 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Integration Kernels for Interpretable Nonlocal Operator Learning
Mar 11, 2026Machine learning models can represent climate processes that are nonlocal in horizontal space, height, and time, often by combining information across these dimensions in highly nonlinear ways. While this can improve predictive skill, it makes learned relationships difficult to interpret and prone to overfitting as the extent of nonlocal information grows. We address this challenge by introducing data-driven integration kernels, a framework that adds structure to nonlocal operator learning by explicitly separating nonlocal information aggregation from local nonlinear prediction. Each spatiotemporal predictor field is first integrated using learnable kernels (defined as continuous weighting functions over horizontal space, height, and/or time), after which a local nonlinear mapping is applied only to the resulting kernel-integrated features and any optional local inputs. This design confines nonlinear interactions to a small set of integrated features and makes each kernel directly interpretable as a weighting pattern that reveals which horizontal locations, vertical levels, and past timesteps contribute most to the prediction. We demonstrate the framework for South Asian monsoon precipitation using a hierarchy of neural network models with increasing structure, including baseline, nonparametric kernel, and parametric kernel models. Across this hierarchy, kernel-based models achieve near-baseline performance with far fewer trainable parameters, showing that much of the relevant nonlocal information can be captured through a small set of interpretable integrations when appropriate structural constraints are imposed.
BakuFlow: A Streamlining Semi-Automatic Label Generation Tool
Jun 10, 2025

Accurately labeling (or annotation) data is still a bottleneck in computer vision, especially for large-scale tasks where manual labeling is time-consuming and error-prone. While tools like LabelImg can handle the labeling task, some of them still require annotators to manually label each image. In this paper, we introduce BakuFlow, a streamlining semi-automatic label generation tool. Key features include (1) a live adjustable magnifier for pixel-precise manual corrections, improving user experience; (2) an interactive data augmentation module to diversify training datasets; (3) label propagation for rapidly copying labeled objects between consecutive frames, greatly accelerating annotation of video data; and (4) an automatic labeling module powered by a modified YOLOE framework. Unlike the original YOLOE, our extension supports adding new object classes and any number of visual prompts per class during annotation, enabling flexible and scalable labeling for dynamic, real-world datasets. These innovations make BakuFlow especially effective for object detection and tracking, substantially reducing labeling workload and improving efficiency in practical computer vision and industrial scenarios.
Systematic Sampling and Validation of Machine Learning-Parameterizations in Climate Models
Sep 28, 2023Progress in hybrid physics-machine learning (ML) climate simulations has been limited by the difficulty of obtaining performant coupled (i.e. online) simulations. While evaluating hundreds of ML parameterizations of subgrid closures (here of convection and radiation) offline is straightforward, online evaluation at the same scale is technically challenging. Our software automation achieves an order-of-magnitude larger sampling of online modeling errors than has previously been examined. Using this, we evaluate the hybrid climate model performance and define strategies to improve it. We show that model online performance improves when incorporating memory, a relative humidity input feature transformation, and additional input variables. We also reveal substantial variation in online error and inconsistencies between offline vs. online error statistics. The implication is that hundreds of candidate ML models should be evaluated online to detect the effects of parameterization design choices. This is considerably more sampling than tends to be reported in the current literature.
ClimSim: An open large-scale dataset for training high-resolution physics emulators in hybrid multi-scale climate simulators
Jun 16, 2023Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise prediction of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.
An Automated Evaluation Metric for Chinese Text Entry
Apr 27, 2007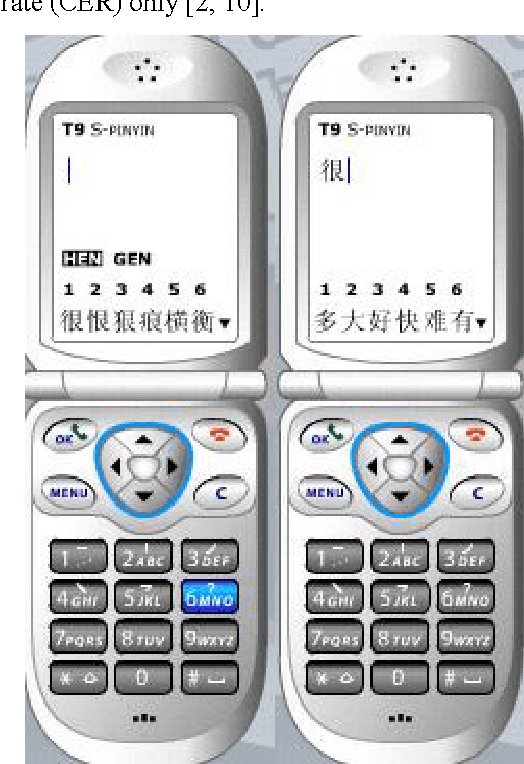

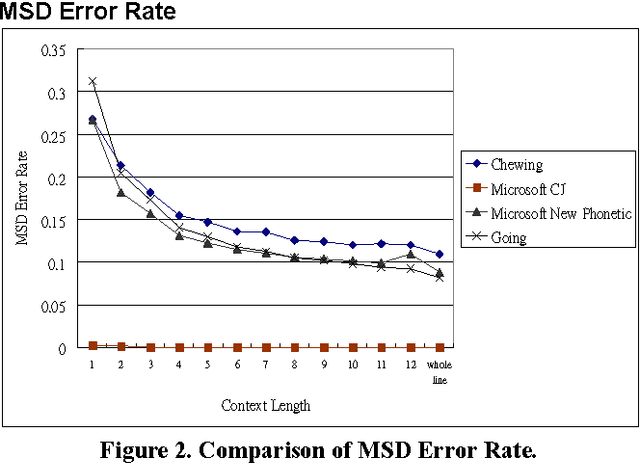

In this paper, we propose an automated evaluation metric for text entry. We also consider possible improvements to existing text entry evaluation metrics, such as the minimum string distance error rate, keystrokes per character, cost per correction, and a unified approach proposed by MacKenzie, so they can accommodate the special characteristics of Chinese text. Current methods lack an integrated concern about both typing speed and accuracy for Chinese text entry evaluation. Our goal is to remove the bias that arises due to human factors. First, we propose a new metric, called the correction penalty (P), based on Fitts' law and Hick's law. Next, we transform it into the approximate amortized cost (AAC) of information theory. An analysis of the AAC of Chinese text input methods with different context lengths is also presented.
* 8 pages