 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Augmented Few-Shot Neural Stencil Emulation for System Identification of Computer Models
Aug 26, 2025Partial differential equations (PDEs) underpin the modeling of many natural and engineered systems. It can be convenient to express such models as neural PDEs rather than using traditional numerical PDE solvers by replacing part or all of the PDE's governing equations with a neural network representation. Neural PDEs are often easier to differentiate, linearize, reduce, or use for uncertainty quantification than the original numerical solver. They are usually trained on solution trajectories obtained by long time integration of the PDE solver. Here we propose a more sample-efficient data-augmentation strategy for generating neural PDE training data from a computer model by space-filling sampling of local "stencil" states. This approach removes a large degree of spatiotemporal redundancy present in trajectory data and oversamples states that may be rarely visited but help the neural PDE generalize across the state space. We demonstrate that accurate neural PDE stencil operators can be learned from synthetic training data generated by the computational equivalent of 10 timesteps' worth of numerical simulation. Accuracy is further improved if we assume access to a single full-trajectory simulation from the computer model, which is typically available in practice. Across several PDE systems, we show that our data-augmented synthetic stencil data yield better trained neural stencil operators, with clear performance gains compared with naively sampled stencil data from simulation trajectories.
C-LoRA: Contextual Low-Rank Adaptation for Uncertainty Estimation in Large Language Models
May 23, 2025Low-Rank Adaptation (LoRA) offers a cost-effective solution for fine-tuning large language models (LLMs), but it often produces overconfident predictions in data-scarce few-shot settings. To address this issue, several classical statistical learning approaches have been repurposed for scalable uncertainty-aware LoRA fine-tuning. However, these approaches neglect how input characteristics affect the predictive uncertainty estimates. To address this limitation, we propose Contextual Low-Rank Adaptation (\textbf{C-LoRA}) as a novel uncertainty-aware and parameter efficient fine-tuning approach, by developing new lightweight LoRA modules contextualized to each input data sample to dynamically adapt uncertainty estimates. Incorporating data-driven contexts into the parameter posteriors, C-LoRA mitigates overfitting, achieves well-calibrated uncertainties, and yields robust predictions. Extensive experiments demonstrate that C-LoRA consistently outperforms the state-of-the-art uncertainty-aware LoRA methods in both uncertainty quantification and model generalization. Ablation studies further confirm the critical role of our contextual modules in capturing sample-specific uncertainties. C-LoRA sets a new standard for robust, uncertainty-aware LLM fine-tuning in few-shot regimes.
Uncertainty-Aware Adaptation of Large Language Models for Protein-Protein Interaction Analysis
Feb 10, 2025



Identification of protein-protein interactions (PPIs) helps derive cellular mechanistic understanding, particularly in the context of complex conditions such as neurodegenerative disorders, metabolic syndromes, and cancer. Large Language Models (LLMs) have demonstrated remarkable potential in predicting protein structures and interactions via automated mining of vast biomedical literature; yet their inherent uncertainty remains a key challenge for deriving reproducible findings, critical for biomedical applications. In this study, we present an uncertainty-aware adaptation of LLMs for PPI analysis, leveraging fine-tuned LLaMA-3 and BioMedGPT models. To enhance prediction reliability, we integrate LoRA ensembles and Bayesian LoRA models for uncertainty quantification (UQ), ensuring confidence-calibrated insights into protein behavior. Our approach achieves competitive performance in PPI identification across diverse disease contexts while addressing model uncertainty, thereby enhancing trustworthiness and reproducibility in computational biology. These findings underscore the potential of uncertainty-aware LLM adaptation for advancing precision medicine and biomedical research.
Enhancing Generative Molecular Design via Uncertainty-guided Fine-tuning of Variational Autoencoders
May 31, 2024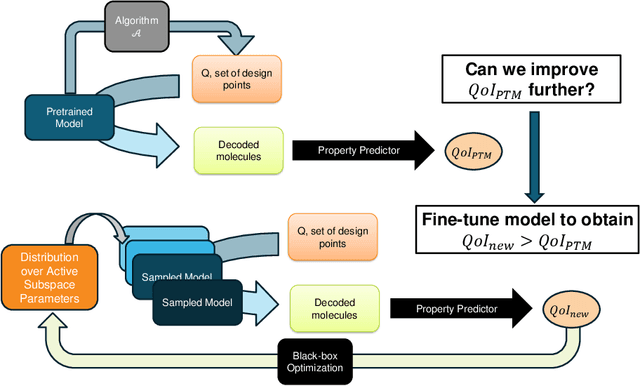
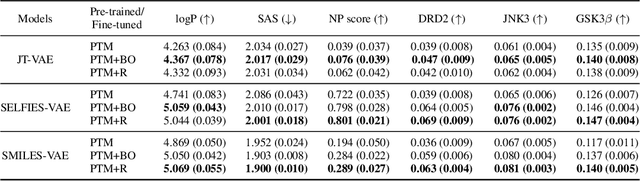
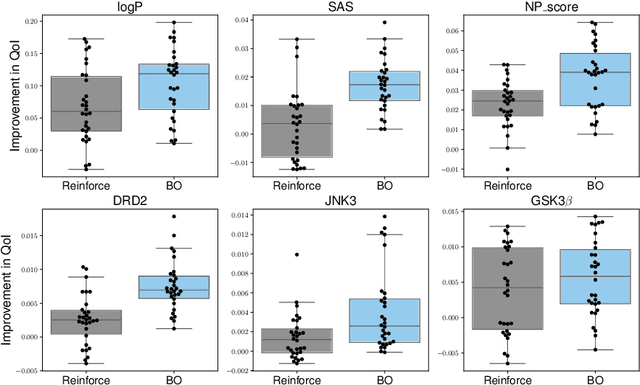
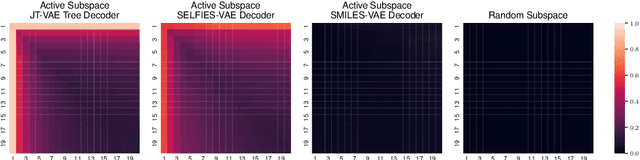
In recent years, deep generative models have been successfully adopted for various molecular design tasks, particularly in the life and material sciences. A critical challenge for pre-trained generative molecular design (GMD) models is to fine-tune them to be better suited for downstream design tasks aimed at optimizing specific molecular properties. However, redesigning and training an existing effective generative model from scratch for each new design task is impractical. Furthermore, the black-box nature of typical downstream tasks$\unicode{x2013}$such as property prediction$\unicode{x2013}$makes it nontrivial to optimize the generative model in a task-specific manner. In this work, we propose a novel approach for a model uncertainty-guided fine-tuning of a pre-trained variational autoencoder (VAE)-based GMD model through performance feedback in an active learning setting. The main idea is to quantify model uncertainty in the generative model, which is made efficient by working within a low-dimensional active subspace of the high-dimensional VAE parameters explaining most of the variability in the model's output. The inclusion of model uncertainty expands the space of viable molecules through decoder diversity. We then explore the resulting model uncertainty class via black-box optimization made tractable by low-dimensionality of the active subspace. This enables us to identify and leverage a diverse set of high-performing models to generate enhanced molecules. Empirical results across six target molecular properties, using multiple VAE-based generative models, demonstrate that our uncertainty-guided fine-tuning approach consistently outperforms the original pre-trained models.
Leveraging Active Subspaces to Capture Epistemic Model Uncertainty in Deep Generative Models for Molecular Design
Apr 30, 2024


Deep generative models have been accelerating the inverse design process in material and drug design. Unlike their counterpart property predictors in typical molecular design frameworks, generative molecular design models have seen fewer efforts on uncertainty quantification (UQ) due to computational challenges in Bayesian inference posed by their large number of parameters. In this work, we focus on the junction-tree variational autoencoder (JT-VAE), a popular model for generative molecular design, and address this issue by leveraging the low dimensional active subspace to capture the uncertainty in the model parameters. Specifically, we approximate the posterior distribution over the active subspace parameters to estimate the epistemic model uncertainty in an extremely high dimensional parameter space. The proposed UQ scheme does not require alteration of the model architecture, making it readily applicable to any pre-trained model. Our experiments demonstrate the efficacy of the AS-based UQ and its potential impact on molecular optimization by exploring the model diversity under epistemic uncertainty.
Learning Active Subspaces for Effective and Scalable Uncertainty Quantification in Deep Neural Networks
Sep 06, 2023



Bayesian inference for neural networks, or Bayesian deep learning, has the potential to provide well-calibrated predictions with quantified uncertainty and robustness. However, the main hurdle for Bayesian deep learning is its computational complexity due to the high dimensionality of the parameter space. In this work, we propose a novel scheme that addresses this limitation by constructing a low-dimensional subspace of the neural network parameters-referred to as an active subspace-by identifying the parameter directions that have the most significant influence on the output of the neural network. We demonstrate that the significantly reduced active subspace enables effective and scalable Bayesian inference via either Monte Carlo (MC) sampling methods, otherwise computationally intractable, or variational inference. Empirically, our approach provides reliable predictions with robust uncertainty estimates for various regression tasks.
A comprehensive study of spike and slab shrinkage priors for structurally sparse Bayesian neural networks
Aug 17, 2023



Network complexity and computational efficiency have become increasingly significant aspects of deep learning. Sparse deep learning addresses these challenges by recovering a sparse representation of the underlying target function by reducing heavily over-parameterized deep neural networks. Specifically, deep neural architectures compressed via structured sparsity (e.g. node sparsity) provide low latency inference, higher data throughput, and reduced energy consumption. In this paper, we explore two well-established shrinkage techniques, Lasso and Horseshoe, for model compression in Bayesian neural networks. To this end, we propose structurally sparse Bayesian neural networks which systematically prune excessive nodes with (i) Spike-and-Slab Group Lasso (SS-GL), and (ii) Spike-and-Slab Group Horseshoe (SS-GHS) priors, and develop computationally tractable variational inference including continuous relaxation of Bernoulli variables. We establish the contraction rates of the variational posterior of our proposed models as a function of the network topology, layer-wise node cardinalities, and bounds on the network weights. We empirically demonstrate the competitive performance of our models compared to the baseline models in prediction accuracy, model compression, and inference latency.
ClimSim: An open large-scale dataset for training high-resolution physics emulators in hybrid multi-scale climate simulators
Jun 16, 2023Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise prediction of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.
Unified Probabilistic Neural Architecture and Weight Ensembling Improves Model Robustness
Oct 08, 2022

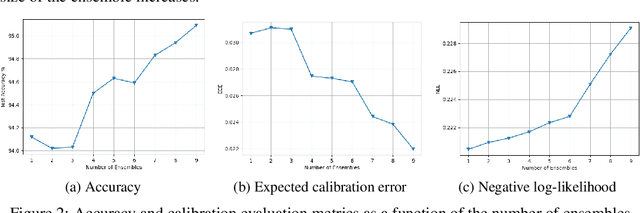
Robust machine learning models with accurately calibrated uncertainties are crucial for safety-critical applications. Probabilistic machine learning and especially the Bayesian formalism provide a systematic framework to incorporate robustness through the distributional estimates and reason about uncertainty. Recent works have shown that approximate inference approaches that take the weight space uncertainty of neural networks to generate ensemble prediction are the state-of-the-art. However, architecture choices have mostly been ad hoc, which essentially ignores the epistemic uncertainty from the architecture space. To this end, we propose a Unified probabilistic architecture and weight ensembling Neural Architecture Search (UraeNAS) that leverages advances in probabilistic neural architecture search and approximate Bayesian inference to generate ensembles form the joint distribution of neural network architectures and weights. The proposed approach showed a significant improvement both with in-distribution (0.86% in accuracy, 42% in ECE) CIFAR-10 and out-of-distribution (2.43% in accuracy, 30% in ECE) CIFAR-10-C compared to the baseline deterministic approach.
Sequential Bayesian Neural Subnetwork Ensembles
Jun 01, 2022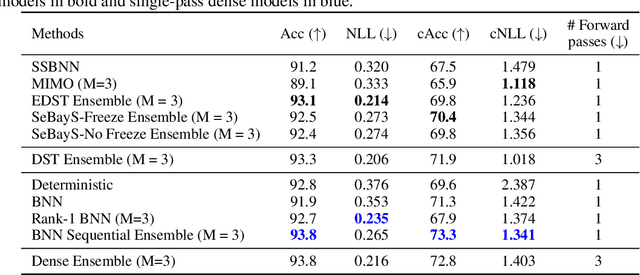
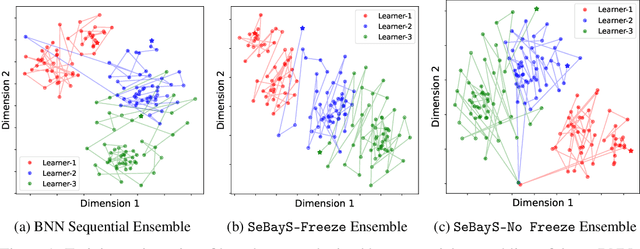
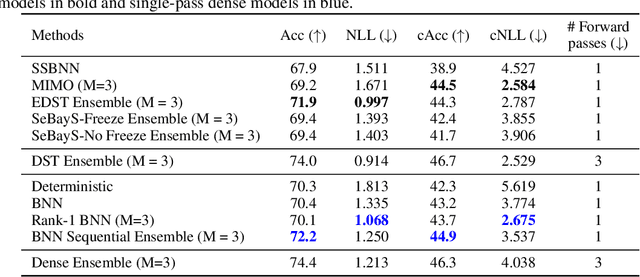
Deep neural network ensembles that appeal to model diversity have been used successfully to improve predictive performance and model robustness in several applications. Whereas, it has recently been shown that sparse subnetworks of dense models can match the performance of their dense counterparts and increase their robustness while effectively decreasing the model complexity. However, most ensembling techniques require multiple parallel and costly evaluations and have been proposed primarily with deterministic models, whereas sparsity induction has been mostly done through ad-hoc pruning. We propose sequential ensembling of dynamic Bayesian neural subnetworks that systematically reduce model complexity through sparsity-inducing priors and generate diverse ensembles in a single forward pass of the model. The ensembling strategy consists of an exploration phase that finds high-performing regions of the parameter space and multiple exploitation phases that effectively exploit the compactness of the sparse model to quickly converge to different minima in the energy landscape corresponding to high-performing subnetworks yielding diverse ensembles. We empirically demonstrate that our proposed approach surpasses the baselines of the dense frequentist and Bayesian ensemble models in prediction accuracy, uncertainty estimation, and out-of-distribution (OoD) robustness on CIFAR10, CIFAR100 datasets, and their out-of-distribution variants: CIFAR10-C, CIFAR100-C induced by corruptions. Furthermore, we found that our approach produced the most diverse ensembles compared to the approaches with a single forward pass and even compared to the approaches with multiple forward passes in some cases.