 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Markovian Generative Architectures for Efficient Task-Oriented Dialog Systems
Paper and Code
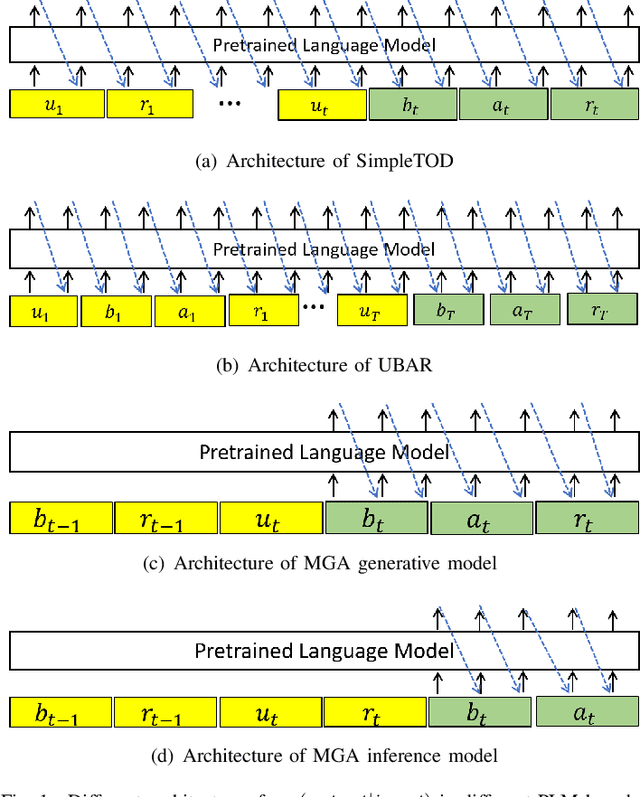
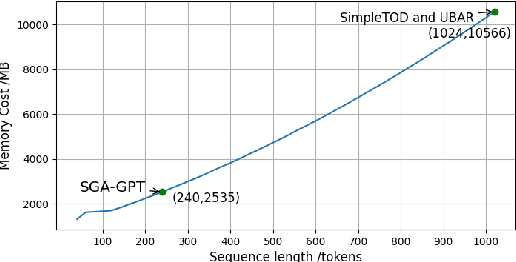
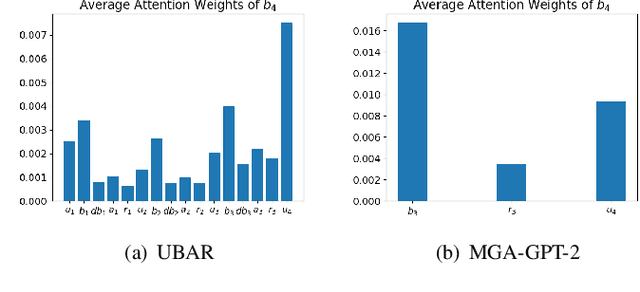
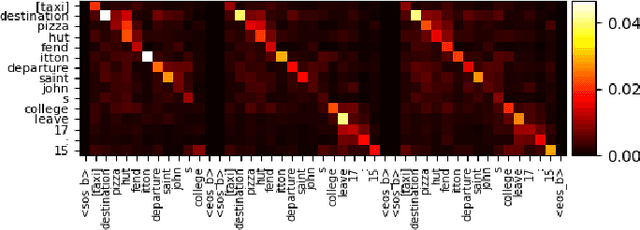
Recently, Transformer based pretrained language models (PLMs), such as GPT2 and T5, have been leveraged to build generative task-oriented dialog (TOD) systems. A drawback of existing PLM-based models is their non-Markovian architectures across turns, i.e., the whole history is used as the conditioning input at each turn, which brings inefficiencies in memory, computation and learning. In this paper, we propose to revisit Markovian Generative Architectures (MGA), which have been used in previous LSTM-based TOD systems, but not studied for PLM-based systems. Experiments on MultiWOZ2.1 show the efficiency advantages of the proposed Markovian PLM-based systems over their non-Markovian counterparts, in both supervised and semi-supervised settings.