 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMI-IRL: Contrastive Multi-Intention Inverse Reinforcement Learning
Feb 07, 2026Inverse Reinforcement Learning (IRL) seeks to infer reward functions from expert demonstrations. When demonstrations originate from multiple experts with different intentions, the problem is known as Multi-Intention IRL (MI-IRL). Recent deep generative MI-IRL approaches couple behavior clustering and reward learning, but typically require prior knowledge of the number of true behavioral modes $K^*$. This reliance on expert knowledge limits their adaptability to new behaviors, and only enables analysis related to the learned rewards, and not across the behavior modes used to train them. We propose Contrastive Multi-Intention IRL (CoMI-IRL), a transformer-based unsupervised framework that decouples behavior representation and clustering from downstream reward learning. Our experiments show that CoMI-IRL outperforms existing approaches without a priori knowledge of $K^*$ or labels, while allowing for visual interpretation of behavior relationships and adaptation to unseen behavior without full retraining.
Sample-Efficient Policy Space Response Oracles with Joint Experience Best Response
Feb 06, 2026Multi-agent reinforcement learning (MARL) offers a scalable alternative to exact game-theoretic analysis but suffers from non-stationarity and the need to maintain diverse populations of strategies that capture non-transitive interactions. Policy Space Response Oracles (PSRO) address these issues by iteratively expanding a restricted game with approximate best responses (BRs), yet per-agent BR training makes it prohibitively expensive in many-agent or simulator-expensive settings. We introduce Joint Experience Best Response (JBR), a drop-in modification to PSRO that collects trajectories once under the current meta-strategy profile and reuses this joint dataset to compute BRs for all agents simultaneously. This amortizes environment interaction and improves the sample efficiency of best-response computation. Because JBR converts BR computation into an offline RL problem, we propose three remedies for distribution-shift bias: (i) Conservative JBR with safe policy improvement, (ii) Exploration-Augmented JBR that perturbs data collection and admits theoretical guarantees, and (iii) Hybrid BR that interleaves JBR with periodic independent BR updates. Across benchmark multi-agent environments, Exploration-Augmented JBR achieves the best accuracy-efficiency trade-off, while Hybrid BR attains near-PSRO performance at a fraction of the sample cost. Overall, JBR makes PSRO substantially more practical for large-scale strategic learning while preserving equilibrium robustness.
Learning to Focus: Prioritizing Informative Histories with Structured Attention Mechanisms in Partially Observable Reinforcement Learning
Nov 10, 2025Transformers have shown strong ability to model long-term dependencies and are increasingly adopted as world models in model-based reinforcement learning (RL) under partial observability. However, unlike natural language corpora, RL trajectories are sparse and reward-driven, making standard self-attention inefficient because it distributes weight uniformly across all past tokens rather than emphasizing the few transitions critical for control. To address this, we introduce structured inductive priors into the self-attention mechanism of the dynamics head: (i) per-head memory-length priors that constrain attention to task-specific windows, and (ii) distributional priors that learn smooth Gaussian weightings over past state-action pairs. We integrate these mechanisms into UniZero, a model-based RL agent with a Transformer-based world model that supports planning under partial observability. Experiments on the Atari 100k benchmark show that most efficiency gains arise from the Gaussian prior, which smoothly allocates attention to informative transitions, while memory-length priors often truncate useful signals with overly restrictive cut-offs. In particular, Gaussian Attention achieves a 77% relative improvement in mean human-normalized scores over UniZero. These findings suggest that in partially observable RL domains with non-stationary temporal dependencies, discrete memory windows are difficult to learn reliably, whereas smooth distributional priors flexibly adapt across horizons and yield more robust data efficiency. Overall, our results demonstrate that encoding structured temporal priors directly into self-attention improves the prioritization of informative histories for dynamics modeling under partial observability.
Exploring Equity of Climate Policies using Multi-Agent Multi-Objective Reinforcement Learning
May 02, 2025Addressing climate change requires coordinated policy efforts of nations worldwide. These efforts are informed by scientific reports, which rely in part on Integrated Assessment Models (IAMs), prominent tools used to assess the economic impacts of climate policies. However, traditional IAMs optimize policies based on a single objective, limiting their ability to capture the trade-offs among economic growth, temperature goals, and climate justice. As a result, policy recommendations have been criticized for perpetuating inequalities, fueling disagreements during policy negotiations. We introduce Justice, the first framework integrating IAM with Multi-Objective Multi-Agent Reinforcement Learning (MOMARL). By incorporating multiple objectives, Justice generates policy recommendations that shed light on equity while balancing climate and economic goals. Further, using multiple agents can provide a realistic representation of the interactions among the diverse policy actors. We identify equitable Pareto-optimal policies using our framework, which facilitates deliberative decision-making by presenting policymakers with the inherent trade-offs in climate and economic policy.
Timing the Match: A Deep Reinforcement Learning Approach for Ride-Hailing and Ride-Pooling Services
Mar 17, 2025Efficient timing in ride-matching is crucial for improving the performance of ride-hailing and ride-pooling services, as it determines the number of drivers and passengers considered in each matching process. Traditional batched matching methods often use fixed time intervals to accumulate ride requests before assigning matches. While this approach increases the number of available drivers and passengers for matching, it fails to adapt to real-time supply-demand fluctuations, often leading to longer passenger wait times and driver idle periods. To address this limitation, we propose an adaptive ride-matching strategy using deep reinforcement learning (RL) to dynamically determine when to perform matches based on real-time system conditions. Unlike fixed-interval approaches, our method continuously evaluates system states and executes matching at moments that minimize total passenger wait time. Additionally, we incorporate a potential-based reward shaping (PBRS) mechanism to mitigate sparse rewards, accelerating RL training and improving decision quality. Extensive empirical evaluations using a realistic simulator trained on real-world data demonstrate that our approach outperforms fixed-interval matching strategies, significantly reducing passenger waiting times and detour delays, thereby enhancing the overall efficiency of ride-hailing and ride-pooling systems.
SHARPIE: A Modular Framework for Reinforcement Learning and Human-AI Interaction Experiments
Jan 31, 2025


Reinforcement learning (RL) offers a general approach for modeling and training AI agents, including human-AI interaction scenarios. In this paper, we propose SHARPIE (Shared Human-AI Reinforcement Learning Platform for Interactive Experiments) to address the need for a generic framework to support experiments with RL agents and humans. Its modular design consists of a versatile wrapper for RL environments and algorithm libraries, a participant-facing web interface, logging utilities, deployment on popular cloud and participant recruitment platforms. It empowers researchers to study a wide variety of research questions related to the interaction between humans and RL agents, including those related to interactive reward specification and learning, learning from human feedback, action delegation, preference elicitation, user-modeling, and human-AI teaming. The platform is based on a generic interface for human-RL interactions that aims to standardize the field of study on RL in human contexts.
SimuDICE: Offline Policy Optimization Through World Model Updates and DICE Estimation
Dec 09, 2024In offline reinforcement learning, deriving an effective policy from a pre-collected set of experiences is challenging due to the distribution mismatch between the target policy and the behavioral policy used to collect the data, as well as the limited sample size. Model-based reinforcement learning improves sample efficiency by generating simulated experiences using a learned dynamic model of the environment. However, these synthetic experiences often suffer from the same distribution mismatch. To address these challenges, we introduce SimuDICE, a framework that iteratively refines the initial policy derived from offline data using synthetically generated experiences from the world model. SimuDICE enhances the quality of these simulated experiences by adjusting the sampling probabilities of state-action pairs based on stationary DIstribution Correction Estimation (DICE) and the estimated confidence in the model's predictions. This approach guides policy improvement by balancing experiences similar to those frequently encountered with ones that have a distribution mismatch. Our experiments show that SimuDICE achieves performance comparable to existing algorithms while requiring fewer pre-collected experiences and planning steps, and it remains robust across varying data collection policies.
Navigating Trade-offs: Policy Summarization for Multi-Objective Reinforcement Learning
Nov 07, 2024Multi-objective reinforcement learning (MORL) is used to solve problems involving multiple objectives. An MORL agent must make decisions based on the diverse signals provided by distinct reward functions. Training an MORL agent yields a set of solutions (policies), each presenting distinct trade-offs among the objectives (expected returns). MORL enhances explainability by enabling fine-grained comparisons of policies in the solution set based on their trade-offs as opposed to having a single policy. However, the solution set is typically large and multi-dimensional, where each policy (e.g., a neural network) is represented by its objective values. We propose an approach for clustering the solution set generated by MORL. By considering both policy behavior and objective values, our clustering method can reveal the relationship between policy behaviors and regions in the objective space. This approach can enable decision makers (DMs) to identify overarching trends and insights in the solution set rather than examining each policy individually. We tested our method in four multi-objective environments and found it outperformed traditional k-medoids clustering. Additionally, we include a case study that demonstrates its real-world application.
Communicating with Speakers and Listeners of Different Pragmatic Levels
Oct 08, 2024



This paper explores the impact of variable pragmatic competence on communicative success through simulating language learning and conversing between speakers and listeners with different levels of reasoning abilities. Through studying this interaction, we hypothesize that matching levels of reasoning between communication partners would create a more beneficial environment for communicative success and language learning. Our research findings indicate that learning from more explicit, literal language is advantageous, irrespective of the learner's level of pragmatic competence. Furthermore, we find that integrating pragmatic reasoning during language learning, not just during evaluation, significantly enhances overall communication performance. This paper provides key insights into the importance of aligning reasoning levels and incorporating pragmatic reasoning in optimizing communicative interactions.
Online Planning in POMDPs with State-Requests
Jul 26, 2024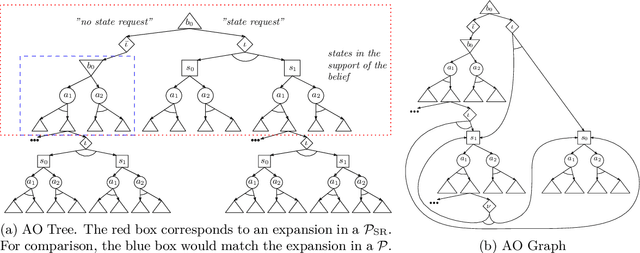
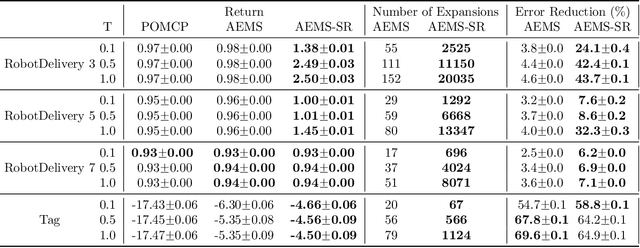
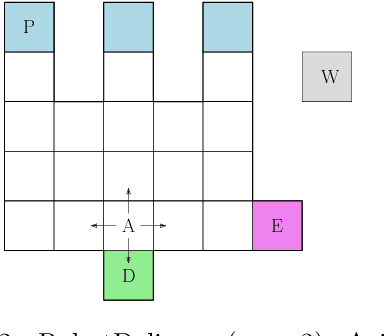
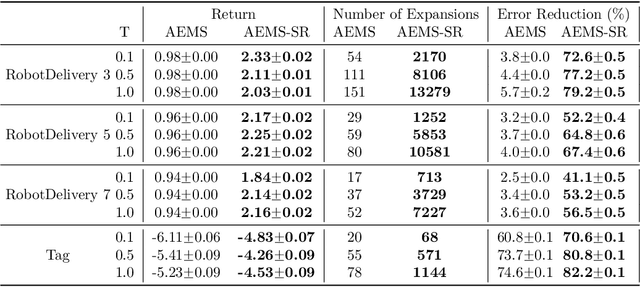
In key real-world problems, full state information is sometimes available but only at a high cost, like activating precise yet energy-intensive sensors or consulting humans, thereby compelling the agent to operate under partial observability. For this scenario, we propose AEMS-SR (Anytime Error Minimization Search with State Requests), a principled online planning algorithm tailored for POMDPs with state requests. By representing the search space as a graph instead of a tree, AEMS-SR avoids the exponential growth of the search space originating from state requests. Theoretical analysis demonstrates AEMS-SR's $\varepsilon$-optimality, ensuring solution quality, while empirical evaluations illustrate its effectiveness compared with AEMS and POMCP, two SOTA online planning algorithms. AEMS-SR enables efficient planning in domains characterized by partial observability and costly state requests offering practical benefits across various applications.