 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Augmented Game Starts for Accelerating Self-Play Exploration in Imperfect Information Games
May 14, 2026Finding approximate equilibria for large-scale imperfect-information competitive games such as StarCraft, Dota, and CounterStrike remains computationally infeasible due to sparse rewards and challenging exploration over long horizons. In this paper, we propose a multi-agent starting-state sampling strategy designed to substantially accelerate online exploration in regularized policy-gradient game methods for two-player zero-sum (2p0s) games. Motivated by an assumption that offline demonstrations from skilled humans can provide good coverage of high-level strategies relevant to equilibrium play, we propose the initialization of reinforcement learning data collection at intermediate states sampled from offline data to facilitate exploration of strategically relevant subgames. Referring to this method as Data-Augmented Game Starts (DAGS), we perform experiments using synthetic datasets and analytically tractable, long-horizon control variants of two-player Kuhn Poker, Goofspiel, and a counterexample game designed to penalize biased beliefs over hidden information. Under fixed computational budgets, DAGS enables regularized policy gradient methods to achieve lower exploitability in games with significantly more challenging exploration. We show that augmenting starting state distributions when solving imperfect information games can lead to biased equilibria, and we provide a straightforward mitigation to this in the form of multi-task observation flags. Finally, we release a new set of benchmark environments that drastically increase exploration challenges and state counts in existing OpenSpiel games while keeping exploitability measurements analytically tractable.
Adapting World Models with Latent-State Dynamics Residuals
Apr 03, 2025Simulation-to-reality reinforcement learning (RL) faces the critical challenge of reconciling discrepancies between simulated and real-world dynamics, which can severely degrade agent performance. A promising approach involves learning corrections to simulator forward dynamics represented as a residual error function, however this operation is impractical with high-dimensional states such as images. To overcome this, we propose ReDRAW, a latent-state autoregressive world model pretrained in simulation and calibrated to target environments through residual corrections of latent-state dynamics rather than of explicit observed states. Using this adapted world model, ReDRAW enables RL agents to be optimized with imagined rollouts under corrected dynamics and then deployed in the real world. In multiple vision-based MuJoCo domains and a physical robot visual lane-following task, ReDRAW effectively models changes to dynamics and avoids overfitting in low data regimes where traditional transfer methods fail.
Make the Pertinent Salient: Task-Relevant Reconstruction for Visual Control with Distractions
Oct 13, 2024

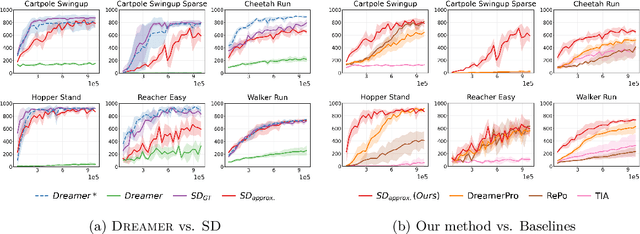
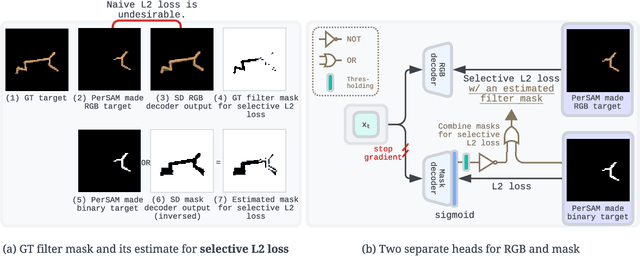
Recent advancements in Model-Based Reinforcement Learning (MBRL) have made it a powerful tool for visual control tasks. Despite improved data efficiency, it remains challenging to train MBRL agents with generalizable perception. Training in the presence of visual distractions is particularly difficult due to the high variation they introduce to representation learning. Building on DREAMER, a popular MBRL method, we propose a simple yet effective auxiliary task to facilitate representation learning in distracting environments. Under the assumption that task-relevant components of image observations are straightforward to identify with prior knowledge in a given task, we use a segmentation mask on image observations to only reconstruct task-relevant components. In doing so, we greatly reduce the complexity of representation learning by removing the need to encode task-irrelevant objects in the latent representation. Our method, Segmentation Dreamer (SD), can be used either with ground-truth masks easily accessible in simulation or by leveraging potentially imperfect segmentation foundation models. The latter is further improved by selectively applying the reconstruction loss to avoid providing misleading learning signals due to mask prediction errors. In modified DeepMind Control suite (DMC) and Meta-World tasks with added visual distractions, SD achieves significantly better sample efficiency and greater final performance than prior work. We find that SD is especially helpful in sparse reward tasks otherwise unsolvable by prior work, enabling the training of visually robust agents without the need for extensive reward engineering.
Realizable Continuous-Space Shields for Safe Reinforcement Learning
Oct 02, 2024



While Deep Reinforcement Learning (DRL) has achieved remarkable success across various domains, it remains vulnerable to occasional catastrophic failures without additional safeguards. One effective solution to prevent these failures is to use a shield that validates and adjusts the agent's actions to ensure compliance with a provided set of safety specifications. For real-life robot domains, it is desirable to be able to define such safety specifications over continuous state and action spaces to accurately account for system dynamics and calculate new safe actions that minimally alter the agent's output. In this paper, we propose the first shielding approach to automatically guarantee the realizability of safety requirements for continuous state and action spaces. Realizability is an essential property that confirms the shield will always be able to generate a safe action for any state in the environment. We formally prove that realizability can also be verified with a stateful shield, enabling the incorporation of non-Markovian safety requirements. Finally, we demonstrate the effectiveness of our approach in ensuring safety without compromising policy accuracy by applying it to a navigation problem and a multi-agent particle environment.
Verification-Guided Shielding for Deep Reinforcement Learning
Jun 10, 2024



In recent years, Deep Reinforcement Learning (DRL) has emerged as an effective approach to solving real-world tasks. However, despite their successes, DRL-based policies suffer from poor reliability, which limits their deployment in safety-critical domains. As a result, various methods have been put forth to address this issue by providing formal safety guarantees. Two main approaches include shielding and verification. While shielding ensures the safe behavior of the policy by employing an external online component (i.e., a ``shield'') that overruns potentially dangerous actions, this approach has a significant computational cost as the shield must be invoked at runtime to validate every decision. On the other hand, verification is an offline process that can identify policies that are unsafe, prior to their deployment, yet, without providing alternative actions when such a policy is deemed unsafe. In this work, we present verification-guided shielding -- a novel approach that bridges the DRL reliability gap by integrating these two methods. Our approach combines both formal and probabilistic verification tools to partition the input domain into safe and unsafe regions. In addition, we employ clustering and symbolic representation procedures that compress the unsafe regions into a compact representation. This, in turn, allows to temporarily activate the shield solely in (potentially) unsafe regions, in an efficient manner. Our novel approach allows to significantly reduce runtime overhead while still preserving formal safety guarantees. We extensively evaluate our approach on two benchmarks from the robotic navigation domain, as well as provide an in-depth analysis of its scalability and completeness.
Reinforcement Learning from Delayed Observations via World Models
Mar 18, 2024In standard Reinforcement Learning settings, agents typically assume immediate feedback about the effects of their actions after taking them. However, in practice, this assumption may not hold true due to physical constraints and can significantly impact the performance of RL algorithms. In this paper, we focus on addressing observation delays in partially observable environments. We propose leveraging world models, which have shown success in integrating past observations and learning dynamics, to handle observation delays. By reducing delayed POMDPs to delayed MDPs with world models, our methods can effectively handle partial observability, where existing approaches achieve sub-optimal performance or even degrade quickly as observability decreases. Experiments suggest that one of our methods can outperform a naive model-based approach by up to %30. Moreover, we evaluate our methods on visual input based delayed environment, for the first time showcasing delay-aware reinforcement learning on visual observations.
Moonwalk: Inverse-Forward Differentiation
Feb 22, 2024Backpropagation, while effective for gradient computation, falls short in addressing memory consumption, limiting scalability. This work explores forward-mode gradient computation as an alternative in invertible networks, showing its potential to reduce the memory footprint without substantial drawbacks. We introduce a novel technique based on a vector-inverse-Jacobian product that accelerates the computation of forward gradients while retaining the advantages of memory reduction and preserving the fidelity of true gradients. Our method, Moonwalk, has a time complexity linear in the depth of the network, unlike the quadratic time complexity of na\"ive forward, and empirically reduces computation time by several orders of magnitude without allocating more memory. We further accelerate Moonwalk by combining it with reverse-mode differentiation to achieve time complexity comparable with backpropagation while maintaining a much smaller memory footprint. Finally, we showcase the robustness of our method across several architecture choices. Moonwalk is the first forward-based method to compute true gradients in invertible networks in computation time comparable to backpropagation and using significantly less memory.
Skill Set Optimization: Reinforcing Language Model Behavior via Transferable Skills
Feb 05, 2024



Large language models (LLMs) have recently been used for sequential decision making in interactive environments. However, leveraging environment reward signals for continual LLM actor improvement is not straightforward. We propose Skill Set Optimization (SSO) for improving LLM actor performance through constructing and refining sets of transferable skills. SSO constructs skills by extracting common subtrajectories with high rewards and generating subgoals and instructions to represent each skill. These skills are provided to the LLM actor in-context to reinforce behaviors with high rewards. Then, SSO further refines the skill set by pruning skills that do not continue to result in high rewards. We evaluate our method in the classic videogame NetHack and the text environment ScienceWorld to demonstrate SSO's ability to optimize a set of skills and perform in-context policy improvement. SSO outperforms baselines by 40% in our custom NetHack task and outperforms the previous state-of-the-art in ScienceWorld by 35%.
Learning to Design Analog Circuits to Meet Threshold Specifications
Jul 25, 2023


Automated design of analog and radio-frequency circuits using supervised or reinforcement learning from simulation data has recently been studied as an alternative to manual expert design. It is straightforward for a design agent to learn an inverse function from desired performance metrics to circuit parameters. However, it is more common for a user to have threshold performance criteria rather than an exact target vector of feasible performance measures. In this work, we propose a method for generating from simulation data a dataset on which a system can be trained via supervised learning to design circuits to meet threshold specifications. We moreover perform the to-date most extensive evaluation of automated analog circuit design, including experimenting in a significantly more diverse set of circuits than in prior work, covering linear, nonlinear, and autonomous circuit configurations, and show that our method consistently reaches success rate better than 90% at 5% error margin, while also improving data efficiency by upward of an order of magnitude. A demo of this system is available at circuits.streamlit.app
Selective Perception: Optimizing State Descriptions with Reinforcement Learning for Language Model Actors
Jul 21, 2023


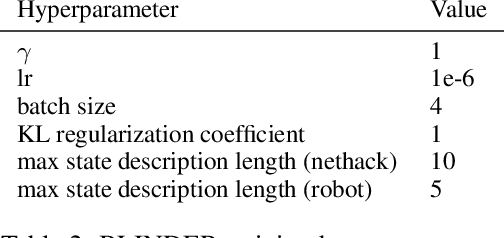
Large language models (LLMs) are being applied as actors for sequential decision making tasks in domains such as robotics and games, utilizing their general world knowledge and planning abilities. However, previous work does little to explore what environment state information is provided to LLM actors via language. Exhaustively describing high-dimensional states can impair performance and raise inference costs for LLM actors. Previous LLM actors avoid the issue by relying on hand-engineered, task-specific protocols to determine which features to communicate about a state and which to leave out. In this work, we propose Brief Language INputs for DEcision-making Responses (BLINDER), a method for automatically selecting concise state descriptions by learning a value function for task-conditioned state descriptions. We evaluate BLINDER on the challenging video game NetHack and a robotic manipulation task. Our method improves task success rate, reduces input size and compute costs, and generalizes between LLM actors.