 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-based Autonomous Channel Access in the Presence of Hidden Terminals
Paper and Code
Jul 07, 2022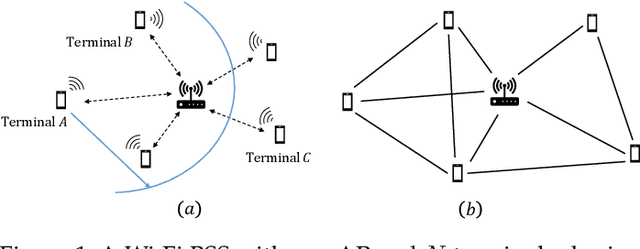
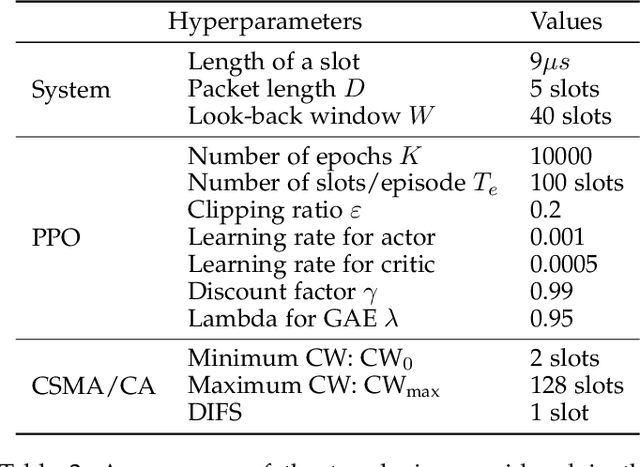
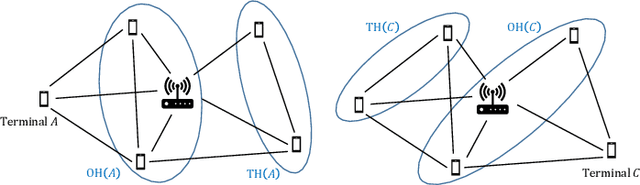
We consider the problem of autonomous channel access (AutoCA), where a group of terminals tries to discover a communication strategy with an access point (AP) via a common wireless channel in a distributed fashion. Due to the irregular topology and the limited communication range of terminals, a practical challenge for AutoCA is the hidden terminal problem, which is notorious in wireless networks for deteriorating the throughput and delay performances. To meet the challenge, this paper presents a new multi-agent deep reinforcement learning paradigm, dubbed MADRL-HT, tailored for AutoCA in the presence of hidden terminals. MADRL-HT exploits topological insights and transforms the observation space of each terminal into a scalable form independent of the number of terminals. To compensate for the partial observability, we put forth a look-back mechanism such that the terminals can infer behaviors of their hidden terminals from the carrier sensed channel states as well as feedback from the AP. A window-based global reward function is proposed, whereby the terminals are instructed to maximize the system throughput while balancing the terminals' transmission opportunities over the course of learning. Extensive numerical experiments verified the superior performance of our solution benchmarked against the legacy carrier-sense multiple access with collision avoidance (CSMA/CA) protocol.