 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvarGC: Invariant Granger Causality for Heterogeneous Interventional Time Series under Latent Confounding
Oct 22, 2025Granger causality is widely used for causal structure discovery in complex systems from multivariate time series data. Traditional Granger causality tests based on linear models often fail to detect even mild non-linear causal relationships. Therefore, numerous recent studies have investigated non-linear Granger causality methods, achieving improved performance. However, these methods often rely on two key assumptions: causal sufficiency and known interventional targets. Causal sufficiency assumes the absence of latent confounders, yet their presence can introduce spurious correlations. Moreover, real-world time series data usually come from heterogeneous environments, without prior knowledge of interventions. Therefore, in practice, it is difficult to distinguish intervened environments from non-intervened ones, and even harder to identify which variables or timesteps are affected. To address these challenges, we propose Invariant Granger Causality (InvarGC), which leverages cross-environment heterogeneity to mitigate the effects of latent confounding and to distinguish intervened from non-intervened environments with edge-level granularity, thereby recovering invariant causal relations. In addition, we establish the identifiability under these conditions. Extensive experiments on both synthetic and real-world datasets demonstrate the competitive performance of our approach compared to state-of-the-art methods.
Data-Augmented Few-Shot Neural Stencil Emulation for System Identification of Computer Models
Aug 26, 2025Partial differential equations (PDEs) underpin the modeling of many natural and engineered systems. It can be convenient to express such models as neural PDEs rather than using traditional numerical PDE solvers by replacing part or all of the PDE's governing equations with a neural network representation. Neural PDEs are often easier to differentiate, linearize, reduce, or use for uncertainty quantification than the original numerical solver. They are usually trained on solution trajectories obtained by long time integration of the PDE solver. Here we propose a more sample-efficient data-augmentation strategy for generating neural PDE training data from a computer model by space-filling sampling of local "stencil" states. This approach removes a large degree of spatiotemporal redundancy present in trajectory data and oversamples states that may be rarely visited but help the neural PDE generalize across the state space. We demonstrate that accurate neural PDE stencil operators can be learned from synthetic training data generated by the computational equivalent of 10 timesteps' worth of numerical simulation. Accuracy is further improved if we assume access to a single full-trajectory simulation from the computer model, which is typically available in practice. Across several PDE systems, we show that our data-augmented synthetic stencil data yield better trained neural stencil operators, with clear performance gains compared with naively sampled stencil data from simulation trajectories.
Toward Greater Autonomy in Materials Discovery Agents: Unifying Planning, Physics, and Scientists
Jun 05, 2025We aim at designing language agents with greater autonomy for crystal materials discovery. While most of existing studies restrict the agents to perform specific tasks within predefined workflows, we aim to automate workflow planning given high-level goals and scientist intuition. To this end, we propose Materials Agent unifying Planning, Physics, and Scientists, known as MAPPS. MAPPS consists of a Workflow Planner, a Tool Code Generator, and a Scientific Mediator. The Workflow Planner uses large language models (LLMs) to generate structured and multi-step workflows. The Tool Code Generator synthesizes executable Python code for various tasks, including invoking a force field foundation model that encodes physics. The Scientific Mediator coordinates communications, facilitates scientist feedback, and ensures robustness through error reflection and recovery. By unifying planning, physics, and scientists, MAPPS enables flexible and reliable materials discovery with greater autonomy, achieving a five-fold improvement in stability, uniqueness, and novelty rates compared with prior generative models when evaluated on the MP-20 data. We provide extensive experiments across diverse tasks to show that MAPPS is a promising framework for autonomous materials discovery.
C-LoRA: Contextual Low-Rank Adaptation for Uncertainty Estimation in Large Language Models
May 23, 2025Low-Rank Adaptation (LoRA) offers a cost-effective solution for fine-tuning large language models (LLMs), but it often produces overconfident predictions in data-scarce few-shot settings. To address this issue, several classical statistical learning approaches have been repurposed for scalable uncertainty-aware LoRA fine-tuning. However, these approaches neglect how input characteristics affect the predictive uncertainty estimates. To address this limitation, we propose Contextual Low-Rank Adaptation (\textbf{C-LoRA}) as a novel uncertainty-aware and parameter efficient fine-tuning approach, by developing new lightweight LoRA modules contextualized to each input data sample to dynamically adapt uncertainty estimates. Incorporating data-driven contexts into the parameter posteriors, C-LoRA mitigates overfitting, achieves well-calibrated uncertainties, and yields robust predictions. Extensive experiments demonstrate that C-LoRA consistently outperforms the state-of-the-art uncertainty-aware LoRA methods in both uncertainty quantification and model generalization. Ablation studies further confirm the critical role of our contextual modules in capturing sample-specific uncertainties. C-LoRA sets a new standard for robust, uncertainty-aware LLM fine-tuning in few-shot regimes.
Uncertainty-Aware Adaptation of Large Language Models for Protein-Protein Interaction Analysis
Feb 10, 2025



Identification of protein-protein interactions (PPIs) helps derive cellular mechanistic understanding, particularly in the context of complex conditions such as neurodegenerative disorders, metabolic syndromes, and cancer. Large Language Models (LLMs) have demonstrated remarkable potential in predicting protein structures and interactions via automated mining of vast biomedical literature; yet their inherent uncertainty remains a key challenge for deriving reproducible findings, critical for biomedical applications. In this study, we present an uncertainty-aware adaptation of LLMs for PPI analysis, leveraging fine-tuned LLaMA-3 and BioMedGPT models. To enhance prediction reliability, we integrate LoRA ensembles and Bayesian LoRA models for uncertainty quantification (UQ), ensuring confidence-calibrated insights into protein behavior. Our approach achieves competitive performance in PPI identification across diverse disease contexts while addressing model uncertainty, thereby enhancing trustworthiness and reproducibility in computational biology. These findings underscore the potential of uncertainty-aware LLM adaptation for advancing precision medicine and biomedical research.
Epidemiological Model Calibration via Graybox Bayesian Optimization
Dec 10, 2024



In this study, we focus on developing efficient calibration methods via Bayesian decision-making for the family of compartmental epidemiological models. The existing calibration methods usually assume that the compartmental model is cheap in terms of its output and gradient evaluation, which may not hold in practice when extending them to more general settings. Therefore, we introduce model calibration methods based on a "graybox" Bayesian optimization (BO) scheme, more efficient calibration for general epidemiological models. This approach uses Gaussian processes as a surrogate to the expensive model, and leverages the functional structure of the compartmental model to enhance calibration performance. Additionally, we develop model calibration methods via a decoupled decision-making strategy for BO, which further exploits the decomposable nature of the functional structure. The calibration efficiencies of the multiple proposed schemes are evaluated based on various data generated by a compartmental model mimicking real-world epidemic processes, and real-world COVID-19 datasets. Experimental results demonstrate that our proposed graybox variants of BO schemes can efficiently calibrate computationally expensive models and further improve the calibration performance measured by the logarithm of mean square errors and achieve faster performance convergence in terms of BO iterations. We anticipate that the proposed calibration methods can be extended to enable fast calibration of more complex epidemiological models, such as the agent-based models.
Hyperparameter Tuning Through Pessimistic Bilevel Optimization
Dec 04, 2024



Automated hyperparameter search in machine learning, especially for deep learning models, is typically formulated as a bilevel optimization problem, with hyperparameter values determined by the upper level and the model learning achieved by the lower-level problem. Most of the existing bilevel optimization solutions either assume the uniqueness of the optimal training model given hyperparameters or adopt an optimistic view when the non-uniqueness issue emerges. Potential model uncertainty may arise when training complex models with limited data, especially when the uniqueness assumption is violated. Thus, the suitability of the optimistic view underlying current bilevel hyperparameter optimization solutions is questionable. In this paper, we propose pessimistic bilevel hyperparameter optimization to assure appropriate outer-level hyperparameters to better generalize the inner-level learned models, by explicitly incorporating potential uncertainty of the inner-level solution set. To solve the resulting computationally challenging pessimistic bilevel optimization problem, we develop a novel relaxation-based approximation method. It derives pessimistic solutions with more robust prediction models. In our empirical studies of automated hyperparameter search for binary linear classifiers, pessimistic solutions have demonstrated better prediction performances than optimistic counterparts when we have limited training data or perturbed testing data, showing the necessity of considering pessimistic solutions besides existing optimistic ones.
Path-Guided Particle-based Sampling
Dec 04, 2024

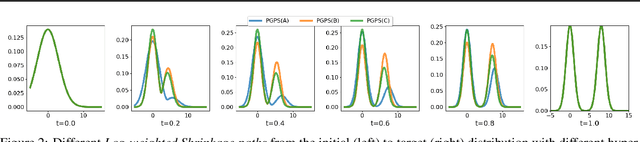

Particle-based Bayesian inference methods by sampling from a partition-free target (posterior) distribution, e.g., Stein variational gradient descent (SVGD), have attracted significant attention. We propose a path-guided particle-based sampling~(PGPS) method based on a novel Log-weighted Shrinkage (LwS) density path linking an initial distribution to the target distribution. We propose to utilize a Neural network to learn a vector field motivated by the Fokker-Planck equation of the designed density path. Particles, initiated from the initial distribution, evolve according to the ordinary differential equation defined by the vector field. The distribution of these particles is guided along a density path from the initial distribution to the target distribution. The proposed LwS density path allows for an efficient search of modes of the target distribution while canonical methods fail. We theoretically analyze the Wasserstein distance of the distribution of the PGPS-generated samples and the target distribution due to approximation and discretization errors. Practically, the proposed PGPS-LwS method demonstrates higher Bayesian inference accuracy and better calibration ability in experiments conducted on both synthetic and real-world Bayesian learning tasks, compared to baselines, such as SVGD and Langevin dynamics, etc.
LoRA-BERT: a Natural Language Processing Model for Robust and Accurate Prediction of long non-coding RNAs
Nov 11, 2024Long non-coding RNAs (lncRNAs) serve as crucial regulators in numerous biological processes. Although they share sequence similarities with messenger RNAs (mRNAs), lncRNAs perform entirely different roles, providing new avenues for biological research. The emergence of next-generation sequencing technologies has greatly advanced the detection and identification of lncRNA transcripts and deep learning-based approaches have been introduced to classify long non-coding RNAs (lncRNAs). These advanced methods have significantly enhanced the efficiency of identifying lncRNAs. However, many of these methods are devoid of robustness and accuracy due to the extended length of the sequences involved. To tackle this issue, we have introduced a novel pre-trained bidirectional encoder representation called LoRA-BERT. LoRA-BERT is designed to capture the importance of nucleotide-level information during sequence classification, leading to more robust and satisfactory outcomes. In a comprehensive comparison with commonly used sequence prediction tools, we have demonstrated that LoRA-BERT outperforms them in terms of accuracy and efficiency. Our results indicate that, when utilizing the transformer model, LoRA-BERT achieves state-of-the-art performance in predicting both lncRNAs and mRNAs for human and mouse species. Through the utilization of LoRA-BERT, we acquire valuable insights into the traits of lncRNAs and mRNAs, offering the potential to aid in the comprehension and detection of diseases linked to lncRNAs in humans.
Understanding Uncertainty-based Active Learning Under Model Mismatch
Aug 24, 2024



Instead of randomly acquiring training data points, Uncertainty-based Active Learning (UAL) operates by querying the label(s) of pivotal samples from an unlabeled pool selected based on the prediction uncertainty, thereby aiming at minimizing the labeling cost for model training. The efficacy of UAL critically depends on the model capacity as well as the adopted uncertainty-based acquisition function. Within the context of this study, our analytical focus is directed toward comprehending how the capacity of the machine learning model may affect UAL efficacy. Through theoretical analysis, comprehensive simulations, and empirical studies, we conclusively demonstrate that UAL can lead to worse performance in comparison with random sampling when the machine learning model class has low capacity and is unable to cover the underlying ground truth. In such situations, adopting acquisition functions that directly target estimating the prediction performance may be beneficial for improving the performance of UAL.