 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving End-to-End Training of Retrieval-Augmented Generation Models via Joint Stochastic Approximation
Aug 25, 2025



Retrieval-augmented generation (RAG) has become a widely recognized paradigm to combine parametric memory with non-parametric memories. An RAG model consists of two serial connecting components (retriever and generator). A major challenge in end-to-end optimization of the RAG model is that marginalization over relevant passages (modeled as discrete latent variables) from a knowledge base is required. Traditional top-K marginalization and variational RAG (VRAG) suffer from biased or high-variance gradient estimates. In this paper, we propose and develop joint stochastic approximation (JSA) based end-to-end training of RAG, which is referred to as JSA-RAG. The JSA algorithm is a stochastic extension of the EM (expectation-maximization) algorithm and is particularly powerful in estimating discrete latent variable models. Extensive experiments are conducted on five datasets for two tasks (open-domain question answering, knowledge-grounded dialogs) and show that JSA-RAG significantly outperforms both vanilla RAG and VRAG. Further analysis shows the efficacy of JSA-RAG from the perspectives of generation, retrieval, and low-variance gradient estimate.
The 2nd FutureDial Challenge: Dialog Systems with Retrieval Augmented Generation (FutureDial-RAG)
May 21, 2024The 2nd FutureDial Challenge: Dialog Systems with Retrieval Augmented Generation (FutureDial-RAG), Co-located with SLT 2024
Prompt Pool based Class-Incremental Continual Learning for Dialog State Tracking
Nov 17, 2023



Continual learning is crucial for dialog state tracking (DST) in dialog systems, since requirements from users for new functionalities are often encountered. However, most of existing continual learning methods for DST require task identities during testing, which is a severe limit in real-world applications. In this paper, we aim to address continual learning of DST in the class-incremental scenario (namely the task identity is unknown in testing). Inspired by the recently emerging prompt tuning method that performs well on dialog systems, we propose to use the prompt pool method, where we maintain a pool of key-value paired prompts and select prompts from the pool according to the distance between the dialog history and the prompt keys. The proposed method can automatically identify tasks and select appropriate prompts during testing. We conduct experiments on Schema-Guided Dialog dataset (SGD) and another dataset collected from a real-world dialog application. Experiment results show that the prompt pool method achieves much higher joint goal accuracy than the baseline. After combining with a rehearsal buffer, the model performance can be further improved.
UniPCM: Universal Pre-trained Conversation Model with Task-aware Automatic Prompt
Sep 20, 2023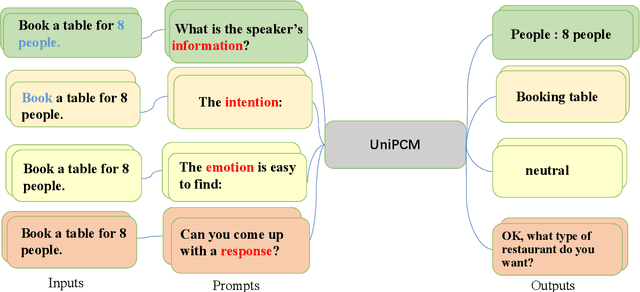
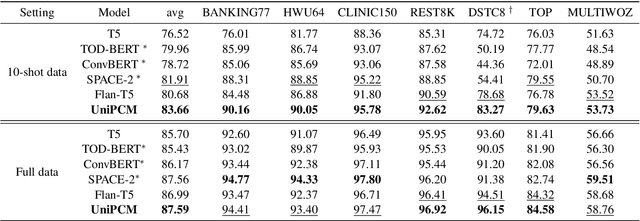
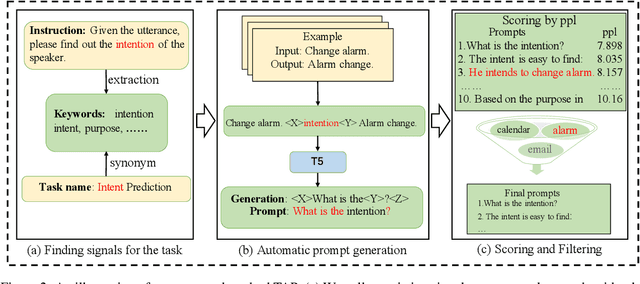
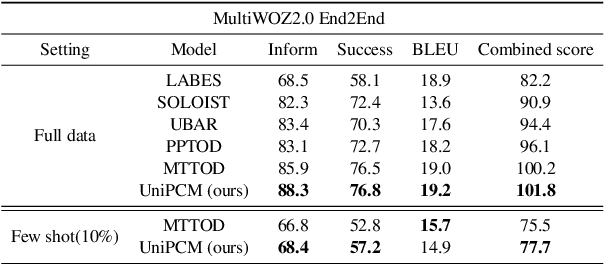
Recent research has shown that multi-task pre-training greatly improves the model's robustness and transfer ability, which is crucial for building a high-quality dialog system. However, most previous works on multi-task pre-training rely heavily on human-defined input format or prompt, which is not optimal in quality and quantity. In this work, we propose to use Task-based Automatic Prompt generation (TAP) to automatically generate high-quality prompts. Using the high-quality prompts generated, we scale the corpus of the pre-trained conversation model to 122 datasets from 15 dialog-related tasks, resulting in Universal Pre-trained Conversation Model (UniPCM), a powerful foundation model for various conversational tasks and different dialog systems. Extensive experiments have shown that UniPCM is robust to input prompts and capable of various dialog-related tasks. Moreover, UniPCM has strong transfer ability and excels at low resource scenarios, achieving SOTA results on 9 different datasets ranging from task-oriented dialog to open-domain conversation. Furthermore, we are amazed to find that TAP can generate prompts on par with those collected with crowdsourcing. The code is released with the paper.
Knowledge-Retrieval Task-Oriented Dialog Systems with Semi-Supervision
May 22, 2023Most existing task-oriented dialog (TOD) systems track dialog states in terms of slots and values and use them to query a database to get relevant knowledge to generate responses. In real-life applications, user utterances are noisier, and thus it is more difficult to accurately track dialog states and correctly secure relevant knowledge. Recently, a progress in question answering and document-grounded dialog systems is retrieval-augmented methods with a knowledge retriever. Inspired by such progress, we propose a retrieval-based method to enhance knowledge selection in TOD systems, which significantly outperforms the traditional database query method for real-life dialogs. Further, we develop latent variable model based semi-supervised learning, which can work with the knowledge retriever to leverage both labeled and unlabeled dialog data. Joint Stochastic Approximation (JSA) algorithm is employed for semi-supervised model training, and the whole system is referred to as that JSA-KRTOD. Experiments are conducted on a real-life dataset from China Mobile Custom-Service, called MobileCS, and show that JSA-KRTOD achieves superior performances in both labeled-only and semi-supervised settings.
A Generative User Simulator with GPT-based Architecture and Goal State Tracking for Reinforced Multi-Domain Dialog Systems
Oct 18, 2022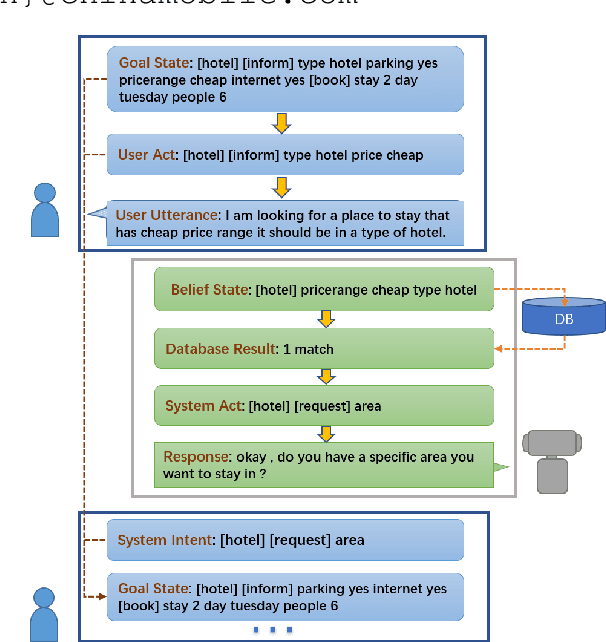

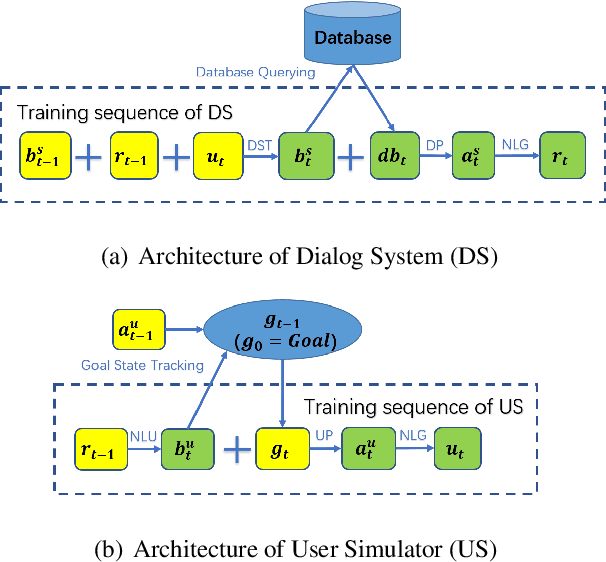
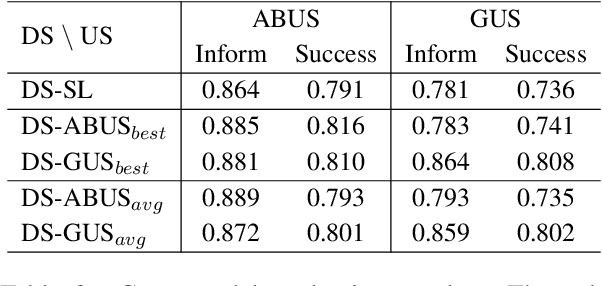
Building user simulators (USs) for reinforcement learning (RL) of task-oriented dialog systems (DSs) has gained more and more attention, which, however, still faces several fundamental challenges. First, it is unclear whether we can leverage pretrained language models to design, for example, GPT-2 based USs, to catch up and interact with the recently advanced GPT-2 based DSs. Second, an important ingredient in a US is that the user goal can be effectively incorporated and tracked; but how to flexibly integrate goal state tracking and develop an end-to-end trainable US for multi-domains has remained to be a challenge. In this work, we propose a generative user simulator (GUS) with GPT-2 based architecture and goal state tracking towards addressing the above two challenges. Extensive experiments are conducted on MultiWOZ2.1. Different DSs are trained via RL with GUS, the classic agenda-based user simulator (ABUS) and other ablation simulators respectively, and are compared for cross-model evaluation, corpus-based evaluation and human evaluation. The GUS achieves superior results in all three evaluation tasks.
Advancing Semi-Supervised Task Oriented Dialog Systems by JSA Learning of Discrete Latent Variable Models
Jul 25, 2022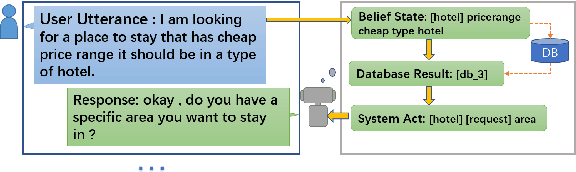
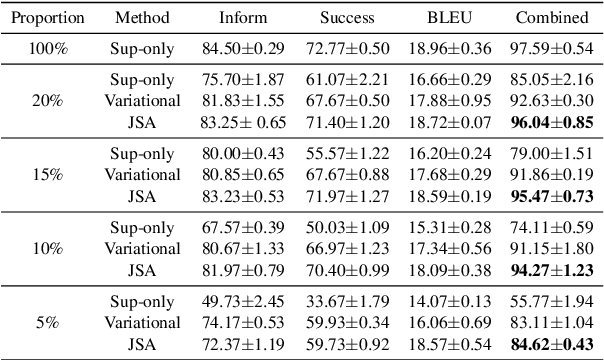
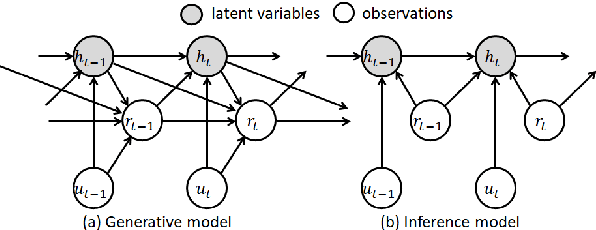
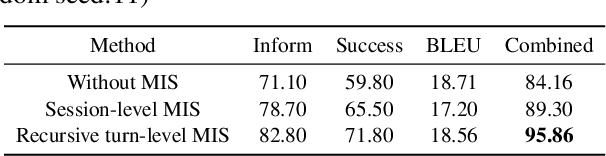
Developing semi-supervised task-oriented dialog (TOD) systems by leveraging unlabeled dialog data has attracted increasing interests. For semi-supervised learning of latent state TOD models, variational learning is often used, but suffers from the annoying high-variance of the gradients propagated through discrete latent variables and the drawback of indirectly optimizing the target log-likelihood. Recently, an alternative algorithm, called joint stochastic approximation (JSA), has emerged for learning discrete latent variable models with impressive performances. In this paper, we propose to apply JSA to semi-supervised learning of the latent state TOD models, which is referred to as JSA-TOD. To our knowledge, JSA-TOD represents the first work in developing JSA based semi-supervised learning of discrete latent variable conditional models for such long sequential generation problems like in TOD systems. Extensive experiments show that JSA-TOD significantly outperforms its variational learning counterpart. Remarkably, semi-supervised JSA-TOD using 20% labels performs close to the full-supervised baseline on MultiWOZ2.1.
Learning-based Autonomous Channel Access in the Presence of Hidden Terminals
Jul 07, 2022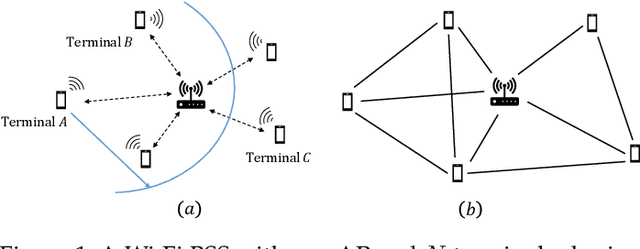
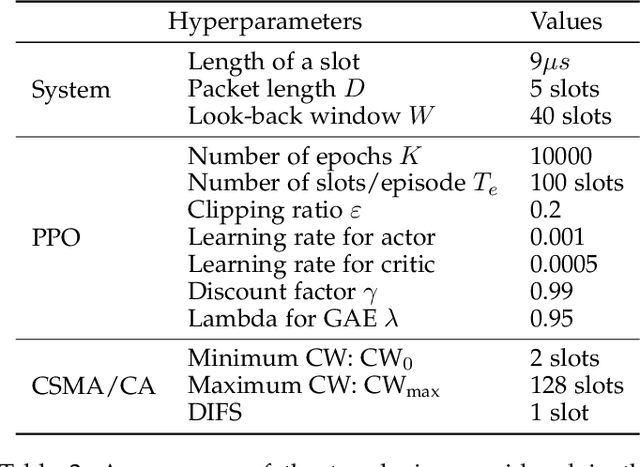
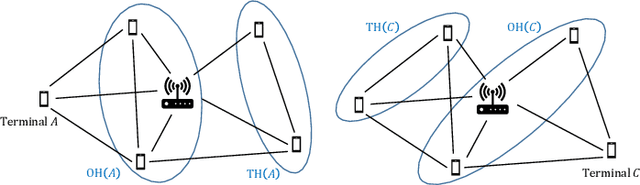
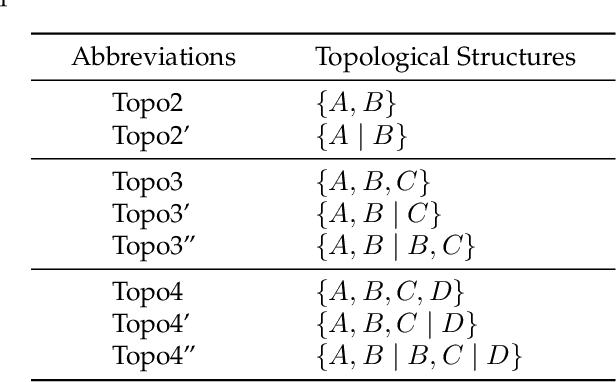
We consider the problem of autonomous channel access (AutoCA), where a group of terminals tries to discover a communication strategy with an access point (AP) via a common wireless channel in a distributed fashion. Due to the irregular topology and the limited communication range of terminals, a practical challenge for AutoCA is the hidden terminal problem, which is notorious in wireless networks for deteriorating the throughput and delay performances. To meet the challenge, this paper presents a new multi-agent deep reinforcement learning paradigm, dubbed MADRL-HT, tailored for AutoCA in the presence of hidden terminals. MADRL-HT exploits topological insights and transforms the observation space of each terminal into a scalable form independent of the number of terminals. To compensate for the partial observability, we put forth a look-back mechanism such that the terminals can infer behaviors of their hidden terminals from the carrier sensed channel states as well as feedback from the AP. A window-based global reward function is proposed, whereby the terminals are instructed to maximize the system throughput while balancing the terminals' transmission opportunities over the course of learning. Extensive numerical experiments verified the superior performance of our solution benchmarked against the legacy carrier-sense multiple access with collision avoidance (CSMA/CA) protocol.
Revisiting Markovian Generative Architectures for Efficient Task-Oriented Dialog Systems
Apr 13, 2022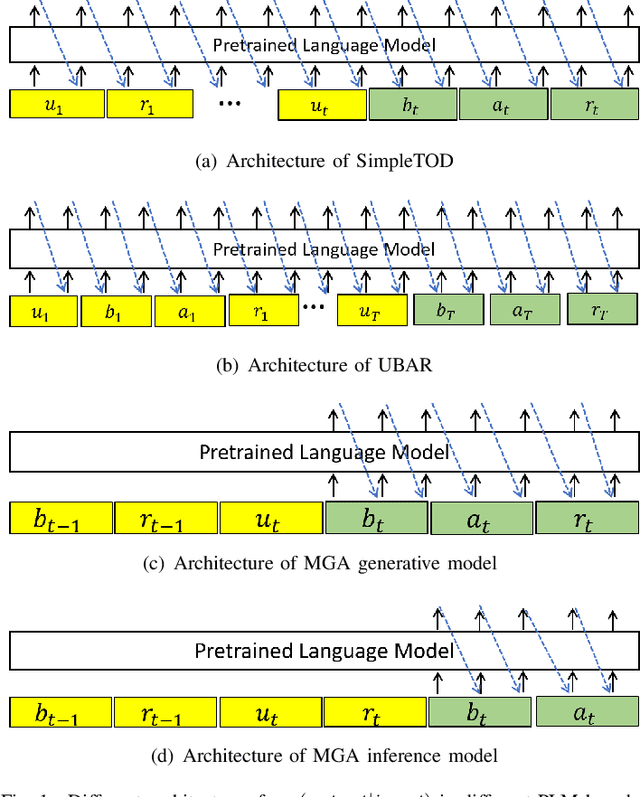
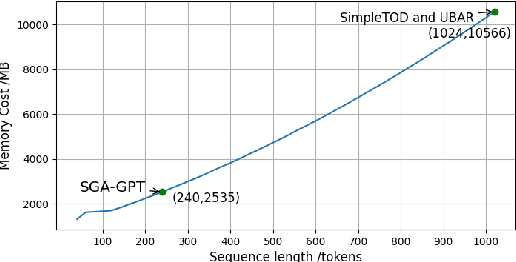
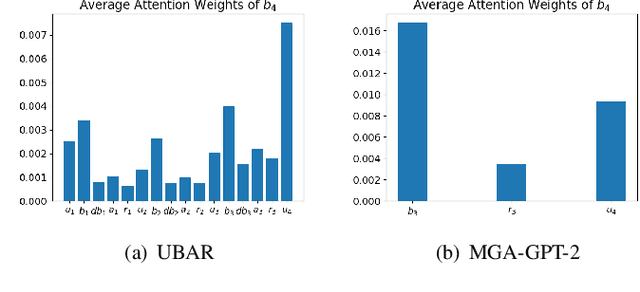
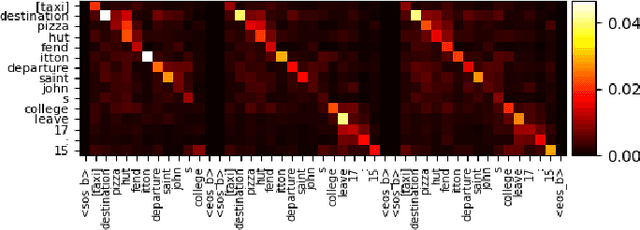
Recently, Transformer based pretrained language models (PLMs), such as GPT2 and T5, have been leveraged to build generative task-oriented dialog (TOD) systems. A drawback of existing PLM-based models is their non-Markovian architectures across turns, i.e., the whole history is used as the conditioning input at each turn, which brings inefficiencies in memory, computation and learning. In this paper, we propose to revisit Markovian Generative Architectures (MGA), which have been used in previous LSTM-based TOD systems, but not studied for PLM-based systems. Experiments on MultiWOZ2.1 show the efficiency advantages of the proposed Markovian PLM-based systems over their non-Markovian counterparts, in both supervised and semi-supervised settings.
Variational Latent-State GPT for Semi-supervised Task-Oriented Dialog Systems
Sep 09, 2021
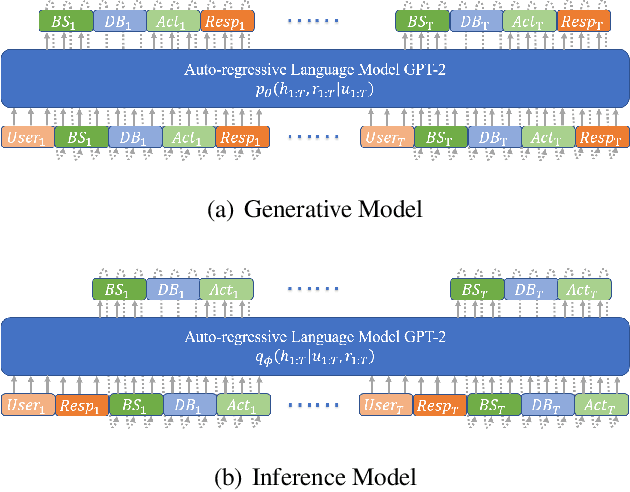

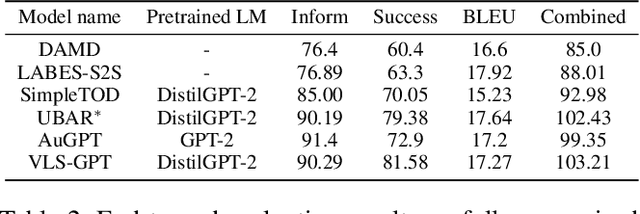
Recently, two approaches, fine-tuning large pre-trained language models and variational training, have attracted significant interests, separately, for semi-supervised end-to-end task-oriented dialog (TOD) systems. In this paper, we propose Variational Latent-State GPT model (VLS-GPT), which is the first to combine the strengths of the two approaches. Among many options of models, we propose the generative model and the inference model for variational learning of the end-to-end TOD system, both as auto-regressive language models based on GPT-2, which can be further trained over a mix of labeled and unlabeled dialog data in a semi-supervised manner. We develop the strategy of sampling-then-forward-computation, which successfully overcomes the memory explosion issue of using GPT in variational learning and speeds up training. Semi-supervised TOD experiments are conducted on two benchmark multi-domain datasets of different languages - MultiWOZ2.1 and CrossWOZ. VLS-GPT is shown to significantly outperform both supervised-only and semi-supervised baselines.