 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAX: Fast and Flexible Neural Click Models in JAX
Nov 05, 2025CLAX is a JAX-based library that implements classic click models using modern gradient-based optimization. While neural click models have emerged over the past decade, complex click models based on probabilistic graphical models (PGMs) have not systematically adopted gradient-based optimization, preventing practitioners from leveraging modern deep learning frameworks while preserving the interpretability of classic models. CLAX addresses this gap by replacing EM-based optimization with direct gradient-based optimization in a numerically stable manner. The framework's modular design enables the integration of any component, from embeddings and deep networks to custom modules, into classic click models for end-to-end optimization. We demonstrate CLAX's efficiency by running experiments on the full Baidu-ULTR dataset comprising over a billion user sessions in $\approx$ 2 hours on a single GPU, orders of magnitude faster than traditional EM approaches. CLAX implements ten classic click models, serving both industry practitioners seeking to understand user behavior and improve ranking performance at scale and researchers developing new click models. CLAX is available at: https://github.com/philipphager/clax
Unidentified and Confounded? Understanding Two-Tower Models for Unbiased Learning to Rank (Extended Abstract)
Aug 29, 2025Additive two-tower models are popular learning-to-rank methods for handling biased user feedback in industry settings. Recent studies, however, report a concerning phenomenon: training two-tower models on clicks collected by well-performing production systems leads to decreased ranking performance. This paper investigates two recent explanations for this observation: confounding effects from logging policies and model identifiability issues. We theoretically analyze the identifiability conditions of two-tower models, showing that either document swaps across positions or overlapping feature distributions are required to recover model parameters from clicks. We also investigate the effect of logging policies on two-tower models, finding that they introduce no bias when models perfectly capture user behavior. However, logging policies can amplify biases when models imperfectly capture user behavior, particularly when prediction errors correlate with document placement across positions. We propose a sample weighting technique to mitigate these effects and provide actionable insights for researchers and practitioners using two-tower models.
Unbiased Learning to Rank Meets Reality: Lessons from Baidu's Large-Scale Search Dataset
Apr 03, 2024Unbiased learning-to-rank (ULTR) is a well-established framework for learning from user clicks, which are often biased by the ranker collecting the data. While theoretically justified and extensively tested in simulation, ULTR techniques lack empirical validation, especially on modern search engines. The dataset released for the WSDM Cup 2023, collected from Baidu's search engine, offers a rare opportunity to assess the real-world performance of prominent ULTR techniques. Despite multiple submissions during the WSDM Cup 2023 and the subsequent NTCIR ULTRE-2 task, it remains unclear whether the observed improvements stem from applying ULTR or other learning techniques. We revisit and extend the available experiments. We find that unbiased learning-to-rank techniques do not bring clear performance improvements, especially compared to the stark differences brought by the choice of ranking loss and query-document features. Our experiments reveal that ULTR robustly improves click prediction. However, these gains in click prediction do not translate to enhanced ranking performance on expert relevance annotations, implying that conclusions strongly depend on how success is measured in this benchmark.
Evaluating and Correcting Performative Effects of Decision Support Systems via Causal Domain Shift
Mar 01, 2024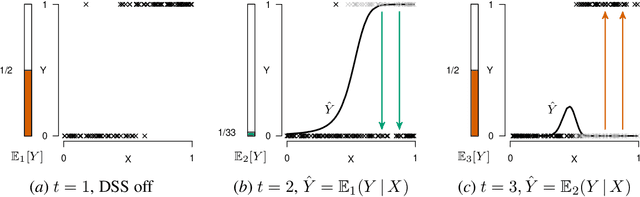



When predicting a target variable $Y$ from features $X$, the prediction $\hat{Y}$ can be performative: an agent might act on this prediction, affecting the value of $Y$ that we eventually observe. Performative predictions are deliberately prevalent in algorithmic decision support, where a Decision Support System (DSS) provides a prediction for an agent to affect the value of the target variable. When deploying a DSS in high-stakes settings (e.g. healthcare, law, predictive policing, or child welfare screening) it is imperative to carefully assess the performative effects of the DSS. In the case that the DSS serves as an alarm for a predicted negative outcome, naive retraining of the prediction model is bound to result in a model that underestimates the risk, due to effective workings of the previous model. In this work, we propose to model the deployment of a DSS as causal domain shift and provide novel cross-domain identification results for the conditional expectation $E[Y | X]$, allowing for pre- and post-hoc assessment of the deployment of the DSS, and for retraining of a model that assesses the risk under a baseline policy where the DSS is not deployed. Using a running example, we empirically show that a repeated regression procedure provides a practical framework for estimating these quantities, even when the data is affected by sample selection bias and selective labelling, offering for a practical, unified solution for multiple forms of target variable bias.
When Do Off-Policy and On-Policy Policy Gradient Methods Align?
Feb 19, 2024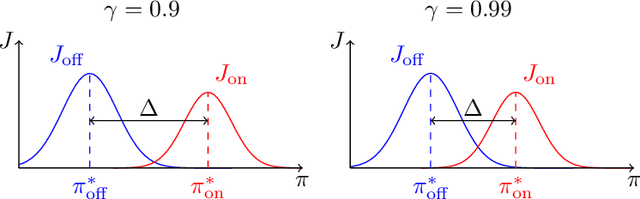
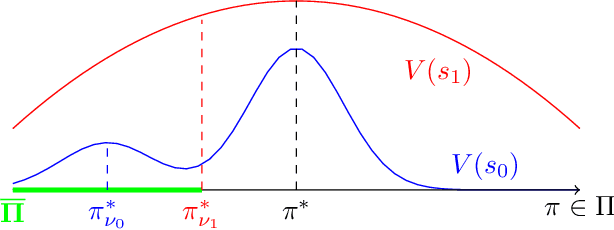
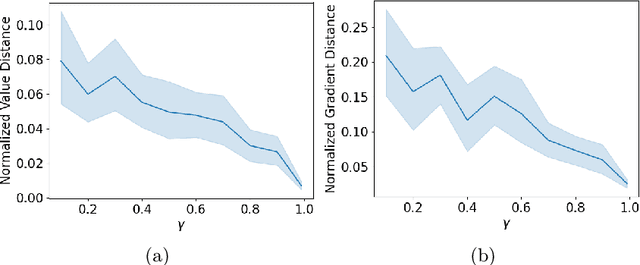
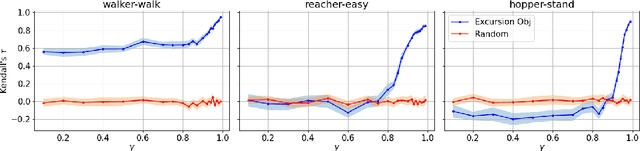
Policy gradient methods are widely adopted reinforcement learning algorithms for tasks with continuous action spaces. These methods succeeded in many application domains, however, because of their notorious sample inefficiency their use remains limited to problems where fast and accurate simulations are available. A common way to improve sample efficiency is to modify their objective function to be computable from off-policy samples without importance sampling. A well-established off-policy objective is the excursion objective. This work studies the difference between the excursion objective and the traditional on-policy objective, which we refer to as the on-off gap. We provide the first theoretical analysis showing conditions to reduce the on-off gap while establishing empirical evidence of shortfalls arising when these conditions are not met.
Modeling Latent Selection with Structural Causal Models
Jan 12, 2024

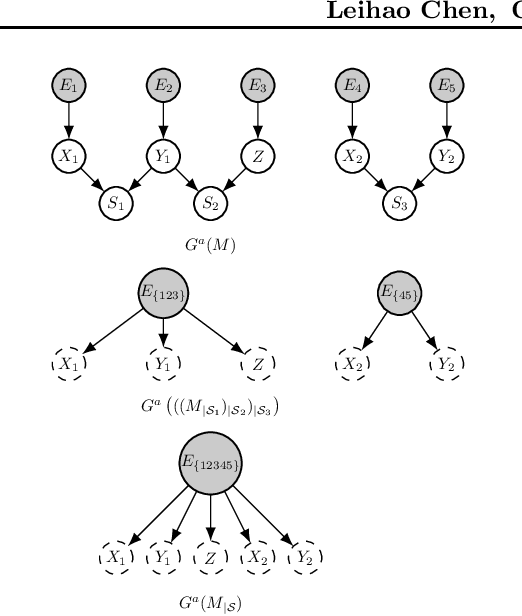

Selection bias is ubiquitous in real-world data, and can lead to misleading results if not dealt with properly. We introduce a conditioning operation on Structural Causal Models (SCMs) to model latent selection from a causal perspective. We show that the conditioning operation transforms an SCM with the presence of an explicit latent selection mechanism into an SCM without such selection mechanism, which partially encodes the causal semantics of the selected subpopulation according to the original SCM. Furthermore, we show that this conditioning operation preserves the simplicity, acyclicity, and linearity of SCMs, and commutes with marginalization. Thanks to these properties, combined with marginalization and intervention, the conditioning operation offers a valuable tool for conducting causal reasoning tasks within causal models where latent details have been abstracted away. We demonstrate by example how classical results of causal inference can be generalized to include selection bias and how the conditioning operation helps with modeling of real-world problems.
Fair Grading Algorithms for Randomized Exams
Apr 13, 2023



This paper studies grading algorithms for randomized exams. In a randomized exam, each student is asked a small number of random questions from a large question bank. The predominant grading rule is simple averaging, i.e., calculating grades by averaging scores on the questions each student is asked, which is fair ex-ante, over the randomized questions, but not fair ex-post, on the realized questions. The fair grading problem is to estimate the average grade of each student on the full question bank. The maximum-likelihood estimator for the Bradley-Terry-Luce model on the bipartite student-question graph is shown to be consistent with high probability when the number of questions asked to each student is at least the cubed-logarithm of the number of students. In an empirical study on exam data and in simulations, our algorithm based on the maximum-likelihood estimator significantly outperforms simple averaging in prediction accuracy and ex-post fairness even with a small class and exam size.
Correcting for Selection Bias and Missing Response in Regression using Privileged Information
Mar 29, 2023



When estimating a regression model, we might have data where some labels are missing, or our data might be biased by a selection mechanism. When the response or selection mechanism is ignorable (i.e., independent of the response variable given the features) one can use off-the-shelf regression methods; in the nonignorable case one typically has to adjust for bias. We observe that privileged data (i.e. data that is only available during training) might render a nonignorable selection mechanism ignorable, and we refer to this scenario as Privilegedly Missing at Random (PMAR). We propose a novel imputation-based regression method, named repeated regression, that is suitable for PMAR. We also consider an importance weighted regression method, and a doubly robust combination of the two. The proposed methods are easy to implement with most popular out-of-the-box regression algorithms. We empirically assess the performance of the proposed methods with extensive simulated experiments and on a synthetically augmented real-world dataset. We conclude that repeated regression can appropriately correct for bias, and can have considerable advantage over weighted regression, especially when extrapolating to regions of the feature space where response is never observed.
An Incentive Compatible Multi-Armed-Bandit Crowdsourcing Mechanism with Quality Assurance
Jun 17, 2015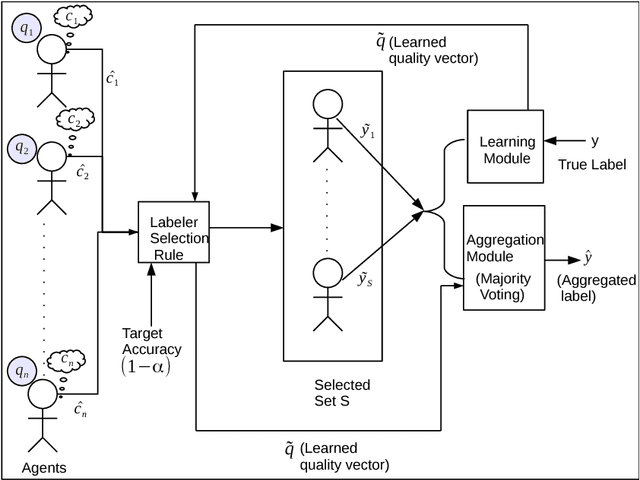

Consider a requester who wishes to crowdsource a series of identical binary labeling tasks to a pool of workers so as to achieve an assured accuracy for each task, in a cost optimal way. The workers are heterogeneous with unknown but fixed qualities and their costs are private. The problem is to select for each task an optimal subset of workers so that the outcome obtained from the selected workers guarantees a target accuracy level. The problem is a challenging one even in a non strategic setting since the accuracy of aggregated label depends on unknown qualities. We develop a novel multi-armed bandit (MAB) mechanism for solving this problem. First, we propose a framework, Assured Accuracy Bandit (AAB), which leads to an MAB algorithm, Constrained Confidence Bound for a Non Strategic setting (CCB-NS). We derive an upper bound on the number of time steps the algorithm chooses a sub-optimal set that depends on the target accuracy level and true qualities. A more challenging situation arises when the requester not only has to learn the qualities of the workers but also elicit their true costs. We modify the CCB-NS algorithm to obtain an adaptive exploration separated algorithm which we call { \em Constrained Confidence Bound for a Strategic setting (CCB-S)}. CCB-S algorithm produces an ex-post monotone allocation rule and thus can be transformed into an ex-post incentive compatible and ex-post individually rational mechanism that learns the qualities of the workers and guarantees a given target accuracy level in a cost optimal way. We provide a lower bound on the number of times any algorithm should select a sub-optimal set and we see that the lower bound matches our upper bound upto a constant factor. We provide insights on the practical implementation of this framework through an illustrative example and we show the efficacy of our algorithms through simulations.
Expectation Propogation for approximate inference in dynamic Bayesian networks
Dec 12, 2012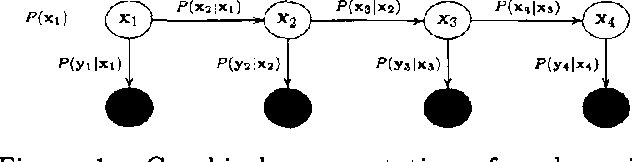
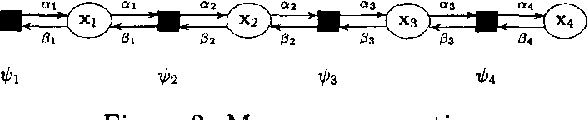
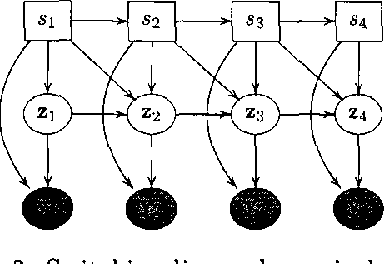
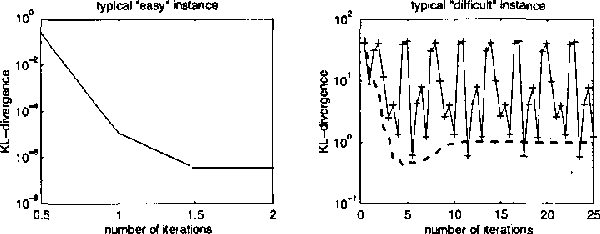
We describe expectation propagation for approximate inference in dynamic Bayesian networks as a natural extension of Pearl s exact belief propagation.Expectation propagation IS a greedy algorithm, converges IN many practical cases, but NOT always.We derive a DOUBLE - loop algorithm, guaranteed TO converge TO a local minimum OF a Bethe free energy.Furthermore, we show that stable fixed points OF (damped) expectation propagation correspond TO local minima OF this free energy, but that the converse need NOT be the CASE .We illustrate the algorithms BY applying them TO switching linear dynamical systems AND discuss implications FOR approximate inference IN general Bayesian networks.