 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Vision-Language Models for Neutrino Event Classification in High-Energy Physics
Sep 11, 2025Recent advances in Large Language Models (LLMs) have demonstrated their remarkable capacity to process and reason over structured and unstructured data modalities beyond natural language. In this work, we explore the applications of Vision Language Models (VLMs), specifically a fine-tuned variant of LLaMa 3.2, to the task of identifying neutrino interactions in pixelated detector data from high-energy physics (HEP) experiments. We benchmark this model against a state-of-the-art convolutional neural network (CNN) architecture, similar to those used in the NOvA and DUNE experiments, which have achieved high efficiency and purity in classifying electron and muon neutrino events. Our evaluation considers both the classification performance and interpretability of the model predictions. We find that VLMs can outperform CNNs, while also providing greater flexibility in integrating auxiliary textual or semantic information and offering more interpretable, reasoning-based predictions. This work highlights the potential of VLMs as a general-purpose backbone for physics event classification, due to their high performance, interpretability, and generalizability, which opens new avenues for integrating multimodal reasoning in experimental neutrino physics.
Fine-Tuning Vision-Language Models for Neutrino Event Analysis in High-Energy Physics Experiments
Aug 26, 2025Recent progress in large language models (LLMs) has shown strong potential for multimodal reasoning beyond natural language. In this work, we explore the use of a fine-tuned Vision-Language Model (VLM), based on LLaMA 3.2, for classifying neutrino interactions from pixelated detector images in high-energy physics (HEP) experiments. We benchmark its performance against an established CNN baseline used in experiments like NOvA and DUNE, evaluating metrics such as classification accuracy, precision, recall, and AUC-ROC. Our results show that the VLM not only matches or exceeds CNN performance but also enables richer reasoning and better integration of auxiliary textual or semantic context. These findings suggest that VLMs offer a promising general-purpose backbone for event classification in HEP, paving the way for multimodal approaches in experimental neutrino physics.
Sparse Phased Array Optimization Using Deep Learning
Apr 23, 2025Antenna arrays are widely used in wireless communication, radar systems, radio astronomy, and military defense to enhance signal strength, directivity, and interference suppression. We introduce a deep learning-based optimization approach that enhances the design of sparse phased arrays by reducing grating lobes. This approach begins by generating sparse array configurations to address the non-convex challenges and extensive degrees of freedom inherent in array design. We use neural networks to approximate the non-convex cost function that estimates the energy ratio between the main and side lobes. This differentiable approximation facilitates cost function minimization through gradient descent, optimizing the antenna elements' coordinates and leading to an improved layout. Additionally, we incorporate a tailored penalty mechanism that includes various physical and design constraints into the optimization process, enhancing its robustness and practical applicability. We demonstrate the effectiveness of our method by applying it to the ten array configurations with the lowest initial costs, achieving further cost reductions ranging from 411% to 643%, with an impressive average improvement of 552%. By significantly reducing side lobe levels in antenna arrays, this breakthrough paves the way for ultra-precise beamforming, enhanced interference mitigation, and next-generation wireless and radar systems with unprecedented efficiency and clarity.
Antenna Near-Field Reconstruction from Far-Field Data Using Convolutional Neural Networks
Apr 23, 2025


Electromagnetic field reconstruction is crucial in many applications, including antenna diagnostics, electromagnetic interference analysis, and system modeling. This paper presents a deep learning-based approach for Far-Field to Near-Field (FF-NF) transformation using Convolutional Neural Networks (CNNs). The goal is to reconstruct near-field distributions from the far-field data of an antenna without relying on explicit analytical transformations. The CNNs are trained on paired far-field and near-field data and evaluated using mean squared error (MSE). The best model achieves a training error of 0.0199 and a test error of 0.3898. Moreover, visual comparisons between the predicted and true near-field distributions demonstrate the model's effectiveness in capturing complex electromagnetic field behavior, highlighting the potential of deep learning in electromagnetic field reconstruction.
Interpretable Deep Learning for Polar Mechanistic Reaction Prediction
Apr 22, 2025Accurately predicting chemical reactions is essential for driving innovation in synthetic chemistry, with broad applications in medicine, manufacturing, and agriculture. At the same time, reaction prediction is a complex problem which can be both time-consuming and resource-intensive for chemists to solve. Deep learning methods offer an appealing solution by enabling high-throughput reaction prediction. However, many existing models are trained on the US Patent Office dataset and treat reactions as overall transformations: mapping reactants directly to products with limited interpretability or mechanistic insight. To address this, we introduce PMechRP (Polar Mechanistic Reaction Predictor), a system that trains machine learning models on the PMechDB dataset, which represents reactions as polar elementary steps that capture electron flow and mechanistic detail. To further expand model coverage and improve generalization, we augment PMechDB with a diverse set of combinatorially generated reactions. We train and compare a range of machine learning models, including transformer-based, graph-based, and two-step siamese architectures. Our best-performing approach was a hybrid model, which combines a 5-ensemble of Chemformer models with a two-step Siamese framework to leverage the accuracy of transformer architectures, while filtering away "alchemical" products using the two-step network predictions. For evaluation, we use a test split of the PMechDB dataset and additionally curate a human benchmark dataset consisting of complete mechanistic pathways extracted from an organic chemistry textbook. Our hybrid model achieves a top-10 accuracy of 94.9% on the PMechDB test set and a target recovery rate of 84.9% on the pathway dataset.
Memorization: A Close Look at Books
Apr 17, 2025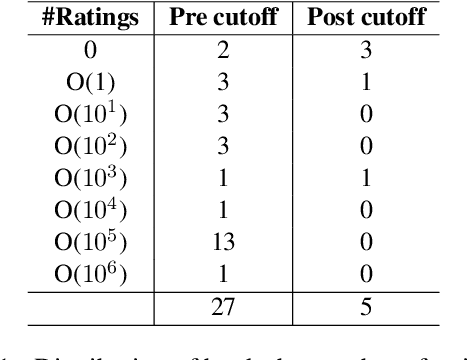
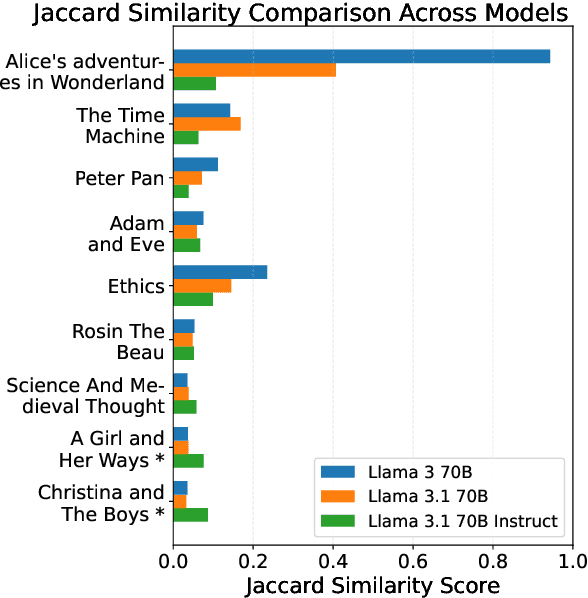
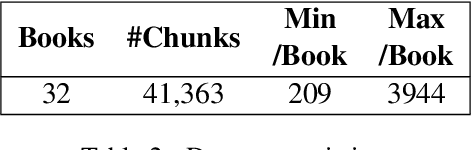
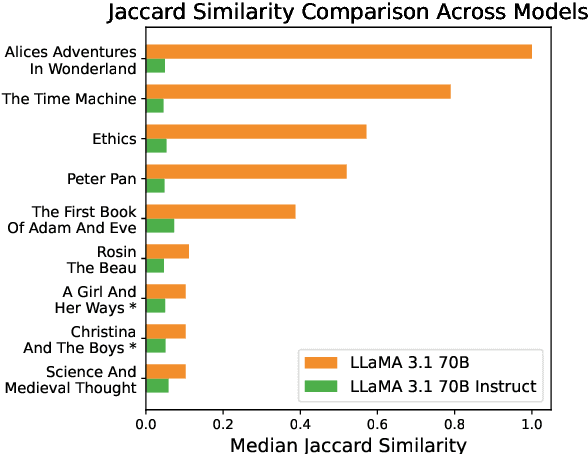
To what extent can entire books be extracted from LLMs? Using the Llama 3 70B family of models, and the "prefix-prompting" extraction technique, we were able to auto-regressively reconstruct, with a very high level of similarity, one entire book (Alice's Adventures in Wonderland) from just the first 500 tokens. We were also able to obtain high extraction rates on several other books, piece-wise. However, these successes do not extend uniformly to all books. We show that extraction rates of books correlate with book popularity and thus, likely duplication in the training data. We also confirm the undoing of mitigations in the instruction-tuned Llama 3.1, following recent work (Nasr et al., 2025). We further find that this undoing comes from changes to only a tiny fraction of weights concentrated primarily in the lower transformer blocks. Our results provide evidence of the limits of current regurgitation mitigation strategies and introduce a framework for studying how fine-tuning affects the retrieval of verbatim memorization in aligned LLMs.
Particle Hit Clustering and Identification Using Point Set Transformers in Liquid Argon Time Projection Chambers
Apr 11, 2025Liquid argon time projection chambers are often used in neutrino physics and dark-matter searches because of their high spatial resolution. The images generated by these detectors are extremely sparse, as the energy values detected by most of the detector are equal to 0, meaning that despite their high resolution, most of the detector is unused in a particular interaction. Instead of representing all of the empty detections, the interaction is usually stored as a sparse matrix, a list of detection locations paired with their energy values. Traditional machine learning methods that have been applied to particle reconstruction such as convolutional neural networks (CNNs), however, cannot operate over data stored in this way and therefore must have the matrix fully instantiated as a dense matrix. Operating on dense matrices requires a lot of memory and computation time, in contrast to directly operating on the sparse matrix. We propose a machine learning model using a point set neural network that operates over a sparse matrix, greatly improving both processing speed and accuracy over methods that instantiate the dense matrix, as well as over other methods that operate over sparse matrices. Compared to competing state-of-the-art methods, our method improves classification performance by 14%, segmentation performance by more than 22%, while taking 80% less time and using 66% less memory. Compared to state-of-the-art CNN methods, our method improves classification performance by more than 86%, segmentation performance by more than 71%, while reducing runtime by 91% and reducing memory usage by 61%.
Reconstruction of boosted and resolved multi-Higgs-boson events with symmetry-preserving attention networks
Dec 05, 2024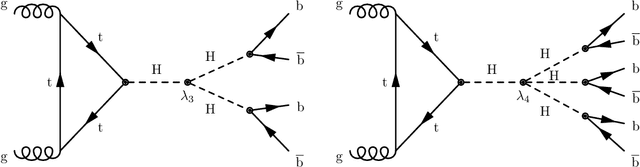



The production of multiple Higgs bosons at the CERN LHC provides a direct way to measure the trilinear and quartic Higgs self-interaction strengths as well as potential access to beyond the standard model effects that can enhance production at large transverse momentum $p_{\mathrm{T}}$. The largest event fraction arises from the fully hadronic final state in which every Higgs boson decays to a bottom quark-antiquark pair ($b\bar{b}$). This introduces a combinatorial challenge known as the \emph{jet assignment problem}: assigning jets to sets representing Higgs boson candidates. Symmetry-preserving attention networks (SPA-Nets) have been been developed to address this challenge. However, the complexity of jet assignment increases when simultaneously considering both $H\rightarrow b\bar{b}$ reconstruction possibilities, i.e., two "resolved" small-radius jets each containing a shower initiated by a $b$-quark or one "boosted" large-radius jet containing a merged shower initiated by a $b\bar{b}$ pair. The latter improves the reconstruction efficiency at high $p_{\mathrm{T}}$. In this work, we introduce a generalization to the SPA-Net approach to simultaneously consider both boosted and resolved reconstruction possibilities and unambiguously interpret an event as "fully resolved'', "fully boosted", or in between. We report the performance of baseline methods, the original SPA-Net approach, and our generalized version on nonresonant $HH$ and $HHH$ production at the LHC. Considering both boosted and resolved topologies, our SPA-Net approach increases the Higgs boson reconstruction purity by 57--62\% and the efficiency by 23--38\% compared to the baseline method depending on the final state.
Make the Pertinent Salient: Task-Relevant Reconstruction for Visual Control with Distractions
Oct 13, 2024

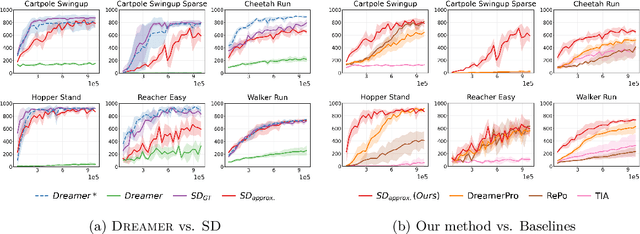
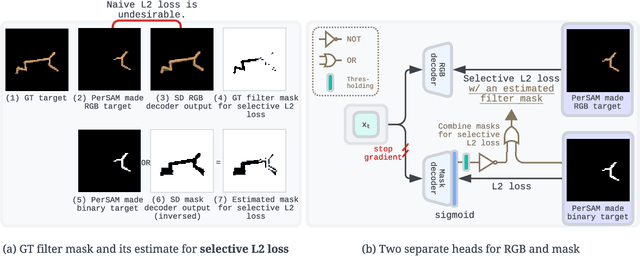
Recent advancements in Model-Based Reinforcement Learning (MBRL) have made it a powerful tool for visual control tasks. Despite improved data efficiency, it remains challenging to train MBRL agents with generalizable perception. Training in the presence of visual distractions is particularly difficult due to the high variation they introduce to representation learning. Building on DREAMER, a popular MBRL method, we propose a simple yet effective auxiliary task to facilitate representation learning in distracting environments. Under the assumption that task-relevant components of image observations are straightforward to identify with prior knowledge in a given task, we use a segmentation mask on image observations to only reconstruct task-relevant components. In doing so, we greatly reduce the complexity of representation learning by removing the need to encode task-irrelevant objects in the latent representation. Our method, Segmentation Dreamer (SD), can be used either with ground-truth masks easily accessible in simulation or by leveraging potentially imperfect segmentation foundation models. The latter is further improved by selectively applying the reconstruction loss to avoid providing misleading learning signals due to mask prediction errors. In modified DeepMind Control suite (DMC) and Meta-World tasks with added visual distractions, SD achieves significantly better sample efficiency and greater final performance than prior work. We find that SD is especially helpful in sparse reward tasks otherwise unsolvable by prior work, enabling the training of visually robust agents without the need for extensive reward engineering.
Realizable Continuous-Space Shields for Safe Reinforcement Learning
Oct 02, 2024



While Deep Reinforcement Learning (DRL) has achieved remarkable success across various domains, it remains vulnerable to occasional catastrophic failures without additional safeguards. One effective solution to prevent these failures is to use a shield that validates and adjusts the agent's actions to ensure compliance with a provided set of safety specifications. For real-life robot domains, it is desirable to be able to define such safety specifications over continuous state and action spaces to accurately account for system dynamics and calculate new safe actions that minimally alter the agent's output. In this paper, we propose the first shielding approach to automatically guarantee the realizability of safety requirements for continuous state and action spaces. Realizability is an essential property that confirms the shield will always be able to generate a safe action for any state in the environment. We formally prove that realizability can also be verified with a stateful shield, enabling the incorporation of non-Markovian safety requirements. Finally, we demonstrate the effectiveness of our approach in ensuring safety without compromising policy accuracy by applying it to a navigation problem and a multi-agent particle environment.