 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Efficient Sensor Fusion via System-Wide Dynamic Gated Neural Networks
Oct 22, 2024



Mobile systems will have to support multiple AI-based applications, each leveraging heterogeneous data sources through DNN architectures collaboratively executed within the network. To minimize the cost of the AI inference task subject to requirements on latency, quality, and - crucially - reliability of the inference process, it is vital to optimize (i) the set of sensors/data sources and (ii) the DNN architecture, (iii) the network nodes executing sections of the DNN, and (iv) the resources to use. To this end, we leverage dynamic gated neural networks with branches, and propose a novel algorithmic strategy called Quantile-constrained Inference (QIC), based upon quantile-Constrained policy optimization. QIC makes joint, high-quality, swift decisions on all the above aspects of the system, with the aim to minimize inference energy cost. We remark that this is the first contribution connecting gated dynamic DNNs with infrastructure-level decision making. We evaluate QIC using a dynamic gated DNN with stems and branches for optimal sensor fusion and inference, trained on the RADIATE dataset offering Radar, LiDAR, and Camera data, and real-world wireless measurements. Our results confirm that QIC matches the optimum and outperforms its alternatives by over 80%.
Combining Relevance and Magnitude for Resource-Aware DNN Pruning
May 21, 2024



Pruning neural networks, i.e., removing some of their parameters whilst retaining their accuracy, is one of the main ways to reduce the latency of a machine learning pipeline, especially in resource- and/or bandwidth-constrained scenarios. In this context, the pruning technique, i.e., how to choose the parameters to remove, is critical to the system performance. In this paper, we propose a novel pruning approach, called FlexRel and predicated upon combining training-time and inference-time information, namely, parameter magnitude and relevance, in order to improve the resulting accuracy whilst saving both computational resources and bandwidth. Our performance evaluation shows that FlexRel is able to achieve higher pruning factors, saving over 35% bandwidth for typical accuracy targets.
Resource-aware Deployment of Dynamic DNNs over Multi-tiered Interconnected Systems
Apr 11, 2024



The increasing pervasiveness of intelligent mobile applications requires to exploit the full range of resources offered by the mobile-edge-cloud network for the execution of inference tasks. However, due to the heterogeneity of such multi-tiered networks, it is essential to make the applications' demand amenable to the available resources while minimizing energy consumption. Modern dynamic deep neural networks (DNN) achieve this goal by designing multi-branched architectures where early exits enable sample-based adaptation of the model depth. In this paper, we tackle the problem of allocating sections of DNNs with early exits to the nodes of the mobile-edge-cloud system. By envisioning a 3-stage graph-modeling approach, we represent the possible options for splitting the DNN and deploying the DNN blocks on the multi-tiered network, embedding both the system constraints and the application requirements in a convenient and efficient way. Our framework -- named Feasible Inference Graph (FIN) -- can identify the solution that minimizes the overall inference energy consumption while enabling distributed inference over the multi-tiered network with the target quality and latency. Our results, obtained for DNNs with different levels of complexity, show that FIN matches the optimum and yields over 65% energy savings relative to a state-of-the-art technique for cost minimization.
Dependable Distributed Training of Compressed Machine Learning Models
Feb 22, 2024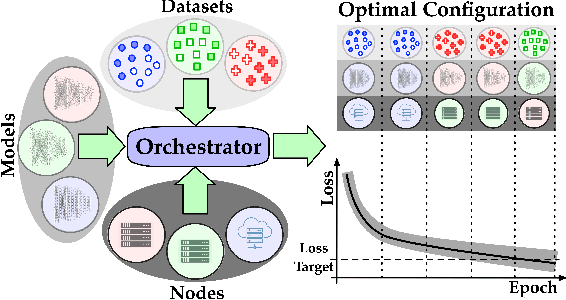
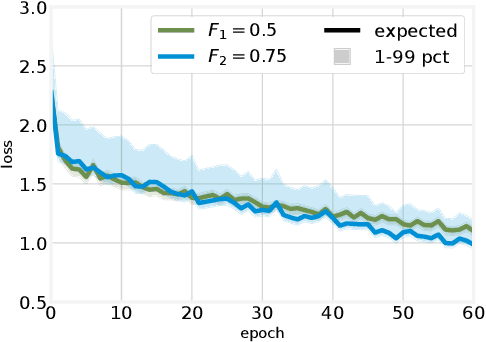
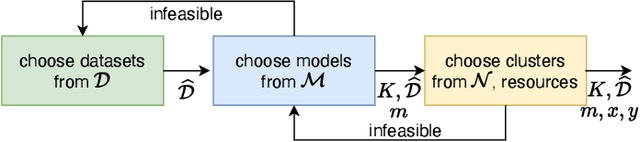
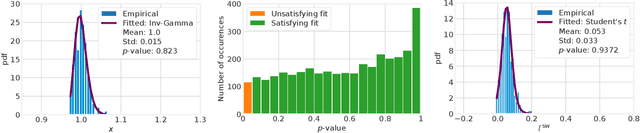
The existing work on the distributed training of machine learning (ML) models has consistently overlooked the distribution of the achieved learning quality, focusing instead on its average value. This leads to a poor dependability}of the resulting ML models, whose performance may be much worse than expected. We fill this gap by proposing DepL, a framework for dependable learning orchestration, able to make high-quality, efficient decisions on (i) the data to leverage for learning, (ii) the models to use and when to switch among them, and (iii) the clusters of nodes, and the resources thereof, to exploit. For concreteness, we consider as possible available models a full DNN and its compressed versions. Unlike previous studies, DepL guarantees that a target learning quality is reached with a target probability, while keeping the training cost at a minimum. We prove that DepL has constant competitive ratio and polynomial complexity, and show that it outperforms the state-of-the-art by over 27% and closely matches the optimum.
Unexpectedly Useful: Convergence Bounds And Real-World Distributed Learning
Dec 05, 2022



Convergence bounds are one of the main tools to obtain information on the performance of a distributed machine learning task, before running the task itself. In this work, we perform a set of experiments to assess to which extent, and in which way, such bounds can predict and improve the performance of real-world distributed (namely, federated) learning tasks. We find that, as can be expected given the way they are obtained, bounds are quite loose and their relative magnitude reflects the training rather than the testing loss. More unexpectedly, we find that some of the quantities appearing in the bounds turn out to be very useful to identify the clients that are most likely to contribute to the learning process, without requiring the disclosure of any information about the quality or size of their datasets. This suggests that further research is warranted on the ways -- often counter-intuitive -- in which convergence bounds can be exploited to improve the performance of real-world distributed learning tasks.
Matching DNN Compression and Cooperative Training with Resources and Data Availability
Dec 02, 2022To make machine learning (ML) sustainable and apt to run on the diverse devices where relevant data is, it is essential to compress ML models as needed, while still meeting the required learning quality and time performance. However, how much and when an ML model should be compressed, and {\em where} its training should be executed, are hard decisions to make, as they depend on the model itself, the resources of the available nodes, and the data such nodes own. Existing studies focus on each of those aspects individually, however, they do not account for how such decisions can be made jointly and adapted to one another. In this work, we model the network system focusing on the training of DNNs, formalize the above multi-dimensional problem, and, given its NP-hardness, formulate an approximate dynamic programming problem that we solve through the PACT algorithmic framework. Importantly, PACT leverages a time-expanded graph representing the learning process, and a data-driven and theoretical approach for the prediction of the loss evolution to be expected as a consequence of training decisions. We prove that PACT's solutions can get as close to the optimum as desired, at the cost of an increased time complexity, and that, in any case, such complexity is polynomial. Numerical results also show that, even under the most disadvantageous settings, PACT outperforms state-of-the-art alternatives and closely matches the optimal energy cost.
Choose, not Hoard: Information-to-Model Matching for Artificial Intelligence in O-RAN
Aug 01, 2022



Open Radio Access Network (O-RAN) is an emerging paradigm, whereby virtualized network infrastructure elements from different vendors communicate via open, standardized interfaces. A key element therein is the RAN Intelligent Controller (RIC), an Artificial Intelligence (AI)-based controller. Traditionally, all data available in the network has been used to train a single AI model to use at the RIC. In this paper we introduce, discuss, and evaluate the creation of multiple AI model instances at different RICs, leveraging information from some (or all) locations for their training. This brings about a flexible relationship between gNBs, the AI models used to control them, and the data such models are trained with. Experiments with real-world traces show how using multiple AI model instances that choose training data from specific locations improve the performance of traditional approaches.
Energy-efficient Training of Distributed DNNs in the Mobile-edge-cloud Continuum
Feb 23, 2022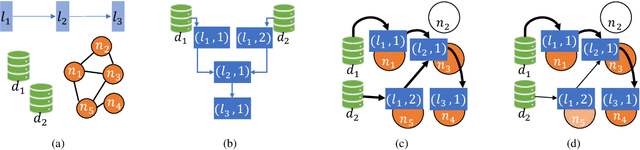
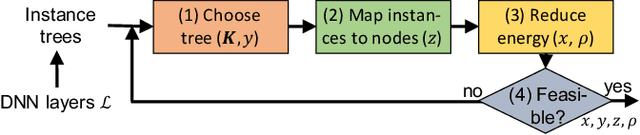
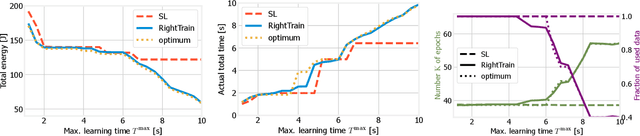
We address distributed machine learning in multi-tier (e.g., mobile-edge-cloud) networks where a heterogeneous set of nodes cooperate to perform a learning task. Due to the presence of multiple data sources and computation-capable nodes, a learning controller (e.g., located in the edge) has to make decisions about (i) which distributed ML model structure to select, (ii) which data should be used for the ML model training, and (iii) which resources should be allocated to it. Since these decisions deeply influence one another, they should be made jointly. In this paper, we envision a new approach to distributed learning in multi-tier networks, which aims at maximizing ML efficiency. To this end, we propose a solution concept, called RightTrain, that achieves energy-efficient ML model training, while fulfilling learning time and quality requirements. RightTrain makes high-quality decisions in polynomial time. Further, our performance evaluation shows that RightTrain closely matches the optimum and outperforms the state of the art by over 50%.
Flexible Parallel Learning in Edge Scenarios: Communication, Computational and Energy Cost
Jan 19, 2022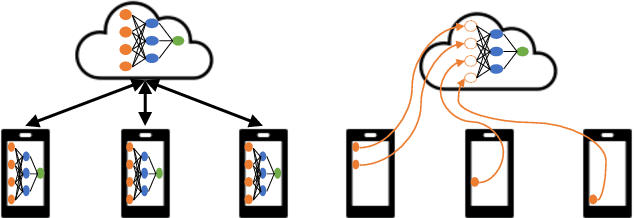
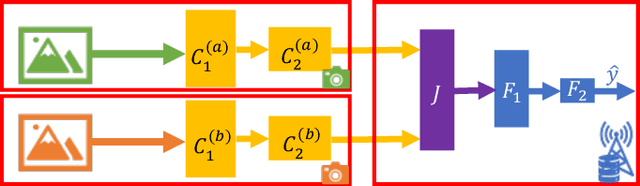
Traditionally, distributed machine learning takes the guise of (i) different nodes training the same model (as in federated learning), or (ii) one model being split among multiple nodes (as in distributed stochastic gradient descent). In this work, we highlight how fog- and IoT-based scenarios often require combining both approaches, and we present a framework for flexible parallel learning (FPL), achieving both data and model parallelism. Further, we investigate how different ways of distributing and parallelizing learning tasks across the participating nodes result in different computation, communication, and energy costs. Our experiments, carried out using state-of-the-art deep-network architectures and large-scale datasets, confirm that FPL allows for an excellent trade-off among computational (hence energy) cost, communication overhead, and learning performance.
Network Support for High-performance Distributed Machine Learning
Feb 05, 2021



The traditional approach to distributed machine learning is to adapt learning algorithms to the network, e.g., reducing updates to curb overhead. Networks based on intelligent edge, instead, make it possible to follow the opposite approach, i.e., to define the logical network topology em around the learning task to perform, so as to meet the desired learning performance. In this paper, we propose a system model that captures such aspects in the context of supervised machine learning, accounting for both learning nodes (that perform computations) and information nodes (that provide data). We then formulate the problem of selecting (i) which learning and information nodes should cooperate to complete the learning task, and (ii) the number of iterations to perform, in order to minimize the learning cost while meeting the target prediction error and execution time. After proving important properties of the above problem, we devise an algorithm, named DoubleClimb, that can find a 1+1/|I|-competitive solution (with I being the set of information nodes), with cubic worst-case complexity. Our performance evaluation, leveraging a real-world network topology and considering both classification and regression tasks, also shows that DoubleClimb closely matches the optimum, outperforming state-of-the-art alternatives.