 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting World Models with Latent-State Dynamics Residuals
Apr 03, 2025Simulation-to-reality reinforcement learning (RL) faces the critical challenge of reconciling discrepancies between simulated and real-world dynamics, which can severely degrade agent performance. A promising approach involves learning corrections to simulator forward dynamics represented as a residual error function, however this operation is impractical with high-dimensional states such as images. To overcome this, we propose ReDRAW, a latent-state autoregressive world model pretrained in simulation and calibrated to target environments through residual corrections of latent-state dynamics rather than of explicit observed states. Using this adapted world model, ReDRAW enables RL agents to be optimized with imagined rollouts under corrected dynamics and then deployed in the real world. In multiple vision-based MuJoCo domains and a physical robot visual lane-following task, ReDRAW effectively models changes to dynamics and avoids overfitting in low data regimes where traditional transfer methods fail.
Reinforcement Learning from Delayed Observations via World Models
Mar 18, 2024In standard Reinforcement Learning settings, agents typically assume immediate feedback about the effects of their actions after taking them. However, in practice, this assumption may not hold true due to physical constraints and can significantly impact the performance of RL algorithms. In this paper, we focus on addressing observation delays in partially observable environments. We propose leveraging world models, which have shown success in integrating past observations and learning dynamics, to handle observation delays. By reducing delayed POMDPs to delayed MDPs with world models, our methods can effectively handle partial observability, where existing approaches achieve sub-optimal performance or even degrade quickly as observability decreases. Experiments suggest that one of our methods can outperform a naive model-based approach by up to %30. Moreover, we evaluate our methods on visual input based delayed environment, for the first time showcasing delay-aware reinforcement learning on visual observations.
Moonwalk: Inverse-Forward Differentiation
Feb 22, 2024Backpropagation, while effective for gradient computation, falls short in addressing memory consumption, limiting scalability. This work explores forward-mode gradient computation as an alternative in invertible networks, showing its potential to reduce the memory footprint without substantial drawbacks. We introduce a novel technique based on a vector-inverse-Jacobian product that accelerates the computation of forward gradients while retaining the advantages of memory reduction and preserving the fidelity of true gradients. Our method, Moonwalk, has a time complexity linear in the depth of the network, unlike the quadratic time complexity of na\"ive forward, and empirically reduces computation time by several orders of magnitude without allocating more memory. We further accelerate Moonwalk by combining it with reverse-mode differentiation to achieve time complexity comparable with backpropagation while maintaining a much smaller memory footprint. Finally, we showcase the robustness of our method across several architecture choices. Moonwalk is the first forward-based method to compute true gradients in invertible networks in computation time comparable to backpropagation and using significantly less memory.
Matching DNN Compression and Cooperative Training with Resources and Data Availability
Dec 02, 2022To make machine learning (ML) sustainable and apt to run on the diverse devices where relevant data is, it is essential to compress ML models as needed, while still meeting the required learning quality and time performance. However, how much and when an ML model should be compressed, and {\em where} its training should be executed, are hard decisions to make, as they depend on the model itself, the resources of the available nodes, and the data such nodes own. Existing studies focus on each of those aspects individually, however, they do not account for how such decisions can be made jointly and adapted to one another. In this work, we model the network system focusing on the training of DNNs, formalize the above multi-dimensional problem, and, given its NP-hardness, formulate an approximate dynamic programming problem that we solve through the PACT algorithmic framework. Importantly, PACT leverages a time-expanded graph representing the learning process, and a data-driven and theoretical approach for the prediction of the loss evolution to be expected as a consequence of training decisions. We prove that PACT's solutions can get as close to the optimum as desired, at the cost of an increased time complexity, and that, in any case, such complexity is polynomial. Numerical results also show that, even under the most disadvantageous settings, PACT outperforms state-of-the-art alternatives and closely matches the optimal energy cost.
Regularizing Recurrent Neural Networks via Sequence Mixup
Nov 27, 2020

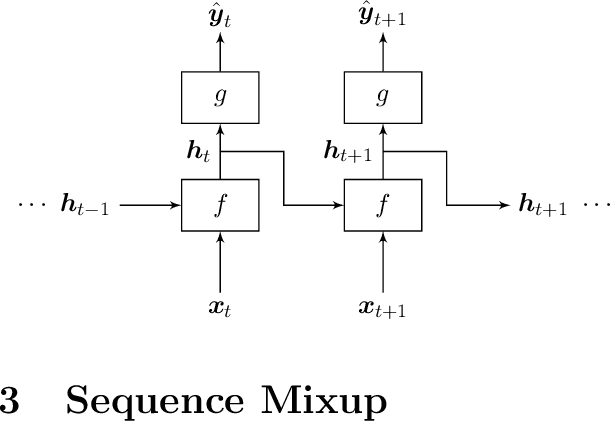

In this paper, we extend a class of celebrated regularization techniques originally proposed for feed-forward neural networks, namely Input Mixup (Zhang et al., 2017) and Manifold Mixup (Verma et al., 2018), to the realm of Recurrent Neural Networks (RNN). Our proposed methods are easy to implement and have a low computational complexity, while leverage the performance of simple neural architectures in a variety of tasks. We have validated our claims through several experiments on real-world datasets, and also provide an asymptotic theoretical analysis to further investigate the properties and potential impacts of our proposed techniques. Applying sequence mixup to BiLSTM-CRF model (Huang et al., 2015) to Named Entity Recognition task on CoNLL-2003 data (Sang and De Meulder, 2003) has improved the F-1 score on the test stage and reduced the loss, considerably.
Structure Learning of Sparse GGMs over Multiple Access Networks
Dec 26, 2018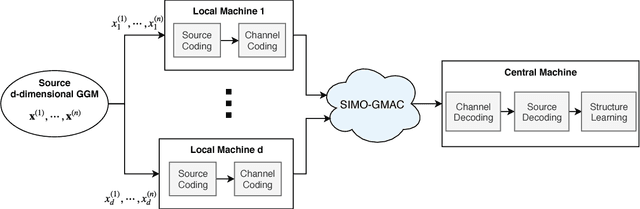
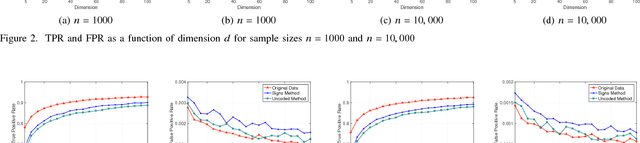

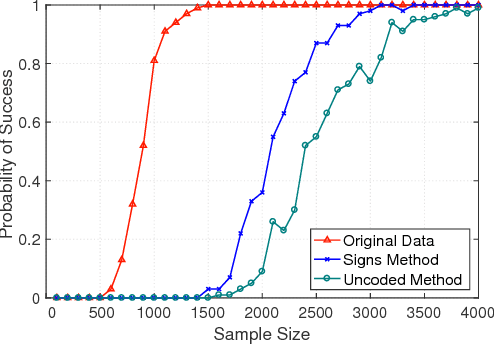
A central machine is interested in estimating the underlying structure of a sparse Gaussian Graphical Model (GGM) from datasets distributed across multiple local machines. The local machines can communicate with the central machine through a wireless multiple access channel. In this paper, we are interested in designing effective strategies where reliable learning is feasible under power and bandwidth limitations. Two approaches are proposed: Signs and Uncoded methods. In Signs method, the local machines quantize their data into binary vectors and an optimal channel coding scheme is used to reliably send the vectors to the central machine where the structure is learned from the received data. In Uncoded method, data symbols are scaled and transmitted through the channel. The central machine uses the received noisy symbols to recover the structure. Theoretical results show that both methods can recover the structure with high probability for large enough sample size. Experimental results indicate the superiority of Signs method over Uncoded method under several circumstances.