 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonemes vs. Projectors: An Investigation of Speech-Language Interfaces for LLM-based ASR
Apr 10, 2026Integrating pretrained speech encoders with large language models (LLMs) is promising for ASR, but performance and data efficiency depend on the speech-language interface. A common choice is a learned projector that maps encoder features into the LLM embedding space, whereas an alternative is to expose discrete phoneme sequences to the LLM. Using the same encoder and LLM backbones, we compare phoneme-based and vanilla projector-based interfaces in high-resource English and low-resource Tatar. We also propose a BPE-phoneme interface that groups frequent local phoneme patterns while preserving explicit word-boundary cues for phoneme-to-grapheme generation. On LibriSpeech, the phoneme-based interface is competitive with the vanilla projector, and the BPE-phoneme interface yields further gains. On Tatar, the phoneme-based interface substantially outperforms the vanilla projector. We further find that phoneme supervision yields a phoneme-informed hybrid interface that is stronger than the vanilla projector.
Advancing LLM-based phoneme-to-grapheme for multilingual speech recognition
Mar 31, 2026Phoneme-based ASR factorizes recognition into speech-to-phoneme (S2P) and phoneme-to-grapheme (P2G), enabling cross-lingual acoustic sharing while keeping language-specific orthography in a separate module. While large language models (LLMs) are promising for P2G, multilingual P2G remains challenging due to language-aware generation and severe cross-language data imbalance. We study multilingual LLM-based P2G on the ten-language CV-Lang10 benchmark. We examine robustness strategies that account for S2P uncertainty, including DANP and Simplified SKM (S-SKM). S-SKM is a Monte Carlo approximation that avoids CTC-based S2P probability weighting in P2G training. Robust training and low-resource oversampling reduce the average WER from 10.56% to 7.66%.
CTC-TTS: LLM-based dual-streaming text-to-speech with CTC alignment
Feb 23, 2026Large-language-model (LLM)-based text-to-speech (TTS) systems can generate natural speech, but most are not designed for low-latency dual-streaming synthesis. High-quality dual-streaming TTS depends on accurate text--speech alignment and well-designed training sequences that balance synthesis quality and latency. Prior work often relies on GMM-HMM based forced-alignment toolkits (e.g., MFA), which are pipeline-heavy and less flexible than neural aligners; fixed-ratio interleaving of text and speech tokens struggles to capture text--speech alignment regularities. We propose CTC-TTS, which replaces MFA with a CTC based aligner and introduces a bi-word based interleaving strategy. Two variants are designed: CTC-TTS-L (token concatenation along the sequence length) for higher quality and CTC-TTS-F (embedding stacking along the feature dimension) for lower latency. Experiments show that CTC-TTS outperforms fixed-ratio interleaving and MFA-based baselines on streaming synthesis and zero-shot tasks. Speech samples are available at https://ctctts.github.io/.
Phoneme-based speech recognition driven by large language models and sampling marginalization
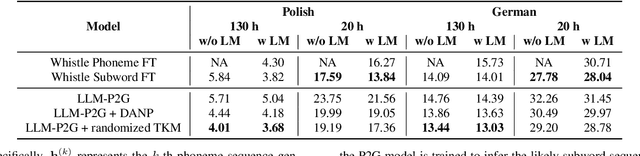
Dec 20, 2025Recently, the Large Language Model-based Phoneme-to-Grapheme (LLM-P2G) method has shown excellent performance in speech recognition tasks and has become a feasible direction to replace the traditional WFST decoding method. This framework takes into account both recognition accuracy and system scalability through two-stage modeling of phoneme prediction and text generation. However, the existing LLM-P2G adopts the Top-K Marginalized (TKM) training strategy, and its candidate phoneme sequences rely on beam search generation, which has problems such as insufficient path diversity, low training efficiency, and high resource overhead. To this end, this paper proposes a sampling marginalized training strategy (Sampling-K Marginalized, SKM), which replaces beam search with random sampling to generate candidate paths, improving marginalized modeling and training efficiency. Experiments were conducted on Polish and German datasets, and the results showed that SKM further improved the model learning convergence speed and recognition performance while maintaining the complexity of the model. Comparative experiments with a speech recognition method that uses a projector combined with a large language model (SpeechLLM) also show that the SKM-driven LLM-P2G has more advantages in recognition accuracy and structural simplicity. The study verified the practical value and application potential of this method in cross-language speech recognition systems.
Improving End-to-End Training of Retrieval-Augmented Generation Models via Joint Stochastic Approximation
Aug 25, 2025



Retrieval-augmented generation (RAG) has become a widely recognized paradigm to combine parametric memory with non-parametric memories. An RAG model consists of two serial connecting components (retriever and generator). A major challenge in end-to-end optimization of the RAG model is that marginalization over relevant passages (modeled as discrete latent variables) from a knowledge base is required. Traditional top-K marginalization and variational RAG (VRAG) suffer from biased or high-variance gradient estimates. In this paper, we propose and develop joint stochastic approximation (JSA) based end-to-end training of RAG, which is referred to as JSA-RAG. The JSA algorithm is a stochastic extension of the EM (expectation-maximization) algorithm and is particularly powerful in estimating discrete latent variable models. Extensive experiments are conducted on five datasets for two tasks (open-domain question answering, knowledge-grounded dialogs) and show that JSA-RAG significantly outperforms both vanilla RAG and VRAG. Further analysis shows the efficacy of JSA-RAG from the perspectives of generation, retrieval, and low-variance gradient estimate.
Lightweight and Robust Multi-Channel End-to-End Speech Recognition with Spherical Harmonic Transform
Jun 13, 2025


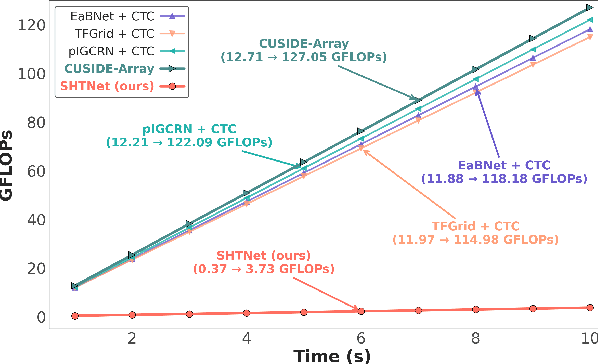
This paper presents SHTNet, a lightweight spherical harmonic transform (SHT) based framework, which is designed to address cross-array generalization challenges in multi-channel automatic speech recognition (ASR) through three key innovations. First, SHT based spatial sound field decomposition converts microphone signals into geometry-invariant spherical harmonic coefficients, isolating signal processing from array geometry. Second, the Spatio-Spectral Attention Fusion Network (SSAFN) combines coordinate-aware spatial modeling, refined self-attention channel combinator, and spectral noise suppression without conventional beamforming. Third, Rand-SHT training enhances robustness through random channel selection and array geometry reconstruction. The system achieves 39.26\% average CER across heterogeneous arrays (e.g., circular, square, and binaural) on datasets including Aishell-4, Alimeeting, and XMOS, with 97.1\% fewer computations than conventional neural beamformers.
LLM-based phoneme-to-grapheme for phoneme-based speech recognition
Jun 05, 2025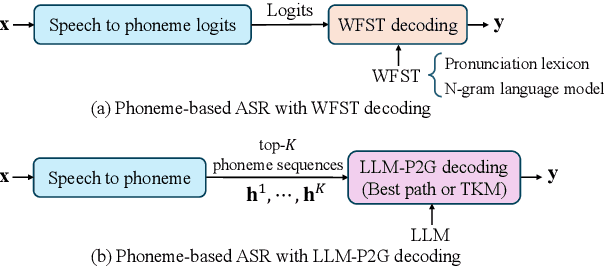
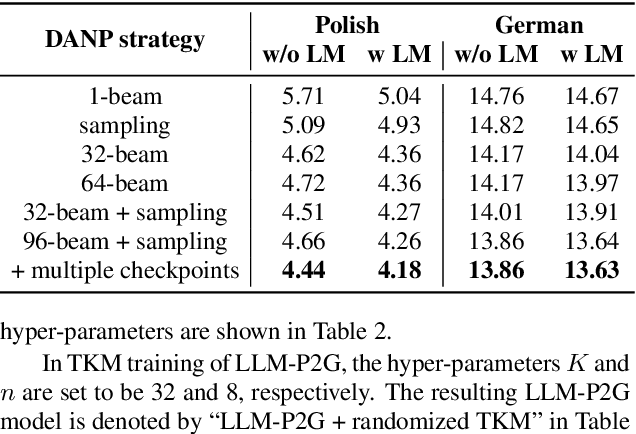
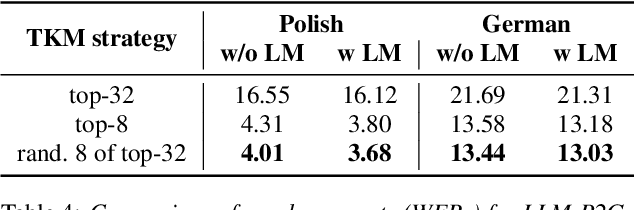
In automatic speech recognition (ASR), phoneme-based multilingual pre-training and crosslingual fine-tuning is attractive for its high data efficiency and competitive results compared to subword-based models. However, Weighted Finite State Transducer (WFST) based decoding is limited by its complex pipeline and inability to leverage large language models (LLMs). Therefore, we propose LLM-based phoneme-to-grapheme (LLM-P2G) decoding for phoneme-based ASR, consisting of speech-to-phoneme (S2P) and phoneme-to-grapheme (P2G). A challenge is that there seems to have information loss in cascading S2P and P2G. To address this challenge, we propose two training strategies: data augmentation with noisy phonemes (DANP), and randomized top-$K$ marginalized (TKM) training and decoding. Our experimental results show that LLM-P2G outperforms WFST-based systems in crosslingual ASR for Polish and German, by relative WER reductions of 3.6% and 6.9% respectively.
Joint-stochastic-approximation Random Fields with Application to Semi-supervised Learning
May 24, 2025



Our examination of deep generative models (DGMs) developed for semi-supervised learning (SSL), mainly GANs and VAEs, reveals two problems. First, mode missing and mode covering phenomenons are observed in genertion with GANs and VAEs. Second, there exists an awkward conflict between good classification and good generation in SSL by employing directed generative models. To address these problems, we formally present joint-stochastic-approximation random fields (JRFs) -- a new family of algorithms for building deep undirected generative models, with application to SSL. It is found through synthetic experiments that JRFs work well in balancing mode covering and mode missing, and match the empirical data distribution well. Empirically, JRFs achieve good classification results comparable to the state-of-art methods on widely adopted datasets -- MNIST, SVHN, and CIFAR-10 in SSL, and simultaneously perform good generation.
Joint-stochastic-approximation Autoencoders with Application to Semi-supervised Learning
May 24, 2025



Our examination of existing deep generative models (DGMs), including VAEs and GANs, reveals two problems. First, their capability in handling discrete observations and latent codes is unsatisfactory, though there are interesting efforts. Second, both VAEs and GANs optimize some criteria that are indirectly related to the data likelihood. To address these problems, we formally present Joint-stochastic-approximation (JSA) autoencoders - a new family of algorithms for building deep directed generative models, with application to semi-supervised learning. The JSA learning algorithm directly maximizes the data log-likelihood and simultaneously minimizes the inclusive KL divergence the between the posteriori and the inference model. We provide theoretical results and conduct a series of experiments to show its superiority such as being robust to structure mismatch between encoder and decoder, consistent handling of both discrete and continuous variables. Particularly we empirically show that JSA autoencoders with discrete latent space achieve comparable performance to other state-of-the-art DGMs with continuous latent space in semi-supervised tasks over the widely adopted datasets - MNIST and SVHN. To the best of our knowledge, this is the first demonstration that discrete latent variable models are successfully applied in the challenging semi-supervised tasks.
An Empirical Study of Retrieval Augmented Generation with Chain-of-Thought
Jul 22, 2024



Since the launch of ChatGPT at the end of 2022, generative dialogue models represented by ChatGPT have quickly become essential tools in daily life. As user expectations increase, enhancing the capability of generative dialogue models to solve complex problems has become a focal point of current research. This paper delves into the effectiveness of the RAFT (Retrieval Augmented Fine-Tuning) method in improving the performance of Generative dialogue models. RAFT combines chain-of-thought with model supervised fine-tuning (SFT) and retrieval augmented generation (RAG), which significantly enhanced the model's information extraction and logical reasoning abilities. We evaluated the RAFT method across multiple datasets and analysed its performance in various reasoning tasks, including long-form QA and short-form QA tasks, tasks in both Chinese and English, and supportive and comparison reasoning tasks. Notably, it addresses the gaps in previous research regarding long-form QA tasks and Chinese datasets. Moreover, we also evaluate the benefit of the chain-of-thought (CoT) in the RAFT method. This work offers valuable insights for studies focused on enhancing the performance of generative dialogue models.