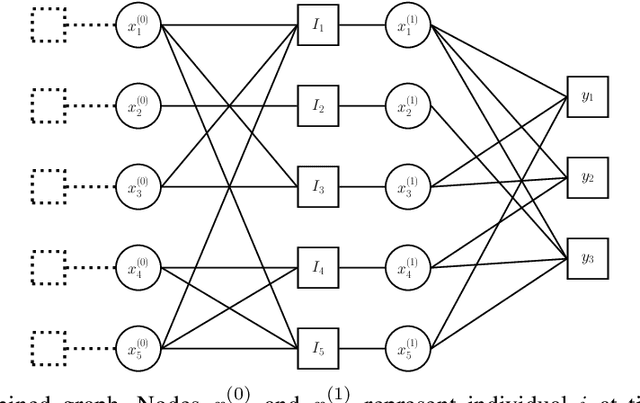
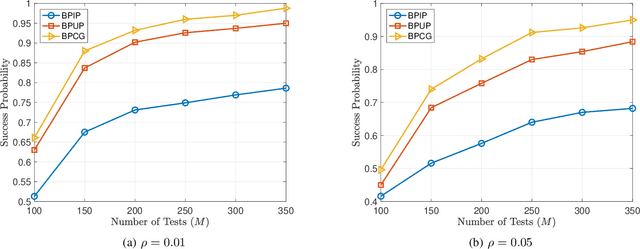
Group testing has recently attracted significant attention from the research community due to its applications in diagnostic virology. An instance of the group testing problem includes a ground set of individuals which includes a small subset of infected individuals. The group testing procedure consists of a number of tests, such that each test indicates whether or not a given subset of individuals includes one or more infected individuals. The goal of the group testing procedure is to identify the subset of infected individuals with the minimum number of tests. Motivated by practical scenarios, such as testing for viral diseases, this paper focuses on the following group testing settings: (i) the group testing procedure is noisy, i.e., the outcome of the group testing procedure can be flipped with a certain probability; (ii) there is a certain amount of side information on the distribution of the infected individuals available to the group testing algorithm. The paper makes the following contributions. First, we propose a probabilistic model, referred to as an interaction model, that captures the side information about the probability distribution of the infected individuals. Next, we present a decoding scheme, based on the belief propagation, that leverages the interaction model to improve the decoding accuracy. Our results indicate that the proposed algorithm achieves higher success probability and lower false-negative and false-positive rates when compared to the traditional belief propagation especially in the high noise regime.
Semi-Implicit Graph Variational Auto-Encoders
Sep 07, 2019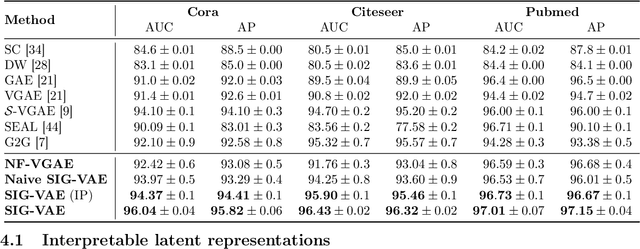
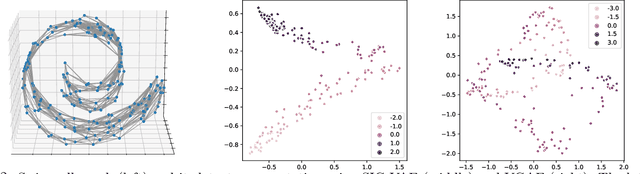
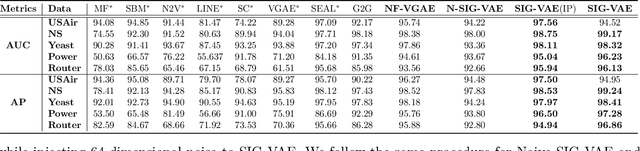

Semi-implicit graph variational auto-encoder (SIG-VAE) is proposed to expand the flexibility of variational graph auto-encoders (VGAE) to model graph data. SIG-VAE employs a hierarchical variational framework to enable neighboring node sharing for better generative modeling of graph dependency structure, together with a Bernoulli-Poisson link decoder. Not only does this hierarchical construction provide a more flexible generative graph model to better capture real-world graph properties, but also does SIG-VAE naturally lead to semi-implicit hierarchical variational inference that allows faithful modeling of implicit posteriors of given graph data, which may exhibit heavy tails, multiple modes, skewness, and rich dependency structures. Compared to VGAE, the derived graph latent representations by SIG-VAE are more interpretable, due to more expressive generative model and more faithful inference enabled by the flexible semi-implicit construction. Extensive experiments with a variety of graph data show that SIG-VAE significantly outperforms state-of-the-art methods on several different graph analytic tasks.
Spatially-Coupled Neural Network Architectures
Jul 03, 2019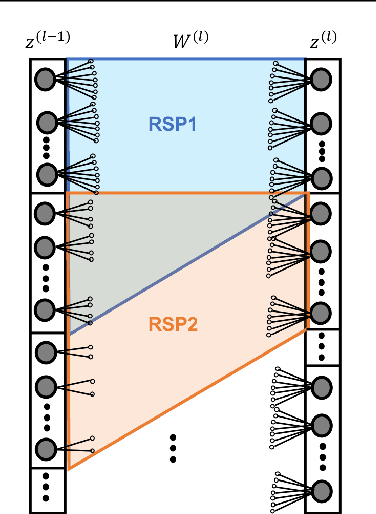

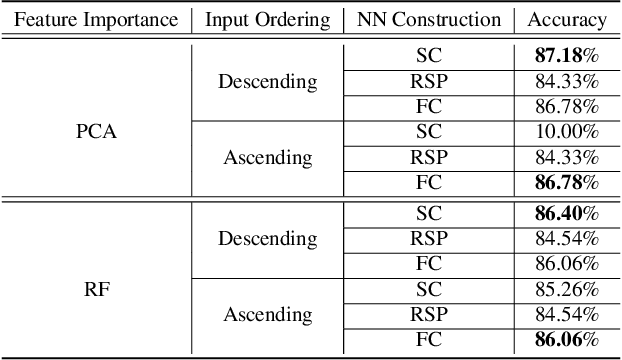
In this work, we leverage advances in sparse coding techniques to reduce the number of trainable parameters in a fully connected neural network. While most of the works in literature impose $\ell_1$ regularization, DropOut or DropConnect techniques to induce sparsity, our scheme considers feature importance as a criterion to allocate the trainable parameters (resources) efficiently in the network. Even though sparsity is ensured, $\ell_1$ regularization requires training on all the resources in a deep neural network. The DropOut/DropConnect techniques reduce the number of trainable parameters in the training stage by dropping a random collection of neurons/edges in the hidden layers. However, both these techniques do not pay heed to the underlying structure in the data when dropping the neurons/edges. Moreover, these frameworks require a storage space equivalent to the number of parameters in a fully connected neural network. We address the above issues with a more structured architecture inspired from spatially-coupled sparse constructions. The proposed architecture is shown to have a performance akin to a conventional fully connected neural network with dropouts, and yet achieving a $94\%$ reduction in the training parameters. Extensive simulations are presented and the performance of the proposed scheme is compared against traditional neural network architectures.