 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer Adaptive Node Selection in Bayesian Neural Networks: Statistical Guarantees and Implementation Details
Paper and Code
Aug 25, 2021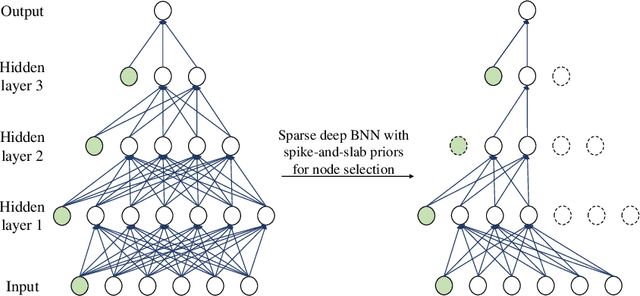
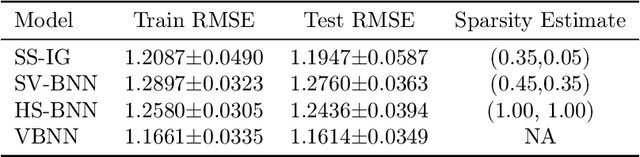
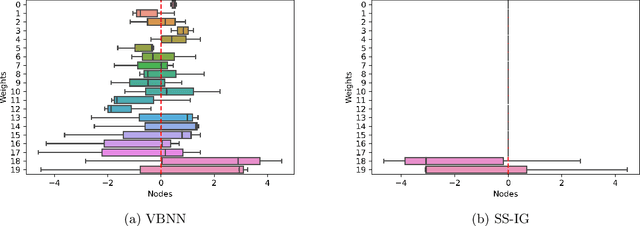

Sparse deep neural networks have proven to be efficient for predictive model building in large-scale studies. Although several works have studied theoretical and numerical properties of sparse neural architectures, they have primarily focused on the edge selection. Sparsity through edge selection might be intuitively appealing; however, it does not necessarily reduce the structural complexity of a network. Instead pruning excessive nodes in each layer leads to a structurally sparse network which would have lower computational complexity and memory footprint. We propose a Bayesian sparse solution using spike-and-slab Gaussian priors to allow for node selection during training. The use of spike-and-slab prior alleviates the need of an ad-hoc thresholding rule for pruning redundant nodes from a network. In addition, we adopt a variational Bayes approach to circumvent the computational challenges of traditional Markov Chain Monte Carlo (MCMC) implementation. In the context of node selection, we establish the fundamental result of variational posterior consistency together with the characterization of prior parameters. In contrast to the previous works, our theoretical development relaxes the assumptions of the equal number of nodes and uniform bounds on all network weights, thereby accommodating sparse networks with layer-dependent node structures or coefficient bounds. With a layer-wise characterization of prior inclusion probabilities, we also discuss optimal contraction rates of the variational posterior. Finally, we provide empirical evidence to substantiate that our theoretical work facilitates layer-wise optimal node recovery together with competitive predictive performance.