 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorization-in-Loop: Proximal Fill-in Minimization for Sparse Matrix Reordering
Nov 12, 2025Fill-ins are new nonzero elements in the summation of the upper and lower triangular factors generated during LU factorization. For large sparse matrices, they will increase the memory usage and computational time, and be reduced through proper row or column arrangement, namely matrix reordering. Finding a row or column permutation with the minimal fill-ins is NP-hard, and surrogate objectives are designed to derive fill-in reduction permutations or learn a reordering function. However, there is no theoretical guarantee between the golden criterion and these surrogate objectives. Here we propose to learn a reordering network by minimizing \(l_1\) norm of triangular factors of the reordered matrix to approximate the exact number of fill-ins. The reordering network utilizes a graph encoder to predict row or column node scores. For inference, it is easy and fast to derive the permutation from sorting algorithms for matrices. For gradient based optimization, there is a large gap between the predicted node scores and resultant triangular factors in the optimization objective. To bridge the gap, we first design two reparameterization techniques to obtain the permutation matrix from node scores. The matrix is reordered by multiplying the permutation matrix. Then we introduce the factorization process into the objective function to arrive at target triangular factors. The overall objective function is optimized with the alternating direction method of multipliers and proximal gradient descent. Experimental results on benchmark sparse matrix collection SuiteSparse show the fill-in number and LU factorization time reduction of our proposed method is 20% and 17.8% compared with state-of-the-art baselines.
High-Fidelity Scientific Simulation Surrogates via Adaptive Implicit Neural Representations
Jun 07, 2025Effective surrogate models are critical for accelerating scientific simulations. Implicit neural representations (INRs) offer a compact and continuous framework for modeling spatially structured data, but they often struggle with complex scientific fields exhibiting localized, high-frequency variations. Recent approaches address this by introducing additional features along rigid geometric structures (e.g., grids), but at the cost of flexibility and increased model size. In this paper, we propose a simple yet effective alternative: Feature-Adaptive INR (FA-INR). FA-INR leverages cross-attention to an augmented memory bank to learn flexible feature representations, enabling adaptive allocation of model capacity based on data characteristics, rather than rigid structural assumptions. To further improve scalability, we introduce a coordinate-guided mixture of experts (MoE) that enhances the specialization and efficiency of feature representations. Experiments on three large-scale ensemble simulation datasets show that FA-INR achieves state-of-the-art fidelity while significantly reducing model size, establishing a new trade-off frontier between accuracy and compactness for INR-based surrogates.
NSFlow: An End-to-End FPGA Framework with Scalable Dataflow Architecture for Neuro-Symbolic AI
Apr 29, 2025Neuro-Symbolic AI (NSAI) is an emerging paradigm that integrates neural networks with symbolic reasoning to enhance the transparency, reasoning capabilities, and data efficiency of AI systems. Recent NSAI systems have gained traction due to their exceptional performance in reasoning tasks and human-AI collaborative scenarios. Despite these algorithmic advancements, executing NSAI tasks on existing hardware (e.g., CPUs, GPUs, TPUs) remains challenging, due to their heterogeneous computing kernels, high memory intensity, and unique memory access patterns. Moreover, current NSAI algorithms exhibit significant variation in operation types and scales, making them incompatible with existing ML accelerators. These challenges highlight the need for a versatile and flexible acceleration framework tailored to NSAI workloads. In this paper, we propose NSFlow, an FPGA-based acceleration framework designed to achieve high efficiency, scalability, and versatility across NSAI systems. NSFlow features a design architecture generator that identifies workload data dependencies and creates optimized dataflow architectures, as well as a reconfigurable array with flexible compute units, re-organizable memory, and mixed-precision capabilities. Evaluating across NSAI workloads, NSFlow achieves 31x speedup over Jetson TX2, more than 2x over GPU, 8x speedup over TPU-like systolic array, and more than 3x over Xilinx DPU. NSFlow also demonstrates enhanced scalability, with only 4x runtime increase when symbolic workloads scale by 150x. To the best of our knowledge, NSFlow is the first framework to enable real-time generalizable NSAI algorithms acceleration, demonstrating a promising solution for next-generation cognitive systems.
Neural Approaches to SAT Solving: Design Choices and Interpretability
Apr 01, 2025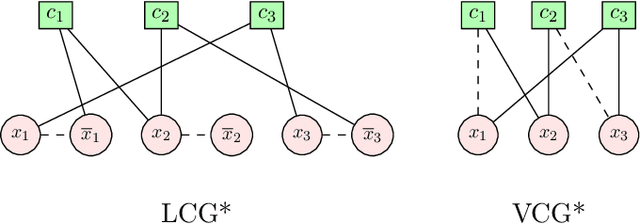
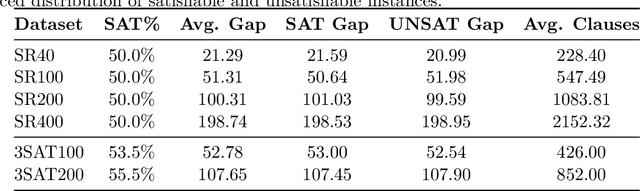
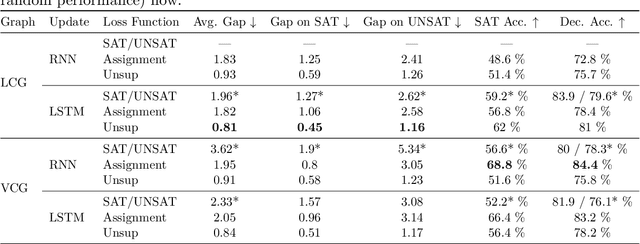
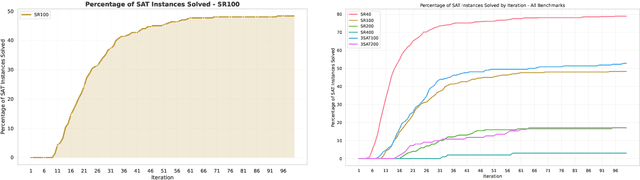
In this contribution, we provide a comprehensive evaluation of graph neural networks applied to Boolean satisfiability problems, accompanied by an intuitive explanation of the mechanisms enabling the model to generalize to different instances. We introduce several training improvements, particularly a novel closest assignment supervision method that dynamically adapts to the model's current state, significantly enhancing performance on problems with larger solution spaces. Our experiments demonstrate the suitability of variable-clause graph representations with recurrent neural network updates, which achieve good accuracy on SAT assignment prediction while reducing computational demands. We extend the base graph neural network into a diffusion model that facilitates incremental sampling and can be effectively combined with classical techniques like unit propagation. Through analysis of embedding space patterns and optimization trajectories, we show how these networks implicitly perform a process very similar to continuous relaxations of MaxSAT, offering an interpretable view of their reasoning process. This understanding guides our design choices and explains the ability of recurrent architectures to scale effectively at inference time beyond their training distribution, which we demonstrate with test-time scaling experiments.
GBR: Generative Bundle Refinement for High-fidelity Gaussian Splatting and Meshing
Dec 08, 2024



Gaussian splatting has gained attention for its efficient representation and rendering of 3D scenes using continuous Gaussian primitives. However, it struggles with sparse-view inputs due to limited geometric and photometric information, causing ambiguities in depth, shape, and texture. we propose GBR: Generative Bundle Refinement, a method for high-fidelity Gaussian splatting and meshing using only 4-6 input views. GBR integrates a neural bundle adjustment module to enhance geometry accuracy and a generative depth refinement module to improve geometry fidelity. More specifically, the neural bundle adjustment module integrates a foundation network to produce initial 3D point maps and point matches from unposed images, followed by bundle adjustment optimization to improve multiview consistency and point cloud accuracy. The generative depth refinement module employs a diffusion-based strategy to enhance geometric details and fidelity while preserving the scale. Finally, for Gaussian splatting optimization, we propose a multimodal loss function incorporating depth and normal consistency, geometric regularization, and pseudo-view supervision, providing robust guidance under sparse-view conditions. Experiments on widely used datasets show that GBR significantly outperforms existing methods under sparse-view inputs. Additionally, GBR demonstrates the ability to reconstruct and render large-scale real-world scenes, such as the Pavilion of Prince Teng and the Great Wall, with remarkable details using only 6 views.
Edge-guided inverse design of digital metamaterials for ultra-high-capacity on-chip multi-dimensional interconnect
Oct 10, 2024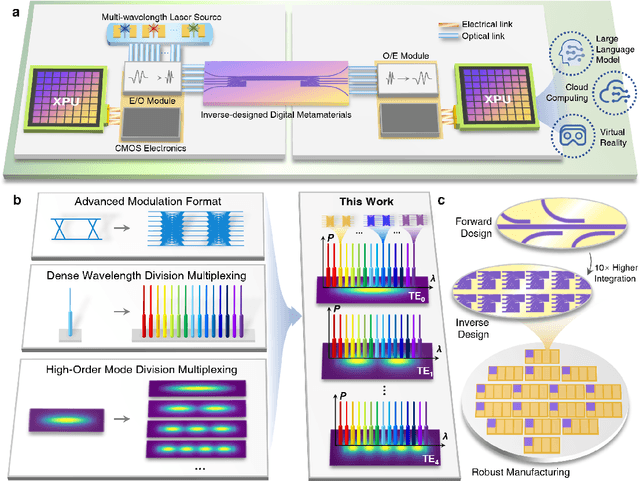
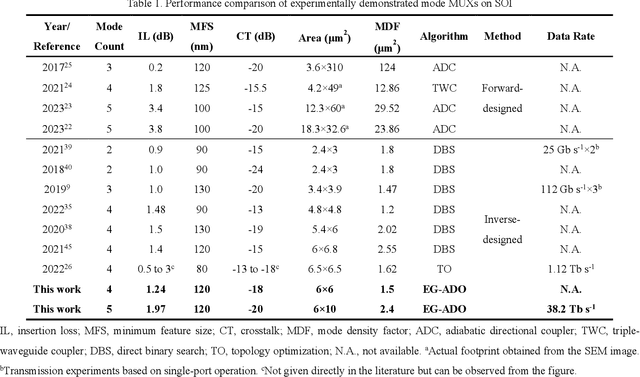
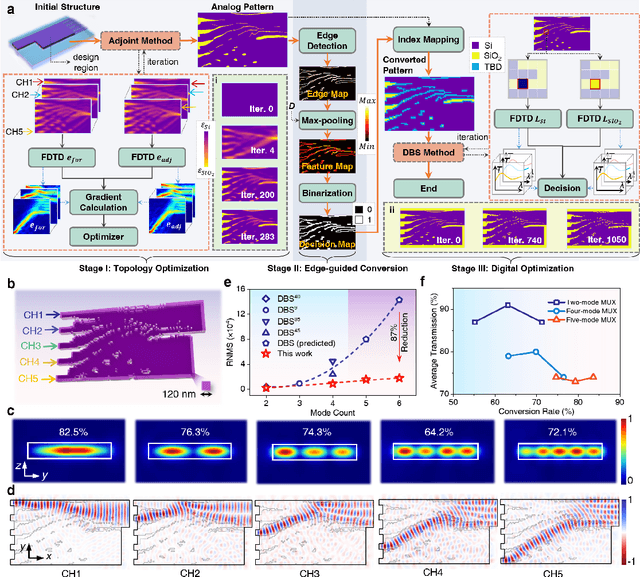
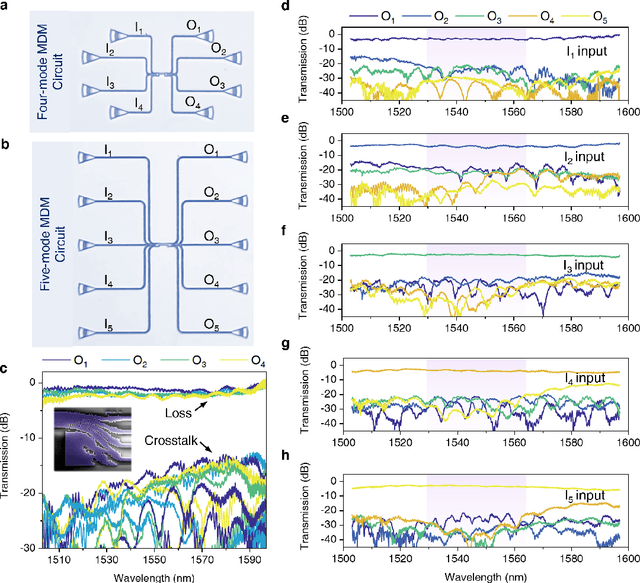
The escalating demands of compute-intensive applications, including artificial intelligence, urgently necessitate the adoption of sophisticated optical on-chip interconnect technologies to overcome critical bottlenecks in scaling future computing systems. This transition requires leveraging the inherent parallelism of wavelength and mode dimensions of light, complemented by high-order modulation formats, to significantly enhance data throughput. Here we experimentally demonstrate a novel synergy of these three dimensions, achieving multi-tens-of-terabits-per-second on-chip interconnects using ultra-broadband, multi-mode digital metamaterials. Employing a highly efficient edge-guided analog-and-digital optimization method, we inversely design foundry-compatible, robust, and multi-port digital metamaterials with an 8xhigher computational efficiency. Using a packaged five-mode multiplexing chip, we demonstrate a single-wavelength interconnect capacity of 1.62 Tbit s-1 and a record-setting multi-dimensional interconnect capacity of 38.2 Tbit s-1 across 5 modes and 88 wavelength channels. A theoretical analysis suggests that further system optimization can enable on-chip interconnects to reach sub-petabit-per-second data transmission rates. This study highlights the transformative potential of optical interconnect technologies to surmount the constraints of electronic links, thus setting the stage for next-generation datacenter and optical compute interconnects.
FedNE: Surrogate-Assisted Federated Neighbor Embedding for Dimensionality Reduction
Sep 17, 2024



Federated learning (FL) has rapidly evolved as a promising paradigm that enables collaborative model training across distributed participants without exchanging their local data. Despite its broad applications in fields such as computer vision, graph learning, and natural language processing, the development of a data projection model that can be effectively used to visualize data in the context of FL is crucial yet remains heavily under-explored. Neighbor embedding (NE) is an essential technique for visualizing complex high-dimensional data, but collaboratively learning a joint NE model is difficult. The key challenge lies in the objective function, as effective visualization algorithms like NE require computing loss functions among pairs of data. In this paper, we introduce \textsc{FedNE}, a novel approach that integrates the \textsc{FedAvg} framework with the contrastive NE technique, without any requirements of shareable data. To address the lack of inter-client repulsion which is crucial for the alignment in the global embedding space, we develop a surrogate loss function that each client learns and shares with each other. Additionally, we propose a data-mixing strategy to augment the local data, aiming to relax the problems of invisible neighbors and false neighbors constructed by the local $k$NN graphs. We conduct comprehensive experiments on both synthetic and real-world datasets. The results demonstrate that our \textsc{FedNE} can effectively preserve the neighborhood data structures and enhance the alignment in the global embedding space compared to several baseline methods.
CUSIDE-T: Chunking, Simulating Future and Decoding for Transducer based Streaming ASR
Jul 14, 2024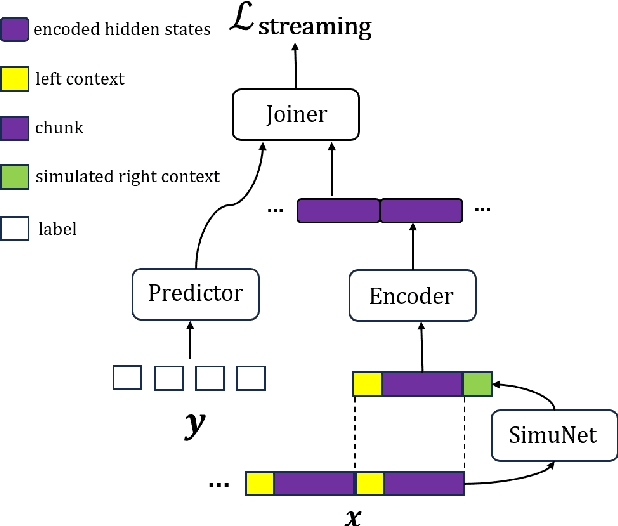
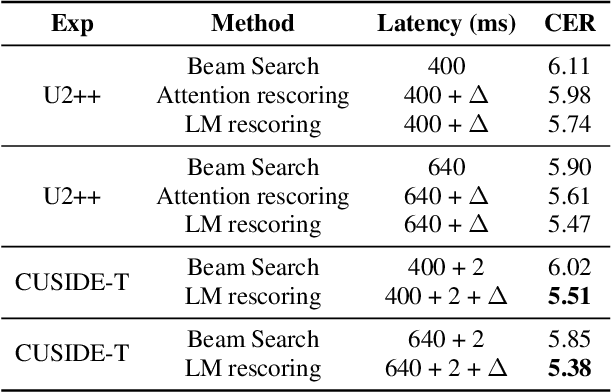
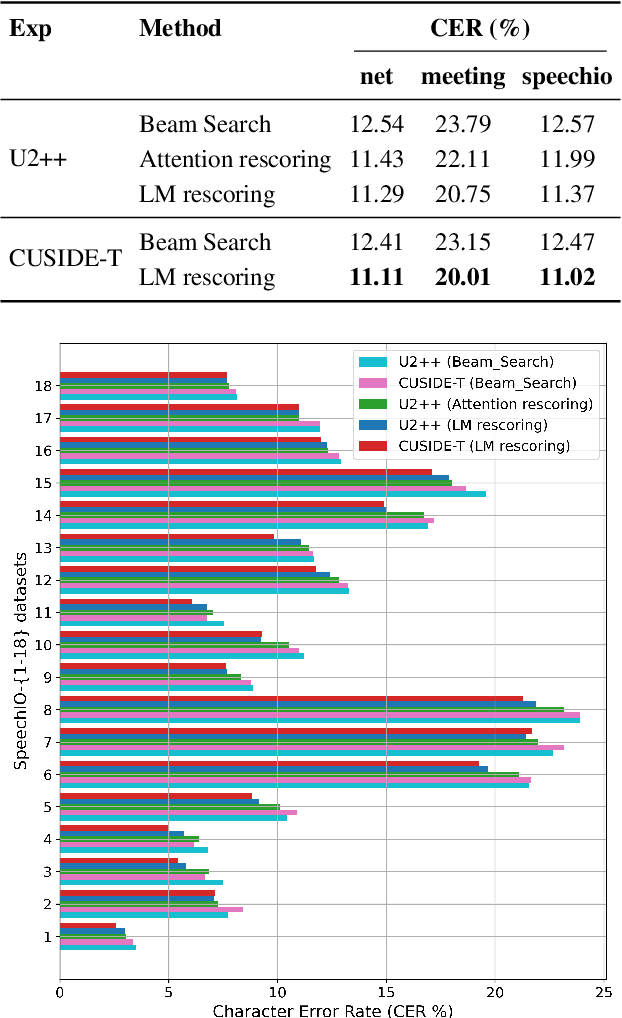
Streaming automatic speech recognition (ASR) is very important for many real-world ASR applications. However, a notable challenge for streaming ASR systems lies in balancing operational performance against latency constraint. Recently, a method of chunking, simulating future context and decoding, called CUSIDE, has been proposed for connectionist temporal classification (CTC) based streaming ASR, which obtains a good balance between reduced latency and high recognition accuracy. In this paper, we present CUSIDE-T, which successfully adapts the CUSIDE method over the recurrent neural network transducer (RNN-T) ASR architecture, instead of being based on the CTC architecture. We also incorporate language model rescoring in CUSIDE-T to further enhance accuracy, while only bringing a small additional latency. Extensive experiments are conducted over the AISHELL-1, WenetSpeech and SpeechIO datasets, comparing CUSIDE-T and U2++ (both based on RNN-T). U2++ is an existing counterpart of chunk based streaming ASR method. It is shown that CUSIDE-T achieves superior accuracy performance for streaming ASR, with equal settings of latency.
Deep Learning Models for River Classification at Sub-Meter Resolutions from Multispectral and Panchromatic Commercial Satellite Imagery
Dec 27, 2022



Remote sensing of the Earth's surface water is critical in a wide range of environmental studies, from evaluating the societal impacts of seasonal droughts and floods to the large-scale implications of climate change. Consequently, a large literature exists on the classification of water from satellite imagery. Yet, previous methods have been limited by 1) the spatial resolution of public satellite imagery, 2) classification schemes that operate at the pixel level, and 3) the need for multiple spectral bands. We advance the state-of-the-art by 1) using commercial imagery with panchromatic and multispectral resolutions of 30 cm and 1.2 m, respectively, 2) developing multiple fully convolutional neural networks (FCN) that can learn the morphological features of water bodies in addition to their spectral properties, and 3) FCN that can classify water even from panchromatic imagery. This study focuses on rivers in the Arctic, using images from the Quickbird, WorldView, and GeoEye satellites. Because no training data are available at such high resolutions, we construct those manually. First, we use the RGB, and NIR bands of the 8-band multispectral sensors. Those trained models all achieve excellent precision and recall over 90% on validation data, aided by on-the-fly preprocessing of the training data specific to satellite imagery. In a novel approach, we then use results from the multispectral model to generate training data for FCN that only require panchromatic imagery, of which considerably more is available. Despite the smaller feature space, these models still achieve a precision and recall of over 85%. We provide our open-source codes and trained model parameters to the remote sensing community, which paves the way to a wide range of environmental hydrology applications at vastly superior accuracies and 2 orders of magnitude higher spatial resolution than previously possible.
* 21 pages, 10 figures, 3 tables
On Pre-Training for Federated Learning
Jun 23, 2022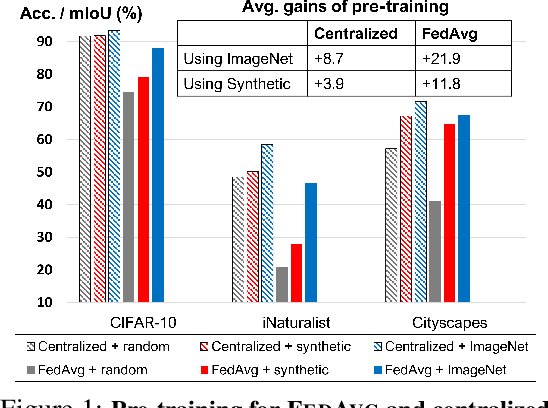
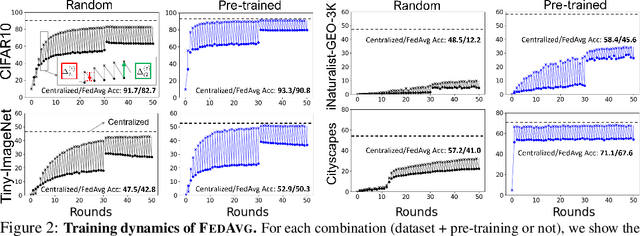
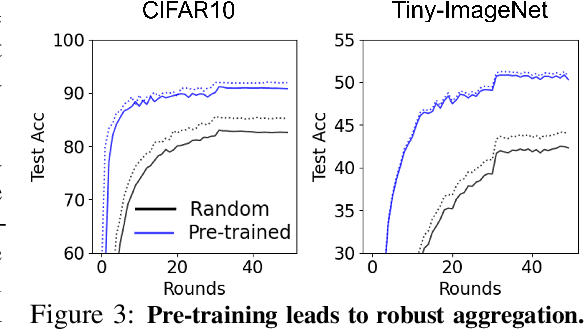
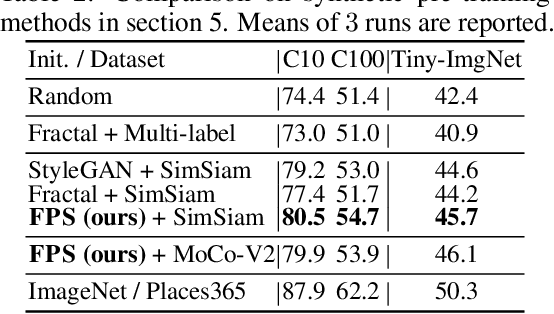
In most of the literature on federated learning (FL), neural networks are initialized with random weights. In this paper, we present an empirical study on the effect of pre-training on FL. Specifically, we aim to investigate if pre-training can alleviate the drastic accuracy drop when clients' decentralized data are non-IID. We focus on FedAvg, the fundamental and most widely used FL algorithm. We found that pre-training does largely close the gap between FedAvg and centralized learning under non-IID data, but this does not come from alleviating the well-known model drifting problem in FedAvg's local training. Instead, how pre-training helps FedAvg is by making FedAvg's global aggregation more stable. When pre-training using real data is not feasible for FL, we propose a novel approach to pre-train with synthetic data. On various image datasets (including one for segmentation), our approach with synthetic pre-training leads to a notable gain, essentially a critical step toward scaling up federated learning for real-world applications.