 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Natural Language to Extensive-Form Game Representations
Jan 31, 2025

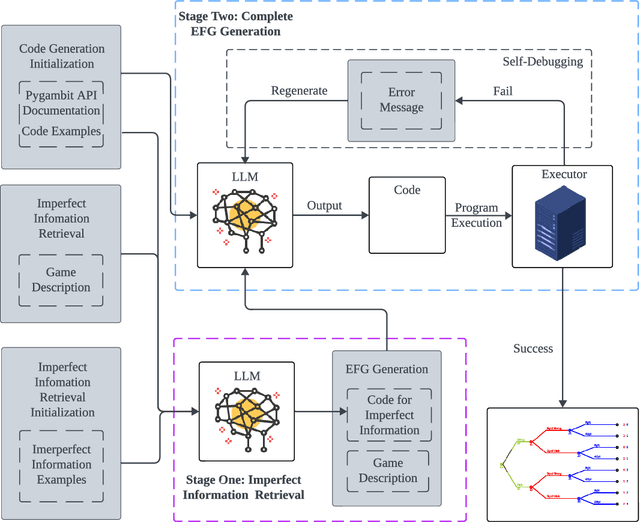
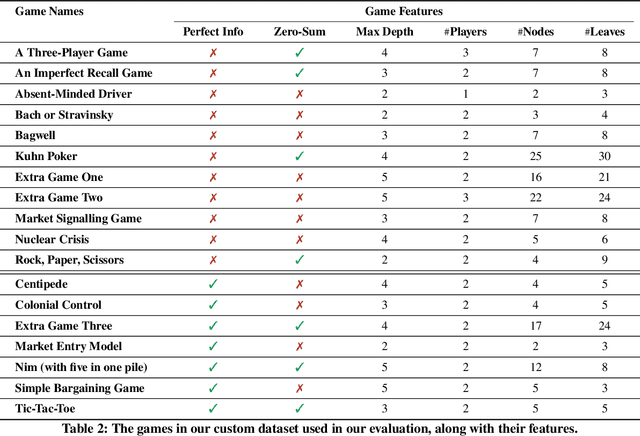
We introduce a framework for translating game descriptions in natural language into extensive-form representations in game theory, leveraging Large Language Models (LLMs) and in-context learning. Given the varying levels of strategic complexity in games, such as perfect versus imperfect information, directly applying in-context learning would be insufficient. To address this, we introduce a two-stage framework with specialized modules to enhance in-context learning, enabling it to divide and conquer the problem effectively. In the first stage, we tackle the challenge of imperfect information by developing a module that identifies information sets along and the corresponding partial tree structure. With this information, the second stage leverages in-context learning alongside a self-debugging module to produce a complete extensive-form game tree represented using pygambit, the Python API of a recognized game-theoretic analysis tool called Gambit. Using this python representation enables the automation of tasks such as computing Nash equilibria directly from natural language descriptions. We evaluate the performance of the full framework, as well as its individual components, using various LLMs on games with different levels of strategic complexity. Our experimental results show that the framework significantly outperforms baseline models in generating accurate extensive-form games, with each module playing a critical role in its success.
Policy Space Response Oracles: A Survey
Mar 04, 2024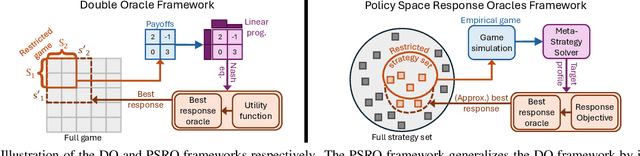

In game theory, a game refers to a model of interaction among rational decision-makers or players, making choices with the goal of achieving their individual objectives. Understanding their behavior in games is often referred to as game reasoning. This survey provides a comprehensive overview of a fast-developing game-reasoning framework for large games, known as Policy Space Response Oracles (PSRO). We first motivate PSRO, provide historical context, and position PSRO within game-reasoning approaches. We then focus on the strategy exploration issue for PSRO, the challenge of assembling an effective strategy portfolio for modeling the underlying game with minimum computational cost. We also survey current research directions for enhancing the efficiency of PSRO, and explore the applications of PSRO across various domains. We conclude by discussing open questions and future research.