 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplLLM: Fine-tuning LLMs to Discover Complementary Signals for Decision-making
Feb 23, 2026Multi-agent decision pipelines can outperform single agent workflows when complementarity holds, i.e., different agents bring unique information to the table to inform a final decision. We propose ComplLLM, a post-training framework based on decision theory that fine-tunes a decision-assistant LLM using complementary information as reward to output signals that complement existing agent decisions. We validate ComplLLM on synthetic and real-world tasks involving domain experts, demonstrating how the approach recovers known complementary information and produces plausible explanations of complementary signals to support downstream decision-makers.
Aligned Textual Scoring Rules
Jul 08, 2025Scoring rules elicit probabilistic predictions from a strategic agent by scoring the prediction against a ground truth state. A scoring rule is proper if, from the agent's perspective, reporting the true belief maximizes the expected score. With the development of language models, Wu and Hartline (2024) proposes a reduction from textual information elicitation to the numerical (i.e. probabilistic) information elicitation problem, which achieves provable properness for textual elicitation. However, not all proper scoring rules are well aligned with human preference over text. Our paper designs the Aligned Scoring rule (ASR) for text by optimizing and minimizing the mean squared error between a proper scoring rule and a reference score (e.g. human score). Our experiments show that our ASR outperforms previous methods in aligning with human preference while maintaining properness.
Smooth Calibration and Decision Making
Apr 22, 2025
Calibration requires predictor outputs to be consistent with their Bayesian posteriors. For machine learning predictors that do not distinguish between small perturbations, calibration errors are continuous in predictions, e.g., smooth calibration error (Foster and Hart, 2018), Distance to Calibration (Blasiok et al., 2023a). On the contrary, decision-makers who use predictions make optimal decisions discontinuously in probabilistic space, experiencing loss from miscalibration discontinuously. Calibration errors for decision-making are thus discontinuous, e.g., Expected Calibration Error (Foster and Vohra, 1997), and Calibration Decision Loss (Hu and Wu, 2024). Thus, predictors with a low calibration error for machine learning may suffer a high calibration error for decision-making, i.e., they may not be trustworthy for decision-makers optimizing assuming their predictions are correct. It is natural to ask if post-processing a predictor with a low calibration error for machine learning is without loss to achieve a low calibration error for decision-making. In our paper, we show that post-processing an online predictor with $\epsilon$ distance to calibration achieves $O(\sqrt{\epsilon})$ ECE and CDL, which is asymptotically optimal. The post-processing algorithm adds noise to make predictions differentially private. The optimal bound from low distance to calibration predictors from post-processing is non-optimal compared with existing online calibration algorithms that directly optimize for ECE and CDL.
The Value of Information in Human-AI Decision-making
Feb 10, 2025



Humans and AIs are often paired on decision tasks with the expectation of achieving complementary performance, where the combination of human and AI outperforms either one alone. However, how to improve performance of a human-AI team is often not clear without knowing more about what particular information and strategies each agent employs. We provide a decision-theoretic framework for characterizing the value of information -- and consequently, opportunities for agents to better exploit available information--in AI-assisted decision workflow. We demonstrate the use of the framework for model selection, empirical evaluation of human-AI performance, and explanation design. We propose a novel information-based instance-level explanation technique that adapts a conventional saliency-based explanation to explain information value in decision making.
ElicitationGPT: Text Elicitation Mechanisms via Language Models
Jun 13, 2024



Scoring rules evaluate probabilistic forecasts of an unknown state against the realized state and are a fundamental building block in the incentivized elicitation of information and the training of machine learning models. This paper develops mechanisms for scoring elicited text against ground truth text using domain-knowledge-free queries to a large language model (specifically ChatGPT) and empirically evaluates their alignment with human preferences. The empirical evaluation is conducted on peer reviews from a peer-grading dataset and in comparison to manual instructor scores for the peer reviews.
A Statistical Framework for Measuring AI Reliance
Jan 27, 2024



Humans frequently make decisions with the aid of artificially intelligent (AI) systems. A common pattern is for the AI to recommend an action to the human who retains control over the final decision. Researchers have identified ensuring that a human has appropriate reliance on an AI as a critical component of achieving complementary performance. We argue that the current definition of appropriate reliance used in such research lacks formal statistical grounding and can lead to contradictions. We propose a formal definition of reliance, based on statistical decision theory, which separates the concepts of reliance as the probability the decision-maker follows the AI's prediction from challenges a human may face in differentiating the signals and forming accurate beliefs about the situation. Our definition gives rise to a framework that can be used to guide the design and interpretation of studies on human-AI complementarity and reliance. Using recent AI-advised decision making studies from literature, we demonstrate how our framework can be used to separate the loss due to mis-reliance from the loss due to not accurately differentiating the signals. We evaluate these losses by comparing to a baseline and a benchmark for complementary performance defined by the expected payoff achieved by a rational agent facing the same decision task as the behavioral agents.
Decision Theoretic Foundations for Experiments Evaluating Human Decisions
Jan 25, 2024Decision-making with information displays is a key focus of research in areas like explainable AI, human-AI teaming, and data visualization. However, what constitutes a decision problem, and what is required for an experiment to be capable of concluding that human decisions are flawed in some way, remain open to speculation. We present a widely applicable definition of a decision problem synthesized from statistical decision theory and information economics. We argue that to attribute loss in human performance to forms of bias, an experiment must provide participants with the information that a rational agent would need to identify the normative decision. We evaluate the extent to which recent evaluations of decision-making from the literature on AI-assisted decisions achieve this criteria. We find that only 6 (17\%) of 35 studies that claim to identify biased behavior present participants with sufficient information to characterize their behavior as deviating from good decision-making. We motivate the value of studying well-defined decision problems by describing a characterization of performance losses they allow us to conceive. In contrast, the ambiguities of a poorly communicated decision problem preclude normative interpretation. We conclude with recommendations for practice.
Fair Grading Algorithms for Randomized Exams
Apr 13, 2023



This paper studies grading algorithms for randomized exams. In a randomized exam, each student is asked a small number of random questions from a large question bank. The predominant grading rule is simple averaging, i.e., calculating grades by averaging scores on the questions each student is asked, which is fair ex-ante, over the randomized questions, but not fair ex-post, on the realized questions. The fair grading problem is to estimate the average grade of each student on the full question bank. The maximum-likelihood estimator for the Bradley-Terry-Luce model on the bipartite student-question graph is shown to be consistent with high probability when the number of questions asked to each student is at least the cubed-logarithm of the number of students. In an empirical study on exam data and in simulations, our algorithm based on the maximum-likelihood estimator significantly outperforms simple averaging in prediction accuracy and ex-post fairness even with a small class and exam size.
Classification Protocols with Minimal Disclosure
Sep 06, 2022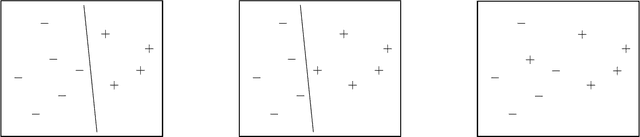
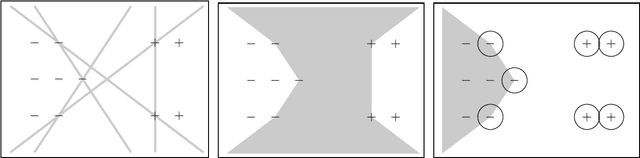
We consider multi-party protocols for classification that are motivated by applications such as e-discovery in court proceedings. We identify a protocol that guarantees that the requesting party receives all responsive documents and the sending party discloses the minimal amount of non-responsive documents necessary to prove that all responsive documents have been received. This protocol can be embedded in a machine learning framework that enables automated labeling of points and the resulting multi-party protocol is equivalent to the standard one-party classification problem (if the one-party classification problem satisfies a natural independence-of-irrelevant-alternatives property). Our formal guarantees focus on the case where there is a linear classifier that correctly partitions the documents.
No-Regret Learning in Bayesian Games
Nov 19, 2015
Recent price-of-anarchy analyses of games of complete information suggest that coarse correlated equilibria, which characterize outcomes resulting from no-regret learning dynamics, have near-optimal welfare. This work provides two main technical results that lift this conclusion to games of incomplete information, a.k.a., Bayesian games. First, near-optimal welfare in Bayesian games follows directly from the smoothness-based proof of near-optimal welfare in the same game when the private information is public. Second, no-regret learning dynamics converge to Bayesian coarse correlated equilibrium in these incomplete information games. These results are enabled by interpretation of a Bayesian game as a stochastic game of complete information.