 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Augmented Game Starts for Accelerating Self-Play Exploration in Imperfect Information Games
May 14, 2026Finding approximate equilibria for large-scale imperfect-information competitive games such as StarCraft, Dota, and CounterStrike remains computationally infeasible due to sparse rewards and challenging exploration over long horizons. In this paper, we propose a multi-agent starting-state sampling strategy designed to substantially accelerate online exploration in regularized policy-gradient game methods for two-player zero-sum (2p0s) games. Motivated by an assumption that offline demonstrations from skilled humans can provide good coverage of high-level strategies relevant to equilibrium play, we propose the initialization of reinforcement learning data collection at intermediate states sampled from offline data to facilitate exploration of strategically relevant subgames. Referring to this method as Data-Augmented Game Starts (DAGS), we perform experiments using synthetic datasets and analytically tractable, long-horizon control variants of two-player Kuhn Poker, Goofspiel, and a counterexample game designed to penalize biased beliefs over hidden information. Under fixed computational budgets, DAGS enables regularized policy gradient methods to achieve lower exploitability in games with significantly more challenging exploration. We show that augmenting starting state distributions when solving imperfect information games can lead to biased equilibria, and we provide a straightforward mitigation to this in the form of multi-task observation flags. Finally, we release a new set of benchmark environments that drastically increase exploration challenges and state counts in existing OpenSpiel games while keeping exploitability measurements analytically tractable.
Adapting World Models with Latent-State Dynamics Residuals
Apr 03, 2025Simulation-to-reality reinforcement learning (RL) faces the critical challenge of reconciling discrepancies between simulated and real-world dynamics, which can severely degrade agent performance. A promising approach involves learning corrections to simulator forward dynamics represented as a residual error function, however this operation is impractical with high-dimensional states such as images. To overcome this, we propose ReDRAW, a latent-state autoregressive world model pretrained in simulation and calibrated to target environments through residual corrections of latent-state dynamics rather than of explicit observed states. Using this adapted world model, ReDRAW enables RL agents to be optimized with imagined rollouts under corrected dynamics and then deployed in the real world. In multiple vision-based MuJoCo domains and a physical robot visual lane-following task, ReDRAW effectively models changes to dynamics and avoids overfitting in low data regimes where traditional transfer methods fail.
Make the Pertinent Salient: Task-Relevant Reconstruction for Visual Control with Distractions
Oct 13, 2024

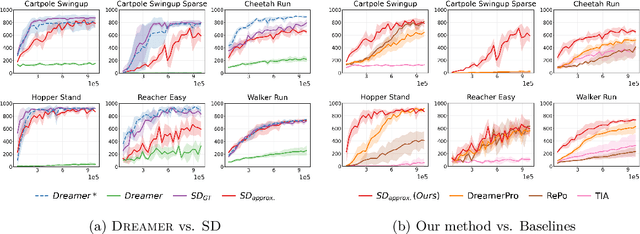
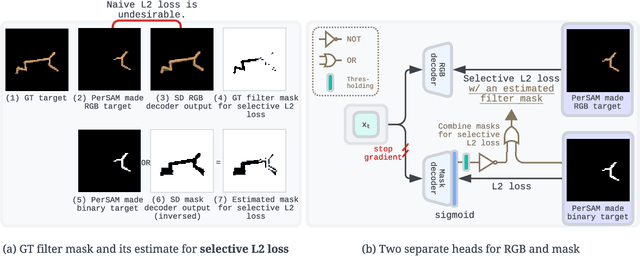
Recent advancements in Model-Based Reinforcement Learning (MBRL) have made it a powerful tool for visual control tasks. Despite improved data efficiency, it remains challenging to train MBRL agents with generalizable perception. Training in the presence of visual distractions is particularly difficult due to the high variation they introduce to representation learning. Building on DREAMER, a popular MBRL method, we propose a simple yet effective auxiliary task to facilitate representation learning in distracting environments. Under the assumption that task-relevant components of image observations are straightforward to identify with prior knowledge in a given task, we use a segmentation mask on image observations to only reconstruct task-relevant components. In doing so, we greatly reduce the complexity of representation learning by removing the need to encode task-irrelevant objects in the latent representation. Our method, Segmentation Dreamer (SD), can be used either with ground-truth masks easily accessible in simulation or by leveraging potentially imperfect segmentation foundation models. The latter is further improved by selectively applying the reconstruction loss to avoid providing misleading learning signals due to mask prediction errors. In modified DeepMind Control suite (DMC) and Meta-World tasks with added visual distractions, SD achieves significantly better sample efficiency and greater final performance than prior work. We find that SD is especially helpful in sparse reward tasks otherwise unsolvable by prior work, enabling the training of visually robust agents without the need for extensive reward engineering.
Realizable Continuous-Space Shields for Safe Reinforcement Learning
Oct 02, 2024



While Deep Reinforcement Learning (DRL) has achieved remarkable success across various domains, it remains vulnerable to occasional catastrophic failures without additional safeguards. One effective solution to prevent these failures is to use a shield that validates and adjusts the agent's actions to ensure compliance with a provided set of safety specifications. For real-life robot domains, it is desirable to be able to define such safety specifications over continuous state and action spaces to accurately account for system dynamics and calculate new safe actions that minimally alter the agent's output. In this paper, we propose the first shielding approach to automatically guarantee the realizability of safety requirements for continuous state and action spaces. Realizability is an essential property that confirms the shield will always be able to generate a safe action for any state in the environment. We formally prove that realizability can also be verified with a stateful shield, enabling the incorporation of non-Markovian safety requirements. Finally, we demonstrate the effectiveness of our approach in ensuring safety without compromising policy accuracy by applying it to a navigation problem and a multi-agent particle environment.
Selective Perception: Optimizing State Descriptions with Reinforcement Learning for Language Model Actors
Jul 21, 2023


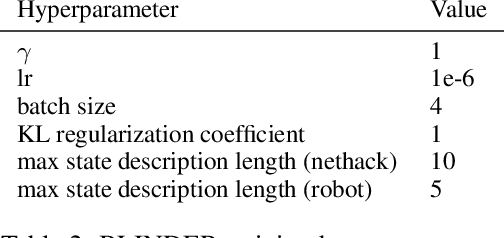
Large language models (LLMs) are being applied as actors for sequential decision making tasks in domains such as robotics and games, utilizing their general world knowledge and planning abilities. However, previous work does little to explore what environment state information is provided to LLM actors via language. Exhaustively describing high-dimensional states can impair performance and raise inference costs for LLM actors. Previous LLM actors avoid the issue by relying on hand-engineered, task-specific protocols to determine which features to communicate about a state and which to leave out. In this work, we propose Brief Language INputs for DEcision-making Responses (BLINDER), a method for automatically selecting concise state descriptions by learning a value function for task-conditioned state descriptions. We evaluate BLINDER on the challenging video game NetHack and a robotic manipulation task. Our method improves task success rate, reduces input size and compute costs, and generalizes between LLM actors.
Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments
Jul 19, 2022



Robust reinforcement learning (RL) considers the problem of learning policies that perform well in the worst case among a set of possible environment parameter values. In real-world environments, choosing the set of possible values for robust RL can be a difficult task. When that set is specified too narrowly, the agent will be left vulnerable to reasonable parameter values unaccounted for. When specified too broadly, the agent will be too cautious. In this paper, we propose Feasible Adversarial Robust RL (FARR), a method for automatically determining the set of environment parameter values over which to be robust. FARR implicitly defines the set of feasible parameter values as those on which an agent could achieve a benchmark reward given enough training resources. By formulating this problem as a two-player zero-sum game, FARR jointly learns an adversarial distribution over parameter values with feasible support and a policy robust over this feasible parameter set. Using the PSRO algorithm to find an approximate Nash equilibrium in this FARR game, we show that an agent trained with FARR is more robust to feasible adversarial parameter selection than with existing minimax, domain-randomization, and regret objectives in a parameterized gridworld and three MuJoCo control environments.
Self-Play PSRO: Toward Optimal Populations in Two-Player Zero-Sum Games
Jul 13, 2022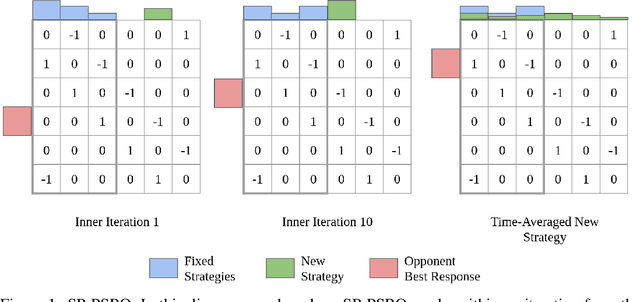


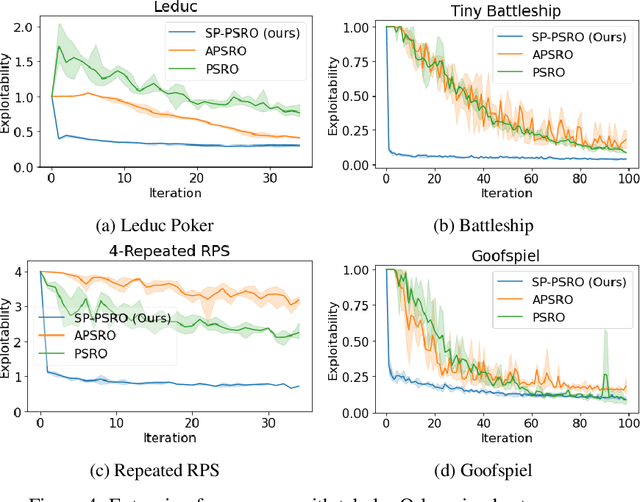
In competitive two-agent environments, deep reinforcement learning (RL) methods based on the \emph{Double Oracle (DO)} algorithm, such as \emph{Policy Space Response Oracles (PSRO)} and \emph{Anytime PSRO (APSRO)}, iteratively add RL best response policies to a population. Eventually, an optimal mixture of these population policies will approximate a Nash equilibrium. However, these methods might need to add all deterministic policies before converging. In this work, we introduce \emph{Self-Play PSRO (SP-PSRO)}, a method that adds an approximately optimal stochastic policy to the population in each iteration. Instead of adding only deterministic best responses to the opponent's least exploitable population mixture, SP-PSRO also learns an approximately optimal stochastic policy and adds it to the population as well. As a result, SP-PSRO empirically tends to converge much faster than APSRO and in many games converges in just a few iterations.