 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree Search for Language Model Agents
Jul 01, 2024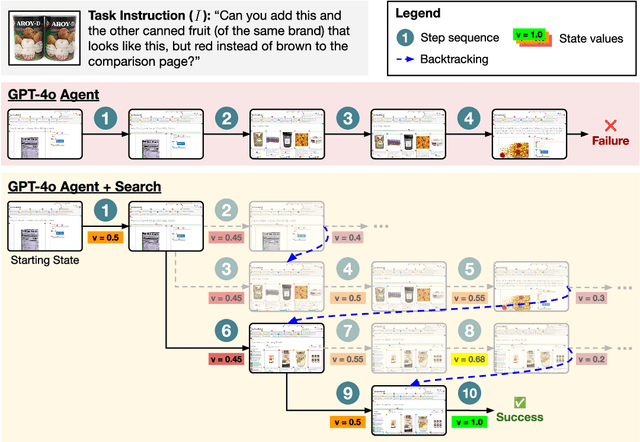


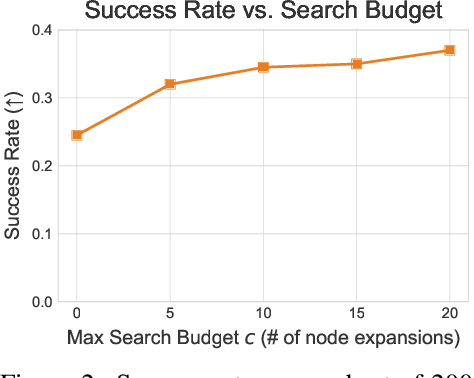
Autonomous agents powered by language models (LMs) have demonstrated promise in their ability to perform decision-making tasks such as web automation. However, a key limitation remains: LMs, primarily optimized for natural language understanding and generation, struggle with multi-step reasoning, planning, and using environmental feedback when attempting to solve realistic computer tasks. Towards addressing this, we propose an inference-time search algorithm for LM agents to explicitly perform exploration and multi-step planning in interactive web environments. Our approach is a form of best-first tree search that operates within the actual environment space, and is complementary with most existing state-of-the-art agents. It is the first tree search algorithm for LM agents that shows effectiveness on realistic web tasks. On the challenging VisualWebArena benchmark, applying our search algorithm on top of a GPT-4o agent yields a 39.7% relative increase in success rate compared to the same baseline without search, setting a state-of-the-art success rate of 26.4%. On WebArena, search also yields a 28.0% relative improvement over a baseline agent, setting a competitive success rate of 19.2%. Our experiments highlight the effectiveness of search for web agents, and we demonstrate that performance scales with increased test-time compute. We conduct a thorough analysis of our results to highlight improvements from search, limitations, and promising directions for future work. Our code and models are publicly released at https://jykoh.com/search-agents.
Grasper: A Generalist Pursuer for Pursuit-Evasion Problems
Apr 19, 2024


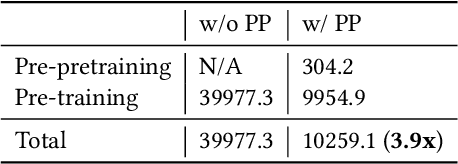
Pursuit-evasion games (PEGs) model interactions between a team of pursuers and an evader in graph-based environments such as urban street networks. Recent advancements have demonstrated the effectiveness of the pre-training and fine-tuning paradigm in PSRO to improve scalability in solving large-scale PEGs. However, these methods primarily focus on specific PEGs with fixed initial conditions that may vary substantially in real-world scenarios, which significantly hinders the applicability of the traditional methods. To address this issue, we introduce Grasper, a GeneRAlist purSuer for Pursuit-Evasion pRoblems, capable of efficiently generating pursuer policies tailored to specific PEGs. Our contributions are threefold: First, we present a novel architecture that offers high-quality solutions for diverse PEGs, comprising critical components such as (i) a graph neural network (GNN) to encode PEGs into hidden vectors, and (ii) a hypernetwork to generate pursuer policies based on these hidden vectors. As a second contribution, we develop an efficient three-stage training method involving (i) a pre-pretraining stage for learning robust PEG representations through self-supervised graph learning techniques like GraphMAE, (ii) a pre-training stage utilizing heuristic-guided multi-task pre-training (HMP) where heuristic-derived reference policies (e.g., through Dijkstra's algorithm) regularize pursuer policies, and (iii) a fine-tuning stage that employs PSRO to generate pursuer policies on designated PEGs. Finally, we perform extensive experiments on synthetic and real-world maps, showcasing Grasper's significant superiority over baselines in terms of solution quality and generalizability. We demonstrate that Grasper provides a versatile approach for solving pursuit-evasion problems across a broad range of scenarios, enabling practical deployment in real-world situations.
AgentKit: Flow Engineering with Graphs, not Coding
Apr 17, 2024



We propose an intuitive LLM prompting framework (AgentKit) for multifunctional agents. AgentKit offers a unified framework for explicitly constructing a complex "thought process" from simple natural language prompts. The basic building block in AgentKit is a node, containing a natural language prompt for a specific subtask. The user then puts together chains of nodes, like stacking LEGO pieces. The chains of nodes can be designed to explicitly enforce a naturally structured "thought process". For example, for the task of writing a paper, one may start with the thought process of 1) identify a core message, 2) identify prior research gaps, etc. The nodes in AgentKit can be designed and combined in different ways to implement multiple advanced capabilities including on-the-fly hierarchical planning, reflection, and learning from interactions. In addition, due to the modular nature and the intuitive design to simulate explicit human thought process, a basic agent could be implemented as simple as a list of prompts for the subtasks and therefore could be designed and tuned by someone without any programming experience. Quantitatively, we show that agents designed through AgentKit achieve SOTA performance on WebShop and Crafter. These advances underscore AgentKit's potential in making LLM agents effective and accessible for a wider range of applications. https://github.com/holmeswww/AgentKit
Policy Space Response Oracles: A Survey
Mar 04, 2024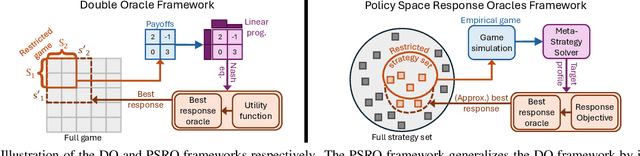

In game theory, a game refers to a model of interaction among rational decision-makers or players, making choices with the goal of achieving their individual objectives. Understanding their behavior in games is often referred to as game reasoning. This survey provides a comprehensive overview of a fast-developing game-reasoning framework for large games, known as Policy Space Response Oracles (PSRO). We first motivate PSRO, provide historical context, and position PSRO within game-reasoning approaches. We then focus on the strategy exploration issue for PSRO, the challenge of assembling an effective strategy portfolio for modeling the underlying game with minimum computational cost. We also survey current research directions for enhancing the efficiency of PSRO, and explore the applications of PSRO across various domains. We conclude by discussing open questions and future research.
Scalable Mechanism Design for Multi-Agent Path Finding
Jan 30, 2024



Multi-Agent Path Finding (MAPF) involves determining paths for multiple agents to travel simultaneously through a shared area toward particular goal locations. This problem is computationally complex, especially when dealing with large numbers of agents, as is common in realistic applications like autonomous vehicle coordination. Finding an optimal solution is often computationally infeasible, making the use of approximate algorithms essential. Adding to the complexity, agents might act in a self-interested and strategic way, possibly misrepresenting their goals to the MAPF algorithm if it benefits them. Although the field of mechanism design offers tools to align incentives, using these tools without careful consideration can fail when only having access to approximately optimal outcomes. Since approximations are crucial for scalable MAPF algorithms, this poses a significant challenge. In this work, we introduce the problem of scalable mechanism design for MAPF and propose three strategyproof mechanisms, two of which even use approximate MAPF algorithms. We test our mechanisms on realistic MAPF domains with problem sizes ranging from dozens to hundreds of agents. Our findings indicate that they improve welfare beyond a simple baseline.
AI Alignment: A Comprehensive Survey
Nov 01, 2023AI alignment aims to make AI systems behave in line with human intentions and values. As AI systems grow more capable, the potential large-scale risks associated with misaligned AI systems become salient. Hundreds of AI experts and public figures have expressed concerns about AI risks, arguing that "mitigating the risk of extinction from AI should be a global priority, alongside other societal-scale risks such as pandemics and nuclear war". To provide a comprehensive and up-to-date overview of the alignment field, in this survey paper, we delve into the core concepts, methodology, and practice of alignment. We identify the RICE principles as the key objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality. Guided by these four principles, we outline the landscape of current alignment research and decompose them into two key components: forward alignment and backward alignment. The former aims to make AI systems aligned via alignment training, while the latter aims to gain evidence about the systems' alignment and govern them appropriately to avoid exacerbating misalignment risks. Forward alignment and backward alignment form a recurrent process where the alignment of AI systems from the forward process is verified in the backward process, meanwhile providing updated objectives for forward alignment in the next round. On forward alignment, we discuss learning from feedback and learning under distribution shift. On backward alignment, we discuss assurance techniques and governance practices that apply to every stage of AI systems' lifecycle. We also release and continually update the website (www.alignmentsurvey.com) which features tutorials, collections of papers, blog posts, and other resources.
Llemma: An Open Language Model For Mathematics
Oct 16, 2023



We present Llemma, a large language model for mathematics. We continue pretraining Code Llama on the Proof-Pile-2, a mixture of scientific papers, web data containing mathematics, and mathematical code, yielding Llemma. On the MATH benchmark Llemma outperforms all known open base models, as well as the unreleased Minerva model suite on an equi-parameter basis. Moreover, Llemma is capable of tool use and formal theorem proving without any further finetuning. We openly release all artifacts, including 7 billion and 34 billion parameter models, the Proof-Pile-2, and code to replicate our experiments.
Confronting Reward Model Overoptimization with Constrained RLHF
Oct 10, 2023
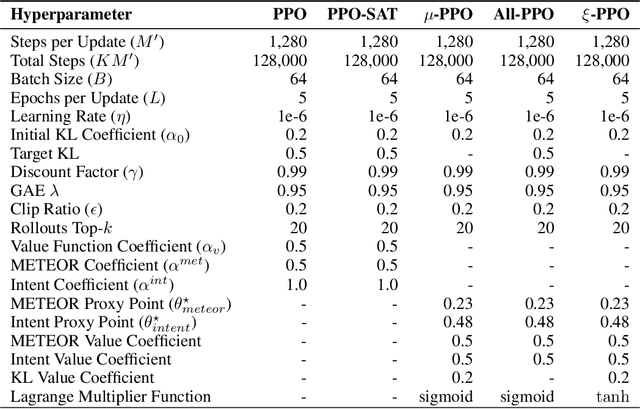


Large language models are typically aligned with human preferences by optimizing $\textit{reward models}$ (RMs) fitted to human feedback. However, human preferences are multi-faceted, and it is increasingly common to derive reward from a composition of simpler reward models which each capture a different aspect of language quality. This itself presents a challenge, as it is difficult to appropriately weight these component RMs when combining them. Compounding this difficulty, because any RM is only a proxy for human evaluation, this process is vulnerable to $\textit{overoptimization}$, wherein past a certain point, accumulating higher reward is associated with worse human ratings. In this paper, we perform, to our knowledge, the first study on overoptimization in composite RMs, showing that correlation between component RMs has a significant effect on the locations of these points. We then introduce an approach to solve this issue using constrained reinforcement learning as a means of preventing the agent from exceeding each RM's threshold of usefulness. Our method addresses the problem of weighting component RMs by learning dynamic weights, naturally expressed by Lagrange multipliers. As a result, each RM stays within the range at which it is an effective proxy, improving evaluation performance. Finally, we introduce an adaptive method using gradient-free optimization to identify and optimize towards these points during a single run.
Game-Theoretic Robust Reinforcement Learning Handles Temporally-Coupled Perturbations
Jul 22, 2023



Robust reinforcement learning (RL) seeks to train policies that can perform well under environment perturbations or adversarial attacks. Existing approaches typically assume that the space of possible perturbations remains the same across timesteps. However, in many settings, the space of possible perturbations at a given timestep depends on past perturbations. We formally introduce temporally-coupled perturbations, presenting a novel challenge for existing robust RL methods. To tackle this challenge, we propose GRAD, a novel game-theoretic approach that treats the temporally-coupled robust RL problem as a partially-observable two-player zero-sum game. By finding an approximate equilibrium in this game, GRAD ensures the agent's robustness against temporally-coupled perturbations. Empirical experiments on a variety of continuous control tasks demonstrate that our proposed approach exhibits significant robustness advantages compared to baselines against both standard and temporally-coupled attacks, in both state and action spaces.
Policy Space Diversity for Non-Transitive Games
Jun 29, 2023



Policy-Space Response Oracles (PSRO) is an influential algorithm framework for approximating a Nash Equilibrium (NE) in multi-agent non-transitive games. Many previous studies have been trying to promote policy diversity in PSRO. A major weakness in existing diversity metrics is that a more diverse (according to their diversity metrics) population does not necessarily mean (as we proved in the paper) a better approximation to a NE. To alleviate this problem, we propose a new diversity metric, the improvement of which guarantees a better approximation to a NE. Meanwhile, we develop a practical and well-justified method to optimize our diversity metric using only state-action samples. By incorporating our diversity regularization into the best response solving in PSRO, we obtain a new PSRO variant, Policy Space Diversity PSRO (PSD-PSRO). We present the convergence property of PSD-PSRO. Empirically, extensive experiments on various games demonstrate that PSD-PSRO is more effective in producing significantly less exploitable policies than state-of-the-art PSRO variants.