 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Parallel Learning in Edge Scenarios: Communication, Computational and Energy Cost
Paper and Code
Jan 19, 2022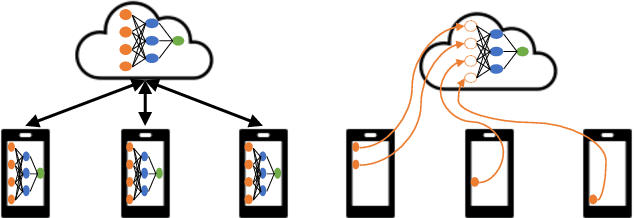
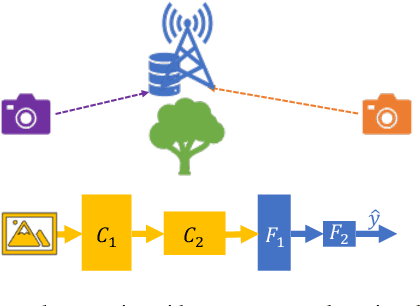
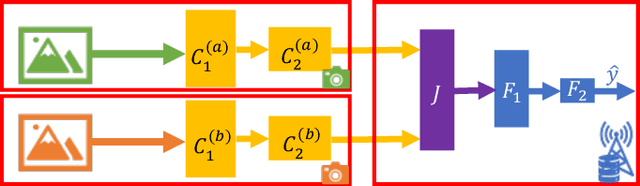
Traditionally, distributed machine learning takes the guise of (i) different nodes training the same model (as in federated learning), or (ii) one model being split among multiple nodes (as in distributed stochastic gradient descent). In this work, we highlight how fog- and IoT-based scenarios often require combining both approaches, and we present a framework for flexible parallel learning (FPL), achieving both data and model parallelism. Further, we investigate how different ways of distributing and parallelizing learning tasks across the participating nodes result in different computation, communication, and energy costs. Our experiments, carried out using state-of-the-art deep-network architectures and large-scale datasets, confirm that FPL allows for an excellent trade-off among computational (hence energy) cost, communication overhead, and learning performance.