 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards accurate extreme event likelihoods from diffusion model climate emulators
May 05, 2026ML climate model emulators are useful for scenario planning and adaptation, allowing for cost-efficient experimentation. Recently, the diffusion model Climate in a Bottle (cBottle) has been proposed for generation of atmospheric states compatible with boundary conditions of solar position and sea surface temperatures. Crucially, cBottle can be guided to generate extreme events such as Tropical Cyclones (TCs) over locations of interest. Diffusion models such as cBottle work by approximating the probability density of the training data. Here, we show use cases of the probability density estimates of atmospheric states obtained from this climate emulator. Most importantly, these estimates allow us to calculate likelihoods of extreme events under guidance. When guiding the model towards states including TCs, comparing the probability density under the guided and unguided model enables us to quantify how much more likely the guidance has made the TC. We show how these odds ratios allow us to importance-sample from the TC distribution, reducing the standard error of the probability estimate compared to simple Monte Carlo sampling. Furthermore, we discuss results and limitations of the application of model probability densities to extreme event attribution-like experiments. We present these early but encouraging results hoping they will spur more research into probabilistic information that can be gained from diffusion models of the atmosphere.
Demystifying Data-Driven Probabilistic Medium-Range Weather Forecasting
Jan 26, 2026The recent revolution in data-driven methods for weather forecasting has lead to a fragmented landscape of complex, bespoke architectures and training strategies, obscuring the fundamental drivers of forecast accuracy. Here, we demonstrate that state-of-the-art probabilistic skill requires neither intricate architectural constraints nor specialized training heuristics. We introduce a scalable framework for learning multi-scale atmospheric dynamics by combining a directly downsampled latent space with a history-conditioned local projector that resolves high-resolution physics. We find that our framework design is robust to the choice of probabilistic estimator, seamlessly supporting stochastic interpolants, diffusion models, and CRPS-based ensemble training. Validated against the Integrated Forecasting System and the deep learning probabilistic model GenCast, our framework achieves statistically significant improvements on most of the variables. These results suggest scaling a general-purpose model is sufficient for state-of-the-art medium-range prediction, eliminating the need for tailored training recipes and proving effective across the full spectrum of probabilistic frameworks.
Generative Data Assimilation of Sparse Weather Station Observations at Kilometer Scales
Jun 19, 2024



Data assimilation of observational data into full atmospheric states is essential for weather forecast model initialization. Recently, methods for deep generative data assimilation have been proposed which allow for using new input data without retraining the model. They could also dramatically accelerate the costly data assimilation process used in operational regional weather models. Here, in a central US testbed, we demonstrate the viability of score-based data assimilation in the context of realistically complex km-scale weather. We train an unconditional diffusion model to generate snapshots of a state-of-the-art km-scale analysis product, the High Resolution Rapid Refresh. Then, using score-based data assimilation to incorporate sparse weather station data, the model produces maps of precipitation and surface winds. The generated fields display physically plausible structures, such as gust fronts, and sensitivity tests confirm learnt physics through multivariate relationships. Preliminary skill analysis shows the approach already outperforms a naive baseline of the High-Resolution Rapid Refresh system itself. By incorporating observations from 40 weather stations, 10\% lower RMSEs on left-out stations are attained. Despite some lingering imperfections such as insufficiently disperse ensemble DA estimates, we find the results overall an encouraging proof of concept, and the first at km-scale. It is a ripe time to explore extensions that combine increasingly ambitious regional state generators with an increasing set of in situ, ground-based, and satellite remote sensing data streams.
DiffObs: Generative Diffusion for Global Forecasting of Satellite Observations
Apr 04, 2024



This work presents an autoregressive generative diffusion model (DiffObs) to predict the global evolution of daily precipitation, trained on a satellite observational product, and assessed with domain-specific diagnostics. The model is trained to probabilistically forecast day-ahead precipitation. Nonetheless, it is stable for multi-month rollouts, which reveal a qualitatively realistic superposition of convectively coupled wave modes in the tropics. Cross-spectral analysis confirms successful generation of low frequency variations associated with the Madden--Julian oscillation, which regulates most subseasonal to seasonal predictability in the observed atmosphere, and convectively coupled moist Kelvin waves with approximately correct dispersion relationships. Despite secondary issues and biases, the results affirm the potential for a next generation of global diffusion models trained on increasingly sparse, and increasingly direct and differentiated observations of the world, for practical applications in subseasonal and climate prediction.
Systematic Sampling and Validation of Machine Learning-Parameterizations in Climate Models
Sep 28, 2023Progress in hybrid physics-machine learning (ML) climate simulations has been limited by the difficulty of obtaining performant coupled (i.e. online) simulations. While evaluating hundreds of ML parameterizations of subgrid closures (here of convection and radiation) offline is straightforward, online evaluation at the same scale is technically challenging. Our software automation achieves an order-of-magnitude larger sampling of online modeling errors than has previously been examined. Using this, we evaluate the hybrid climate model performance and define strategies to improve it. We show that model online performance improves when incorporating memory, a relative humidity input feature transformation, and additional input variables. We also reveal substantial variation in online error and inconsistencies between offline vs. online error statistics. The implication is that hundreds of candidate ML models should be evaluated online to detect the effects of parameterization design choices. This is considerably more sampling than tends to be reported in the current literature.
Generative Residual Diffusion Modeling for Km-scale Atmospheric Downscaling
Sep 28, 2023The state of the art for physical hazard prediction from weather and climate requires expensive km-scale numerical simulations driven by coarser resolution global inputs. Here, a km-scale downscaling diffusion model is presented as a cost effective alternative. The model is trained from a regional high-resolution weather model over Taiwan, and conditioned on ERA5 reanalysis data. To address the downscaling uncertainties, large resolution ratios (25km to 2km), different physics involved at different scales and predict channels that are not in the input data, we employ a two-step approach (\textit{ResDiff}) where a (UNet) regression predicts the mean in the first step and a diffusion model predicts the residual in the second step. \textit{ResDiff} exhibits encouraging skill in bulk RMSE and CRPS scores. The predicted spectra and distributions from ResDiff faithfully recover important power law relationships regulating damaging wind and rain extremes. Case studies of coherent weather phenomena reveal appropriate multivariate relationships reminiscent of learnt physics. This includes the sharp wind and temperature variations that co-locate with intense rainfall in a cold front, and the extreme winds and rainfall bands that surround the eyewall of typhoons. Some evidence of simultaneous bias correction is found. A first attempt at downscaling directly from an operational global forecast model successfully retains many of these benefits. The implication is that a new era of fully end-to-end, global-to-regional machine learning weather prediction is likely near at hand.
Two-step hyperparameter optimization method: Accelerating hyperparameter search by using a fraction of a training dataset
Feb 08, 2023


Hyperparameter optimization (HPO) can be an important step in machine learning model development, but our common practice is archaic -- primarily using a manual or grid search. This is partly because adopting an advanced HPO algorithm entails extra complexity to workflow and longer computation time. This imposes a significant hurdle to machine learning (ML) applications since the choice of suboptimal hyperparameters limits the performance of ML models, ultimately failing to harness the full potential of ML techniques. In this article, we present a two-step HPO method as a strategy to minimize compute and wait time as a lesson learned during applied ML parameterization work. A preliminary evaluation of hyperparameters is first conducted on a small subset of a training dataset, then top-performing candidate models are re-evaluated after retraining with an entire training dataset. This two-step HPO method can be applied to any HPO search algorithm, and we argue it has attractive efficiencies. As a case study, we present our recent application of the two-step HPO method to the development of neural network emulators of aerosol activation. Using only 5% of a training dataset in the initial step is sufficient to find optimal hyperparameter configurations from much more extensive sampling. The benefits of HPO are then revealed by analysis of hyperparameters and model performance, revealing a minimal model complexity required to achieve the best performance, and the diversity of top-performing models harvested from the HPO process allows us to choose a high-performing model with a low inference cost for efficient use in GCMs.
Analyzing High-Resolution Clouds and Convection using Multi-Channel VAEs
Dec 01, 2021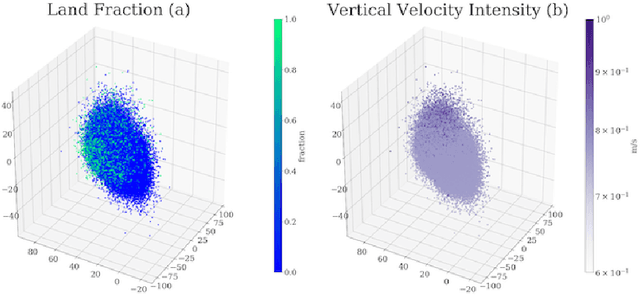
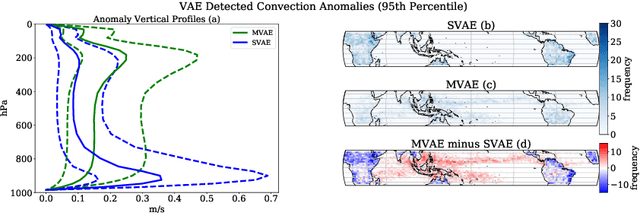
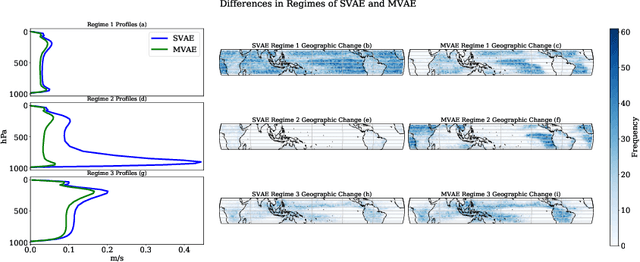
Understanding the details of small-scale convection and storm formation is crucial to accurately represent the larger-scale planetary dynamics. Presently, atmospheric scientists run high-resolution, storm-resolving simulations to capture these kilometer-scale weather details. However, because they contain abundant information, these simulations can be overwhelming to analyze using conventional approaches. This paper takes a data-driven approach and jointly embeds spatial arrays of vertical wind velocities, temperatures, and water vapor information as three "channels" of a VAE architecture. Our "multi-channel VAE" results in more interpretable and robust latent structures than earlier work analyzing vertical velocities in isolation. Analyzing and clustering the VAE's latent space identifies weather patterns and their geographical manifestations in a fully unsupervised fashion. Our approach shows that VAEs can play essential roles in analyzing high-dimensional simulation data and extracting critical weather and climate characteristics.
A Fortran-Keras Deep Learning Bridge for Scientific Computing
Apr 14, 2020

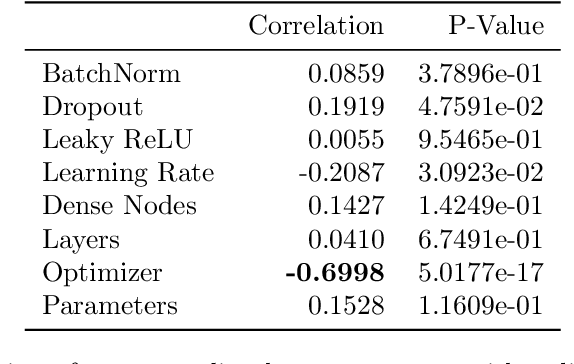
Implementing artificial neural networks is commonly achieved via high-level programming languages like Python, and easy-to-use deep learning libraries like Keras. These software libraries come pre-loaded with a variety of network architectures, provide autodifferentiation, and support GPUs for fast and efficient computation. As a result, a deep learning practitioner will favor training a neural network model in Python where these tools are readily available. However, many large-scale scientific computation projects are written in Fortran, which makes them difficult to integrate with modern deep learning methods. To alleviate this problem, we introduce a software library, the Fortran-Keras Bridge (FKB). This two-way bridge connects environments where deep learning resources are plentiful, with those where they are scarce. The paper describes a number of unique features offered by FKB, such as customizable layers, loss functions, and network ensembles. The paper concludes with a case study that applies FKB to address open questions about the robustness of an experimental approach to global climate simulation, in which subgrid physics are outsourced to deep neural network emulators. In this context, FKB enables a hyperparameter search of one hundred plus candidate models of subgrid cloud and radiation physics, initially implemented in Keras, to then be transferred and used in Fortran to assess their emergent behavior, i.e. when fit imperfections are coupled to explicit planetary scale fluid dynamics. The results reveal a previously unrecognized strong relationship between offline validation error and online performance, in which the choice of optimizer proves unexpectedly critical; this in turn helps identify a new optimized NN that demonstrates a 500 fold improvement of model stability compared to previously published results for this application.