 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAWN: Dependency-Aware Fast Inference for Diffusion LLMs
Feb 06, 2026Diffusion large language models (dLLMs) have shown advantages in text generation, particularly due to their inherent ability for parallel decoding. However, constrained by the quality--speed trade-off, existing inference solutions adopt conservative parallel strategies, leaving substantial efficiency potential underexplored. A core challenge is that parallel decoding assumes each position can be filled independently, but tokens are often semantically coupled. Thus, the correct choice at one position constrains valid choices at others. Without modeling these inter-token dependencies, parallel strategies produce deteriorated outputs. Motivated by this insight, we propose DAWN, a training-free, dependency-aware decoding method for fast dLLM inference. DAWN extracts token dependencies and leverages two key motivations: (1) positions dependent on unmasked certain positions become more reliable, (2) simultaneously unmasking strongly coupled uncertain positions induces errors. Given those findings, DAWN leverages a dependency graph to select more reliable unmasking positions at each iteration, achieving high parallelism with negligible loss in generation quality. Extensive experiments across multiple models and datasets demonstrate that DAWN speedups the inference by 1.80-8.06x over baselines while preserving the generation quality. Code is released at https://github.com/lizhuo-luo/DAWN.
Accelerating Parallel Diffusion Model Serving with Residual Compression
Jul 23, 2025Diffusion models produce realistic images and videos but require substantial computational resources, necessitating multi-accelerator parallelism for real-time deployment. However, parallel inference introduces significant communication overhead from exchanging large activations between devices, limiting efficiency and scalability. We present CompactFusion, a compression framework that significantly reduces communication while preserving generation quality. Our key observation is that diffusion activations exhibit strong temporal redundancy-adjacent steps produce highly similar activations, saturating bandwidth with near-duplicate data carrying little new information. To address this inefficiency, we seek a more compact representation that encodes only the essential information. CompactFusion achieves this via Residual Compression that transmits only compressed residuals (step-wise activation differences). Based on empirical analysis and theoretical justification, we show that it effectively removes redundant data, enabling substantial data reduction while maintaining high fidelity. We also integrate lightweight error feedback to prevent error accumulation. CompactFusion establishes a new paradigm for parallel diffusion inference, delivering lower latency and significantly higher generation quality than prior methods. On 4xL20, it achieves 3.0x speedup while greatly improving fidelity. It also uniquely supports communication-heavy strategies like sequence parallelism on slow networks, achieving 6.7x speedup over prior overlap-based method. CompactFusion applies broadly across diffusion models and parallel settings, and integrates easily without requiring pipeline rework. Portable implementation demonstrated on xDiT is publicly available at https://github.com/Cobalt-27/CompactFusion
A Joint Approach to Local Updating and Gradient Compression for Efficient Asynchronous Federated Learning
Jul 06, 2024



Asynchronous Federated Learning (AFL) confronts inherent challenges arising from the heterogeneity of devices (e.g., their computation capacities) and low-bandwidth environments, both potentially causing stale model updates (e.g., local gradients) for global aggregation. Traditional approaches mitigating the staleness of updates typically focus on either adjusting the local updating or gradient compression, but not both. Recognizing this gap, we introduce a novel approach that synergizes local updating with gradient compression. Our research begins by examining the interplay between local updating frequency and gradient compression rate, and their collective impact on convergence speed. The theoretical upper bound shows that the local updating frequency and gradient compression rate of each device are jointly determined by its computing power, communication capabilities and other factors. Building on this foundation, we propose an AFL framework called FedLuck that adaptively optimizes both local update frequency and gradient compression rates. Experiments on image classification and speech recognization show that FedLuck reduces communication consumption by 56% and training time by 55% on average, achieving competitive performance in heterogeneous and low-bandwidth scenarios compared to the baselines.
Empirical Bayes Estimation with Side Information: A Nonparametric Integrative Tweedie Approach
Aug 11, 2023



We investigate the problem of compound estimation of normal means while accounting for the presence of side information. Leveraging the empirical Bayes framework, we develop a nonparametric integrative Tweedie (NIT) approach that incorporates structural knowledge encoded in multivariate auxiliary data to enhance the precision of compound estimation. Our approach employs convex optimization tools to estimate the gradient of the log-density directly, enabling the incorporation of structural constraints. We conduct theoretical analyses of the asymptotic risk of NIT and establish the rate at which NIT converges to the oracle estimator. As the dimension of the auxiliary data increases, we accurately quantify the improvements in estimation risk and the associated deterioration in convergence rate. The numerical performance of NIT is illustrated through the analysis of both simulated and real data, demonstrating its superiority over existing methods.
FedLP: Layer-wise Pruning Mechanism for Communication-Computation Efficient Federated Learning
Mar 11, 2023



Federated learning (FL) has prevailed as an efficient and privacy-preserved scheme for distributed learning. In this work, we mainly focus on the optimization of computation and communication in FL from a view of pruning. By adopting layer-wise pruning in local training and federated updating, we formulate an explicit FL pruning framework, FedLP (Federated Layer-wise Pruning), which is model-agnostic and universal for different types of deep learning models. Two specific schemes of FedLP are designed for scenarios with homogeneous local models and heterogeneous ones. Both theoretical and experimental evaluations are developed to verify that FedLP relieves the system bottlenecks of communication and computation with marginal performance decay. To the best of our knowledge, FedLP is the first framework that formally introduces the layer-wise pruning into FL. Within the scope of federated learning, more variants and combinations can be further designed based on FedLP.
Learning-based Autonomous Channel Access in the Presence of Hidden Terminals
Jul 07, 2022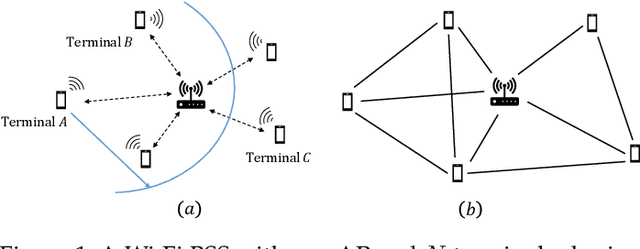
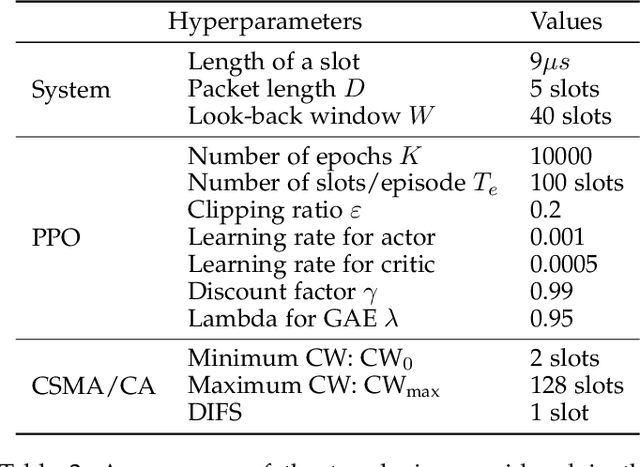
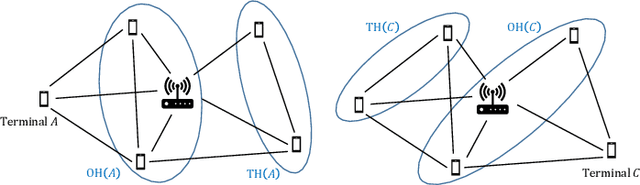
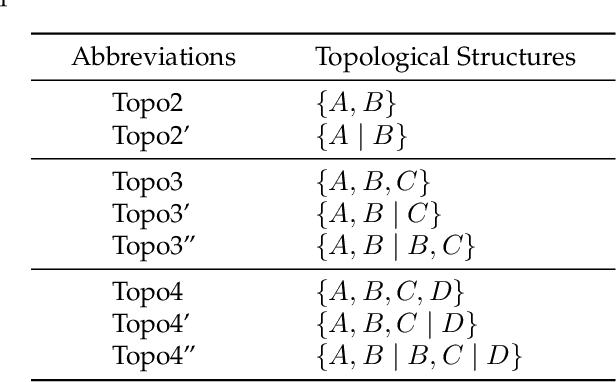
We consider the problem of autonomous channel access (AutoCA), where a group of terminals tries to discover a communication strategy with an access point (AP) via a common wireless channel in a distributed fashion. Due to the irregular topology and the limited communication range of terminals, a practical challenge for AutoCA is the hidden terminal problem, which is notorious in wireless networks for deteriorating the throughput and delay performances. To meet the challenge, this paper presents a new multi-agent deep reinforcement learning paradigm, dubbed MADRL-HT, tailored for AutoCA in the presence of hidden terminals. MADRL-HT exploits topological insights and transforms the observation space of each terminal into a scalable form independent of the number of terminals. To compensate for the partial observability, we put forth a look-back mechanism such that the terminals can infer behaviors of their hidden terminals from the carrier sensed channel states as well as feedback from the AP. A window-based global reward function is proposed, whereby the terminals are instructed to maximize the system throughput while balancing the terminals' transmission opportunities over the course of learning. Extensive numerical experiments verified the superior performance of our solution benchmarked against the legacy carrier-sense multiple access with collision avoidance (CSMA/CA) protocol.