 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDependable Distributed Training of Compressed Machine Learning Models
Paper and Code
Feb 22, 2024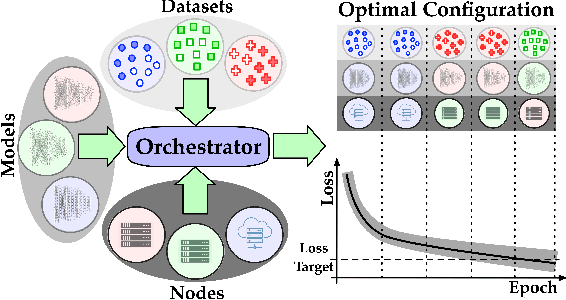
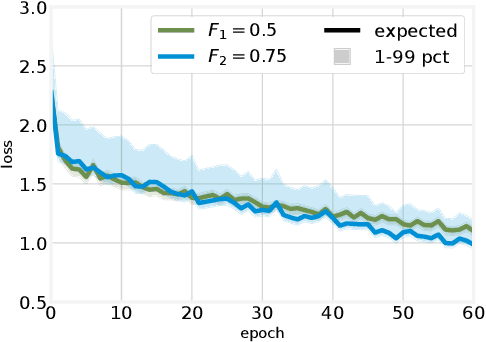
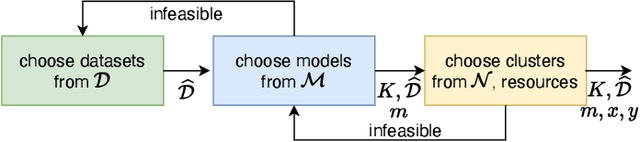
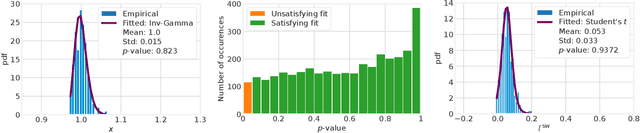
The existing work on the distributed training of machine learning (ML) models has consistently overlooked the distribution of the achieved learning quality, focusing instead on its average value. This leads to a poor dependability}of the resulting ML models, whose performance may be much worse than expected. We fill this gap by proposing DepL, a framework for dependable learning orchestration, able to make high-quality, efficient decisions on (i) the data to leverage for learning, (ii) the models to use and when to switch among them, and (iii) the clusters of nodes, and the resources thereof, to exploit. For concreteness, we consider as possible available models a full DNN and its compressed versions. Unlike previous studies, DepL guarantees that a target learning quality is reached with a target probability, while keeping the training cost at a minimum. We prove that DepL has constant competitive ratio and polynomial complexity, and show that it outperforms the state-of-the-art by over 27% and closely matches the optimum.