 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Pre-Training for Federated Learning
Paper and Code
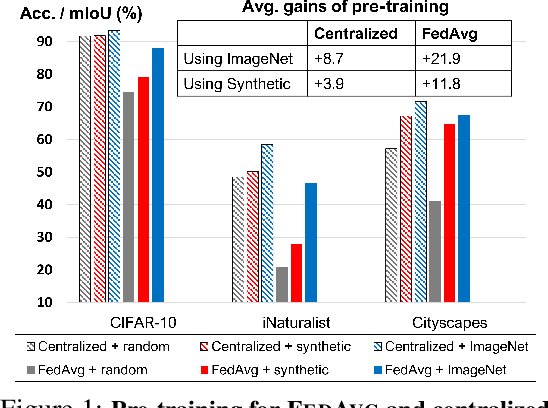
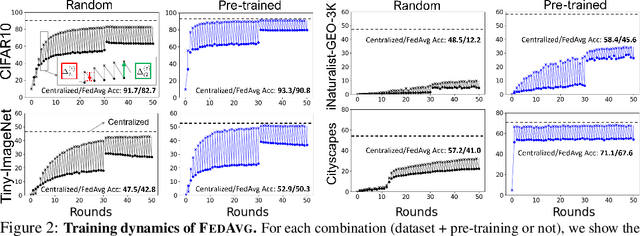
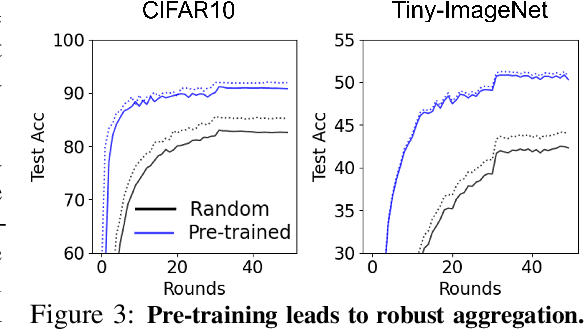
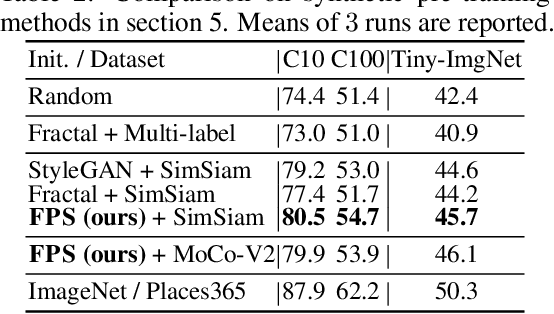
In most of the literature on federated learning (FL), neural networks are initialized with random weights. In this paper, we present an empirical study on the effect of pre-training on FL. Specifically, we aim to investigate if pre-training can alleviate the drastic accuracy drop when clients' decentralized data are non-IID. We focus on FedAvg, the fundamental and most widely used FL algorithm. We found that pre-training does largely close the gap between FedAvg and centralized learning under non-IID data, but this does not come from alleviating the well-known model drifting problem in FedAvg's local training. Instead, how pre-training helps FedAvg is by making FedAvg's global aggregation more stable. When pre-training using real data is not feasible for FL, we propose a novel approach to pre-train with synthetic data. On various image datasets (including one for segmentation), our approach with synthetic pre-training leads to a notable gain, essentially a critical step toward scaling up federated learning for real-world applications.