 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Pulmonary Coccidioidomycosis (Valley fever) with Deep Convolutional Neural Networks
Jan 30, 2021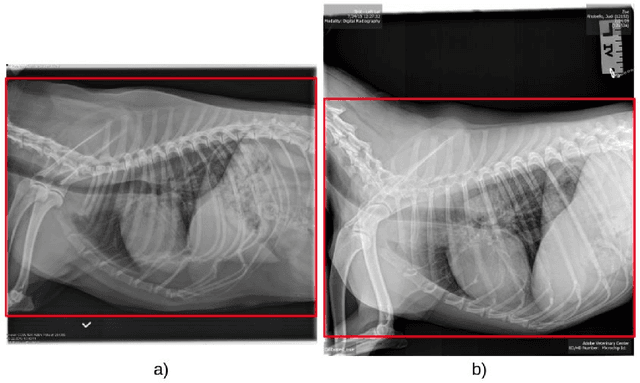

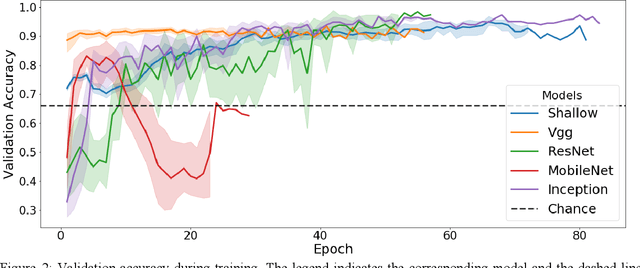
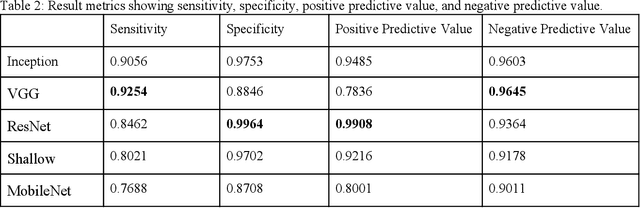
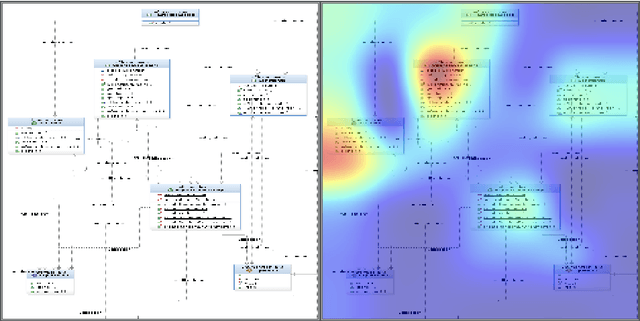
Coccidioidomycosis is the most common systemic mycosis in dogs in the southwestern United States. With warming climates, affected areas and number of cases are expected to increase in the coming years, escalating also the chances of transmission to humans. As a result, developing methods for automating the detection of the disease is important, as this will help doctors and veterinarians more easily identify and diagnose positive cases. We apply machine learning models to provide accurate and interpretable predictions of Coccidioidomycosis. We assemble a set of radiographic images and use it to train and test state-of-the-art convolutional neural networks to detect Coccidioidomycosis. These methods are relatively inexpensive to train and very fast at inference time. We demonstrate the successful application of this approach to detect the disease with an Area Under the Curve (AUC) above 0.99 using 10-fold cross validation. We also use the classification model to identify regions of interest and localize the disease in the radiographic images, as illustrated through visual heatmaps. This proof-of-concept study establishes the feasibility of very accurate and rapid automated detection of Valley Fever in radiographic images.
Deep-Learning-Based Kinematic Reconstruction for DUNE
Dec 14, 2020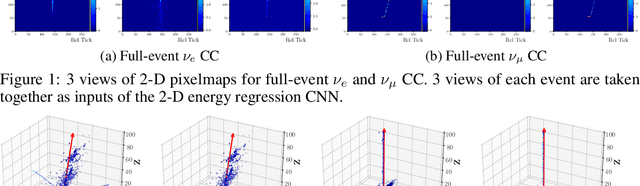

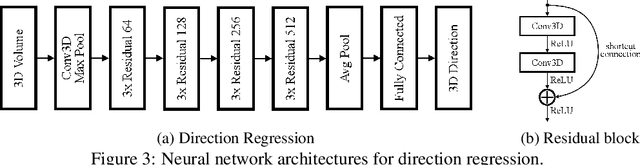
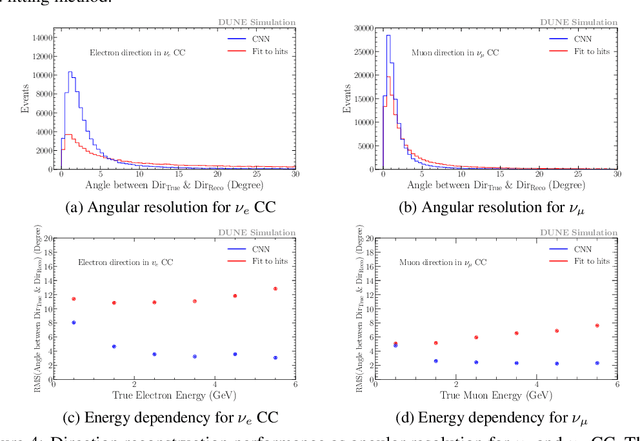
In the framework of three-active-neutrino mixing, the charge parity phase, the neutrino mass ordering, and the octant of $\theta_{23}$ remain unknown. The Deep Underground Neutrino Experiment (DUNE) is a next-generation long-baseline neutrino oscillation experiment, which aims to address these questions by measuring the oscillation patterns of $\nu_\mu/\nu_e$ and $\bar\nu_\mu/\bar\nu_e$ over a range of energies spanning the first and second oscillation maxima. DUNE far detector modules are based on liquid argon TPC (LArTPC) technology. A LArTPC offers excellent spatial resolution, high neutrino detection efficiency, and superb background rejection, while reconstruction in LArTPC is challenging. Deep learning methods, in particular, Convolutional Neural Networks (CNNs), have demonstrated success in classification problems such as particle identification in DUNE and other neutrino experiments. However, reconstruction of neutrino energy and final state particle momenta with deep learning methods is yet to be developed for a full AI-based reconstruction chain. To precisely reconstruct these kinematic characteristics of detected interactions at DUNE, we have developed and will present two CNN-based methods, 2-D and 3-D, for the reconstruction of final state particle direction and energy, as well as neutrino energy. Combining particle masses with the kinetic energy and the direction reconstructed by our work, the four-momentum of final state particles can be obtained. Our models show considerable improvements compared to the traditional methods for both scenarios.
Sherpa: Robust Hyperparameter Optimization for Machine Learning
May 08, 2020
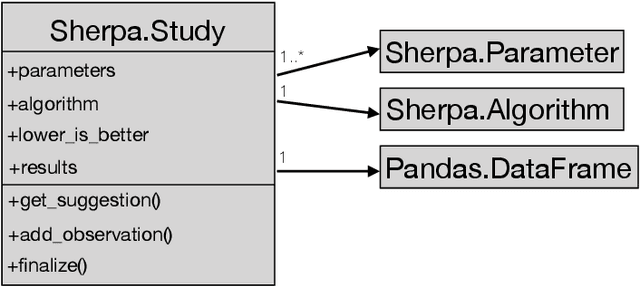
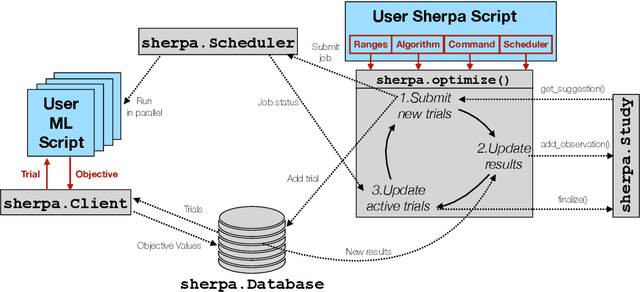
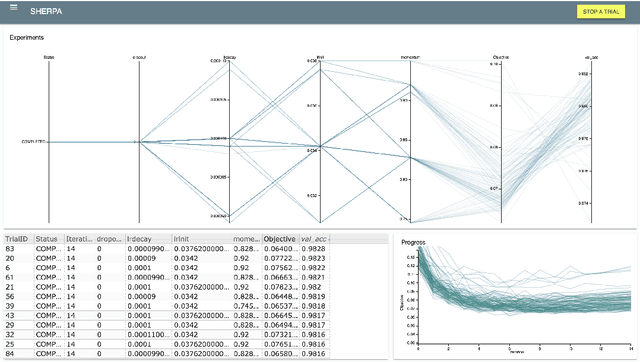
Sherpa is a hyperparameter optimization library for machine learning models. It is specifically designed for problems with computationally expensive, iterative function evaluations, such as the hyperparameter tuning of deep neural networks. With Sherpa, scientists can quickly optimize hyperparameters using a variety of powerful and interchangeable algorithms. Sherpa can be run on either a single machine or in parallel on a cluster. Finally, an interactive dashboard enables users to view the progress of models as they are trained, cancel trials, and explore which hyperparameter combinations are working best. Sherpa empowers machine learning practitioners by automating the more tedious aspects of model tuning. Its source code and documentation are available at https://github.com/sherpa-ai/sherpa.
A Fortran-Keras Deep Learning Bridge for Scientific Computing
Apr 14, 2020

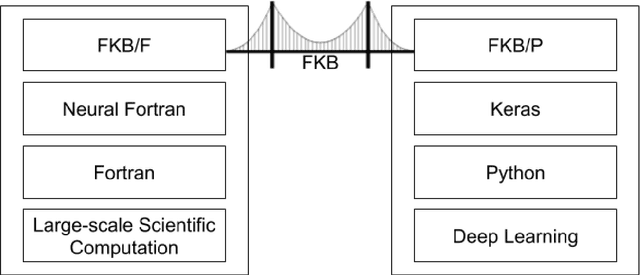
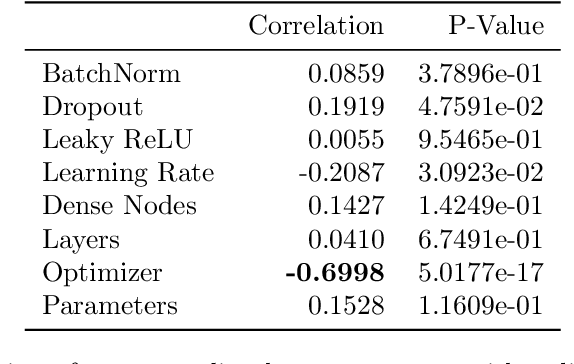
Implementing artificial neural networks is commonly achieved via high-level programming languages like Python, and easy-to-use deep learning libraries like Keras. These software libraries come pre-loaded with a variety of network architectures, provide autodifferentiation, and support GPUs for fast and efficient computation. As a result, a deep learning practitioner will favor training a neural network model in Python where these tools are readily available. However, many large-scale scientific computation projects are written in Fortran, which makes them difficult to integrate with modern deep learning methods. To alleviate this problem, we introduce a software library, the Fortran-Keras Bridge (FKB). This two-way bridge connects environments where deep learning resources are plentiful, with those where they are scarce. The paper describes a number of unique features offered by FKB, such as customizable layers, loss functions, and network ensembles. The paper concludes with a case study that applies FKB to address open questions about the robustness of an experimental approach to global climate simulation, in which subgrid physics are outsourced to deep neural network emulators. In this context, FKB enables a hyperparameter search of one hundred plus candidate models of subgrid cloud and radiation physics, initially implemented in Keras, to then be transferred and used in Fortran to assess their emergent behavior, i.e. when fit imperfections are coupled to explicit planetary scale fluid dynamics. The results reveal a previously unrecognized strong relationship between offline validation error and online performance, in which the choice of optimizer proves unexpectedly critical; this in turn helps identify a new optimized NN that demonstrates a 500 fold improvement of model stability compared to previously published results for this application.
Giving Up Control: Neurons as Reinforcement Learning Agents
Mar 17, 2020

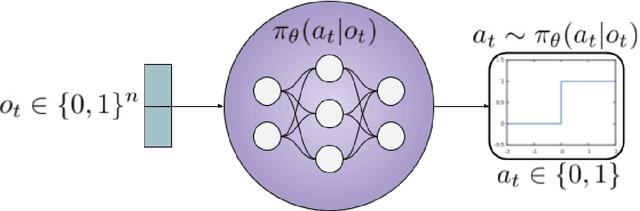

Artificial Intelligence has historically relied on planning, heuristics, and handcrafted approaches designed by experts. All the while claiming to pursue the creation of Intelligence. This approach fails to acknowledge that intelligence emerges from the dynamics within a complex system. Neurons in the brain are governed by local rules, where no single neuron, or group of neurons, coordinates or controls the others. This local structure gives rise to the appropriate dynamics in which intelligence can emerge. Populations of neurons must compete with their neighbors for resources, inhibition, and activity representation. At the same time, they must cooperate, so the population and organism can perform high-level functions. To this end, we introduce modeling neurons as reinforcement learning agents. Where each neuron may be viewed as an independent actor, trying to maximize its own self-interest. By framing learning in this way, we open the door to an entirely new approach to building intelligent systems.
Exploring the Efficacy of Transfer Learning in Mining Image-Based Software Artifacts
Mar 03, 2020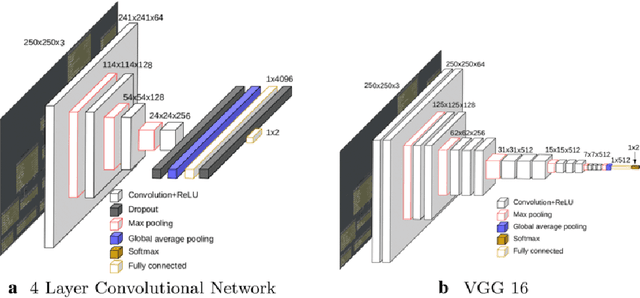
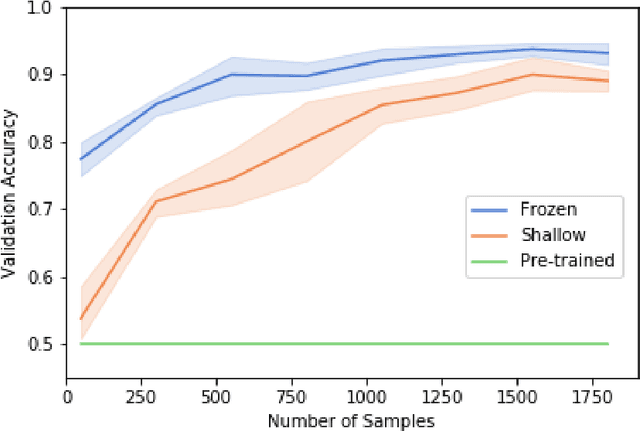
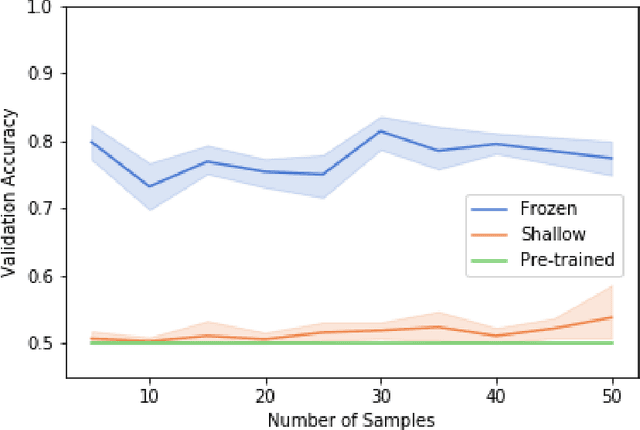
Transfer learning allows us to train deep architectures requiring a large number of learned parameters, even if the amount of available data is limited, by leveraging existing models previously trained for another task. Here we explore the applicability of transfer learning utilizing models pre-trained on non-software engineering data applied to the problem of classifying software UML diagrams. Our experimental results show training reacts positively to transfer learning as related to sample size, even though the pre-trained model was not exposed to training instances from the software domain. We contrast the transferred network with other networks to show its advantage on different sized training sets, which indicates that transfer learning is equally effective to custom deep architectures when large amounts of training data is not available.
Questions to Guide the Future of Artificial Intelligence Research
Dec 21, 2019
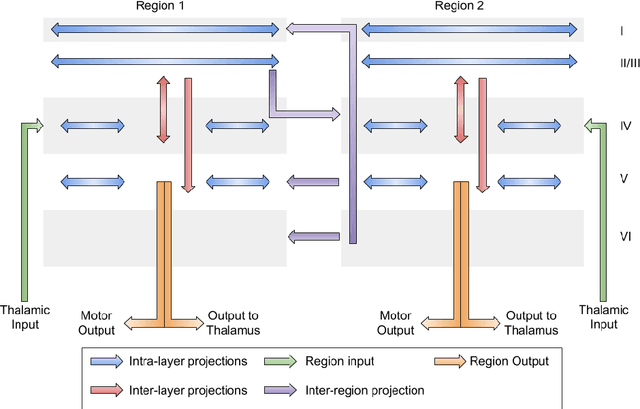
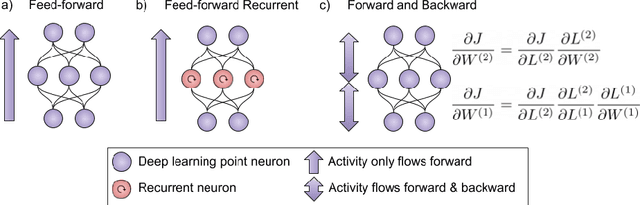
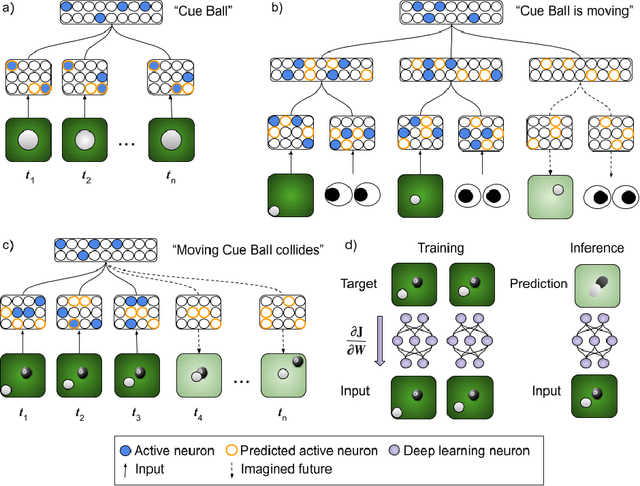
The field of machine learning has focused, primarily, on discretized sub-problems (i.e. vision, speech, natural language) of intelligence. While neuroscience tends to be observation heavy, providing few guiding theories. It is unlikely that artificial intelligence will emerge through only one of these disciplines. Instead, it is likely to be some amalgamation of their algorithmic and observational findings. As a result, there are a number of problems that should be addressed in order to select the beneficial aspects of both fields. In this article, we propose leading questions to guide the future of artificial intelligence research. There are clear computational principles on which the brain operates. The problem is finding these computational needles in a haystack of biological complexity. Biology has clear constraints but by not using it as a guide we are constraining ourselves.
Learning in the Machine: To Share or Not to Share?
Oct 04, 2019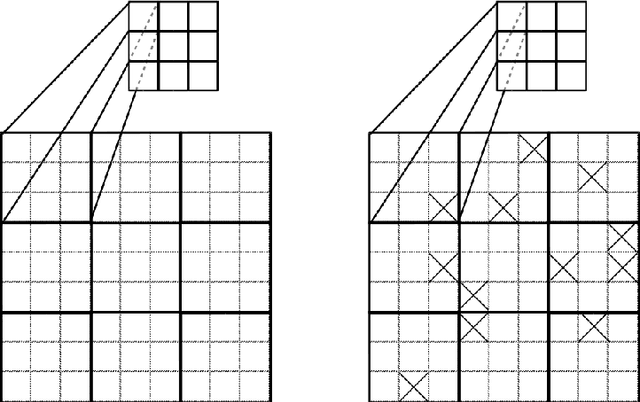
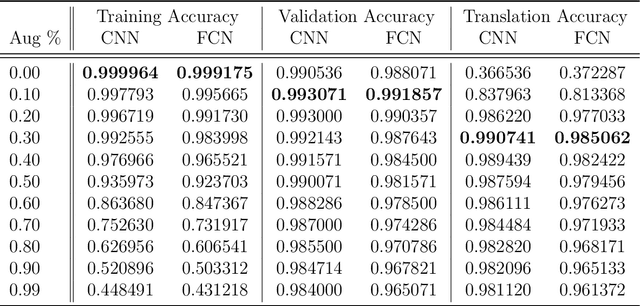
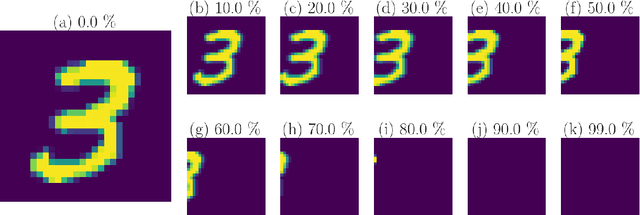
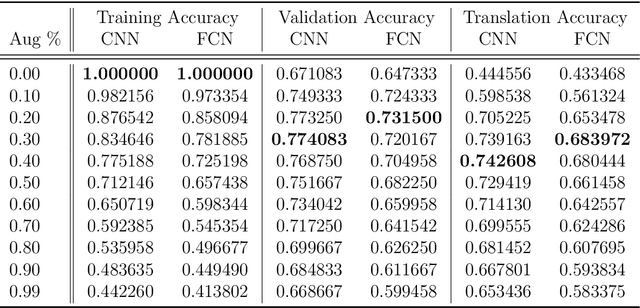
Weight-sharing is one of the pillars behind Convolutional Neural Networks and their successes. However, in physical neural systems such as the brain, weight-sharing is implausible. This discrepancy raises the fundamental question of whether weight-sharing is necessary. If so, to which degree of precision? If not, what are the alternatives? The goal of this study is to investigate these questions, primarily through simulations where the weight-sharing assumption is relaxed. Taking inspiration from neural circuitry, we explore the use of Free Convolutional Networks and neurons with variable connection patterns. Using Free Convolutional Networks, we show that while weight-sharing is a pragmatic optimization approach, it is not a necessity in computer vision applications. Furthermore, Free Convolutional Networks match the performance observed in standard architectures when trained using properly translated data (akin to video). Under the assumption of translationally augmented data, Free Convolutional Networks learn translationally invariant representations that yield an approximate form of weight sharing.