 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Value of Information in Human-AI Decision-making
Feb 10, 2025



Humans and AIs are often paired on decision tasks with the expectation of achieving complementary performance, where the combination of human and AI outperforms either one alone. However, how to improve performance of a human-AI team is often not clear without knowing more about what particular information and strategies each agent employs. We provide a decision-theoretic framework for characterizing the value of information -- and consequently, opportunities for agents to better exploit available information--in AI-assisted decision workflow. We demonstrate the use of the framework for model selection, empirical evaluation of human-AI performance, and explanation design. We propose a novel information-based instance-level explanation technique that adapts a conventional saliency-based explanation to explain information value in decision making.
A Statistical Framework for Measuring AI Reliance
Jan 27, 2024



Humans frequently make decisions with the aid of artificially intelligent (AI) systems. A common pattern is for the AI to recommend an action to the human who retains control over the final decision. Researchers have identified ensuring that a human has appropriate reliance on an AI as a critical component of achieving complementary performance. We argue that the current definition of appropriate reliance used in such research lacks formal statistical grounding and can lead to contradictions. We propose a formal definition of reliance, based on statistical decision theory, which separates the concepts of reliance as the probability the decision-maker follows the AI's prediction from challenges a human may face in differentiating the signals and forming accurate beliefs about the situation. Our definition gives rise to a framework that can be used to guide the design and interpretation of studies on human-AI complementarity and reliance. Using recent AI-advised decision making studies from literature, we demonstrate how our framework can be used to separate the loss due to mis-reliance from the loss due to not accurately differentiating the signals. We evaluate these losses by comparing to a baseline and a benchmark for complementary performance defined by the expected payoff achieved by a rational agent facing the same decision task as the behavioral agents.
Learning-based Autonomous Channel Access in the Presence of Hidden Terminals
Jul 07, 2022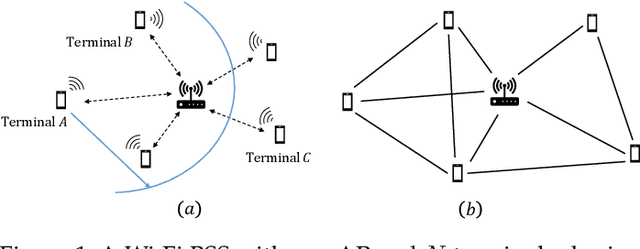
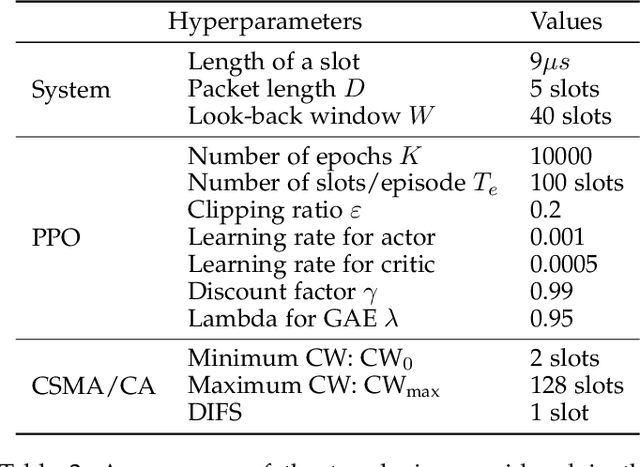
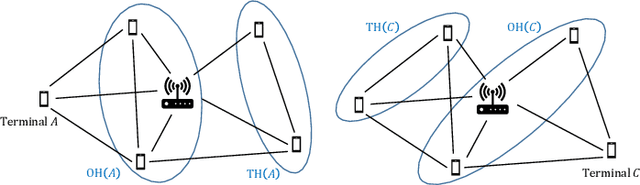
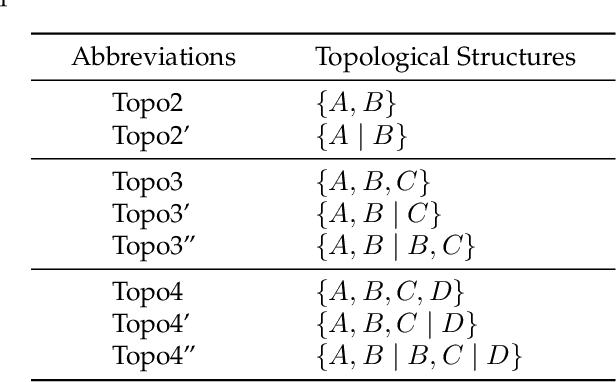
We consider the problem of autonomous channel access (AutoCA), where a group of terminals tries to discover a communication strategy with an access point (AP) via a common wireless channel in a distributed fashion. Due to the irregular topology and the limited communication range of terminals, a practical challenge for AutoCA is the hidden terminal problem, which is notorious in wireless networks for deteriorating the throughput and delay performances. To meet the challenge, this paper presents a new multi-agent deep reinforcement learning paradigm, dubbed MADRL-HT, tailored for AutoCA in the presence of hidden terminals. MADRL-HT exploits topological insights and transforms the observation space of each terminal into a scalable form independent of the number of terminals. To compensate for the partial observability, we put forth a look-back mechanism such that the terminals can infer behaviors of their hidden terminals from the carrier sensed channel states as well as feedback from the AP. A window-based global reward function is proposed, whereby the terminals are instructed to maximize the system throughput while balancing the terminals' transmission opportunities over the course of learning. Extensive numerical experiments verified the superior performance of our solution benchmarked against the legacy carrier-sense multiple access with collision avoidance (CSMA/CA) protocol.