 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons Learned from a Unifying Empirical Study of Parameter-Efficient Transfer Learning (PETL) in Visual Recognition
Sep 24, 2024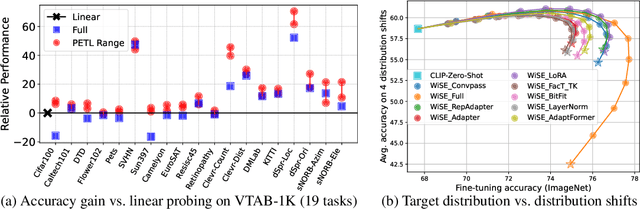
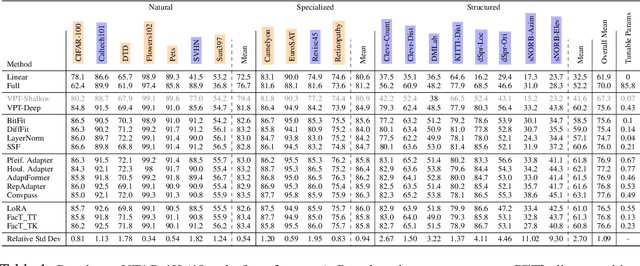


Parameter-efficient transfer learning (PETL) has attracted significant attention lately, due to the increasing size of pre-trained models and the need to fine-tune (FT) them for superior downstream performance. This community-wide enthusiasm has sparked a plethora of new methods. Nevertheless, a systematic study to understand their performance and suitable application scenarios is lacking, leaving questions like when to apply PETL and which method to use largely unanswered. In this paper, we conduct a unifying empirical study of representative PETL methods in the context of Vision Transformers. We systematically tune their hyper-parameters to fairly compare their accuracy on downstream tasks. Our study not only offers a valuable user guide but also unveils several new insights. First, if tuned carefully, different PETL methods can obtain quite similar accuracy in the low-shot benchmark VTAB-1K. This includes simple methods like FT the bias terms that were reported inferior. Second, though with similar accuracy, we find that PETL methods make different mistakes and high-confidence predictions, likely due to their different inductive biases. Such an inconsistency (or complementariness) opens up the opportunity for ensemble methods, and we make preliminary attempts at this. Third, going beyond the commonly used low-shot tasks, we find that PETL is also useful in many-shot regimes -- it achieves comparable and sometimes better accuracy than full FT, using much fewer learnable parameters. Last but not least, we investigate PETL's ability to preserve a pre-trained model's robustness to distribution shifts (e.g., a CLIP backbone). Perhaps not surprisingly, PETL methods outperform full FT alone. However, with weight-space ensembles, the fully FT model can achieve a better balance between downstream and out-of-distribution performance, suggesting a future research direction for PETL.
Fine-Tuning is Fine, if Calibrated
Sep 24, 2024



Fine-tuning is arguably the most straightforward way to tailor a pre-trained model (e.g., a foundation model) to downstream applications, but it also comes with the risk of losing valuable knowledge the model had learned in pre-training. For example, fine-tuning a pre-trained classifier capable of recognizing a large number of classes to master a subset of classes at hand is shown to drastically degrade the model's accuracy in the other classes it had previously learned. As such, it is hard to further use the fine-tuned model when it encounters classes beyond the fine-tuning data. In this paper, we systematically dissect the issue, aiming to answer the fundamental question, ''What has been damaged in the fine-tuned model?'' To our surprise, we find that the fine-tuned model neither forgets the relationship among the other classes nor degrades the features to recognize these classes. Instead, the fine-tuned model often produces more discriminative features for these other classes, even if they were missing during fine-tuning! {What really hurts the accuracy is the discrepant logit scales between the fine-tuning classes and the other classes}, implying that a simple post-processing calibration would bring back the pre-trained model's capability and at the same time unveil the feature improvement over all classes. We conduct an extensive empirical study to demonstrate the robustness of our findings and provide preliminary explanations underlying them, suggesting new directions for future theoretical analysis. Our code is available at https://github.com/OSU-MLB/Fine-Tuning-Is-Fine-If-Calibrated.
Bringing Back the Context: Camera Trap Species Identification as Link Prediction on Multimodal Knowledge Graphs
Jan 08, 2024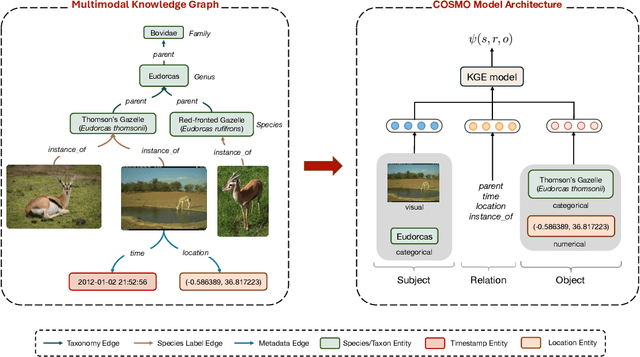
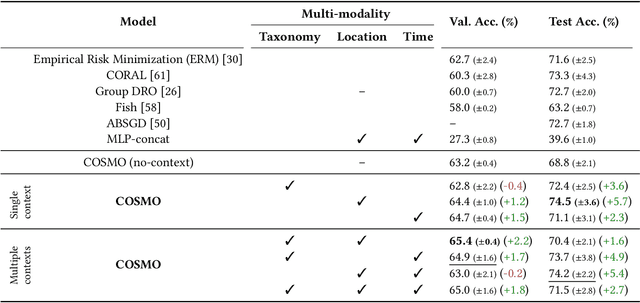
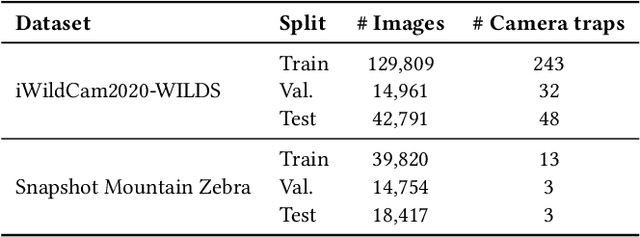
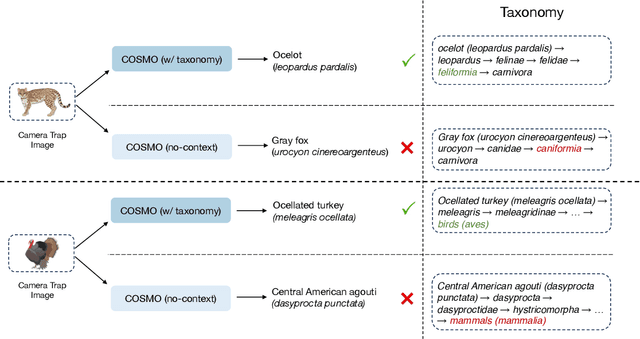
Camera traps are valuable tools in animal ecology for biodiversity monitoring and conservation. However, challenges like poor generalization to deployment at new unseen locations limit their practical application. Images are naturally associated with heterogeneous forms of context possibly in different modalities. In this work, we leverage the structured context associated with the camera trap images to improve out-of-distribution generalization for the task of species identification in camera traps. For example, a photo of a wild animal may be associated with information about where and when it was taken, as well as structured biology knowledge about the animal species. While typically overlooked by existing work, bringing back such context offers several potential benefits for better image understanding, such as addressing data scarcity and enhancing generalization. However, effectively integrating such heterogeneous context into the visual domain is a challenging problem. To address this, we propose a novel framework that reformulates species classification as link prediction in a multimodal knowledge graph (KG). This framework seamlessly integrates various forms of multimodal context for visual recognition. We apply this framework for out-of-distribution species classification on the iWildCam2020-WILDS and Snapshot Mountain Zebra datasets and achieve competitive performance with state-of-the-art approaches. Furthermore, our framework successfully incorporates biological taxonomy for improved generalization and enhances sample efficiency for recognizing under-represented species.
Holistic Transfer: Towards Non-Disruptive Fine-Tuning with Partial Target Data
Nov 02, 2023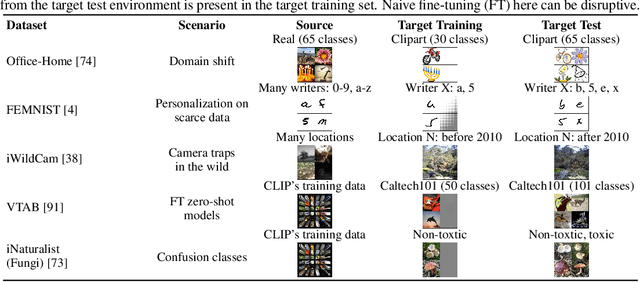
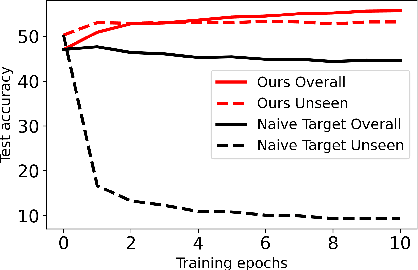
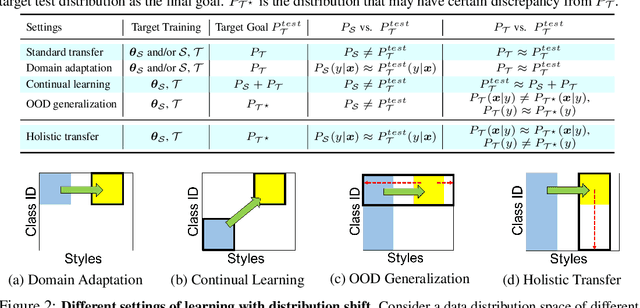
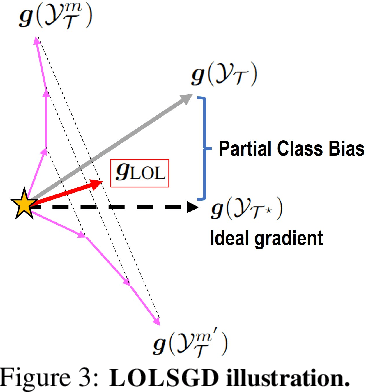
We propose a learning problem involving adapting a pre-trained source model to the target domain for classifying all classes that appeared in the source data, using target data that covers only a partial label space. This problem is practical, as it is unrealistic for the target end-users to collect data for all classes prior to adaptation. However, it has received limited attention in the literature. To shed light on this issue, we construct benchmark datasets and conduct extensive experiments to uncover the inherent challenges. We found a dilemma -- on the one hand, adapting to the new target domain is important to claim better performance; on the other hand, we observe that preserving the classification accuracy of classes missing in the target adaptation data is highly challenging, let alone improving them. To tackle this, we identify two key directions: 1) disentangling domain gradients from classification gradients, and 2) preserving class relationships. We present several effective solutions that maintain the accuracy of the missing classes and enhance the overall performance, establishing solid baselines for holistic transfer of pre-trained models with partial target data.
Learning Fractals by Gradient Descent
Mar 14, 2023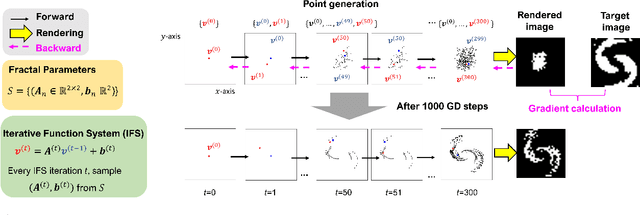
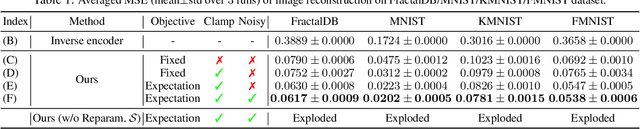
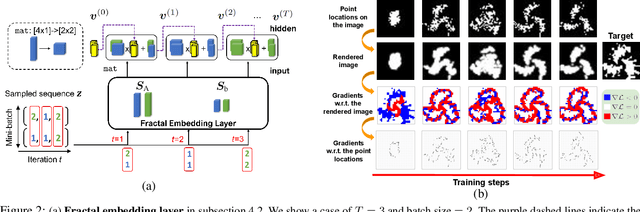

Fractals are geometric shapes that can display complex and self-similar patterns found in nature (e.g., clouds and plants). Recent works in visual recognition have leveraged this property to create random fractal images for model pre-training. In this paper, we study the inverse problem -- given a target image (not necessarily a fractal), we aim to generate a fractal image that looks like it. We propose a novel approach that learns the parameters underlying a fractal image via gradient descent. We show that our approach can find fractal parameters of high visual quality and be compatible with different loss functions, opening up several potentials, e.g., learning fractals for downstream tasks, scientific understanding, etc.
Visual Query Tuning: Towards Effective Usage of Intermediate Representations for Parameter and Memory Efficient Transfer Learning
Dec 06, 2022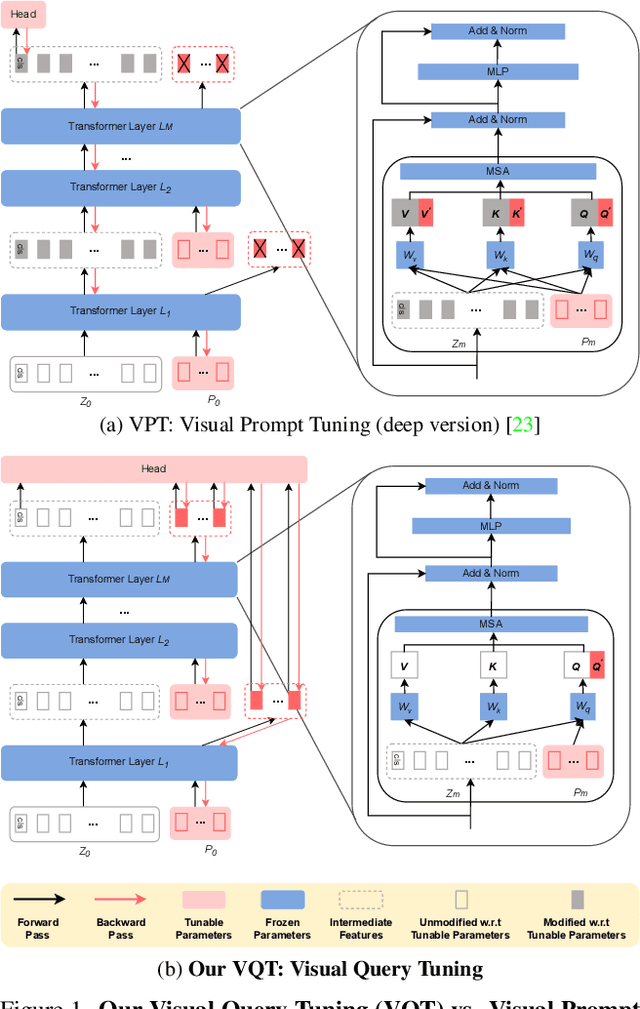
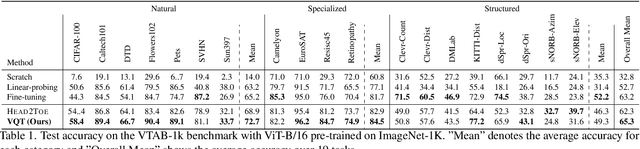

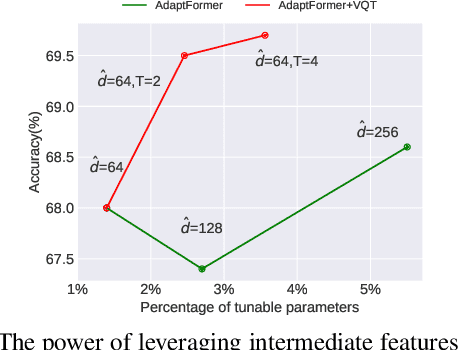
Intermediate features of a pre-trained model have been shown informative for making accurate predictions on downstream tasks, even if the model backbone is kept frozen. The key challenge is how to utilize these intermediate features given their gigantic amount. We propose visual query tuning (VQT), a simple yet effective approach to aggregate intermediate features of Vision Transformers. Through introducing a handful of learnable ``query'' tokens to each layer, VQT leverages the inner workings of Transformers to ``summarize'' rich intermediate features of each layer, which can then be used to train the prediction heads of downstream tasks. As VQT keeps the intermediate features intact and only learns to combine them, it enjoys memory efficiency in training, compared to many other parameter-efficient fine-tuning approaches that learn to adapt features and need back-propagation through the entire backbone. This also suggests the complementary role between VQT and those approaches in transfer learning. Empirically, VQT consistently surpasses the state-of-the-art approach that utilizes intermediate features for transfer learning and outperforms full fine-tuning in many cases. Compared to parameter-efficient approaches that adapt features, VQT achieves much higher accuracy under memory constraints. Most importantly, VQT is compatible with these approaches to attain even higher accuracy, making it a simple add-on to further boost transfer learning.
On Pre-Training for Federated Learning
Jun 23, 2022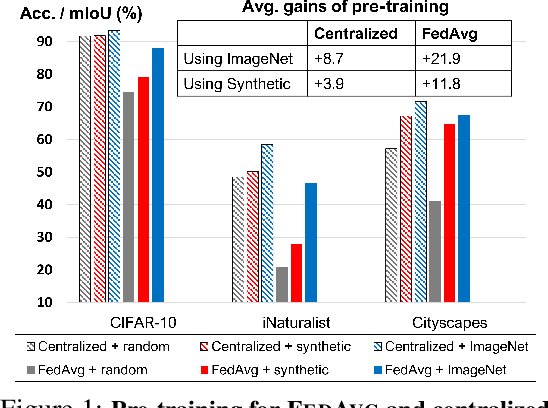
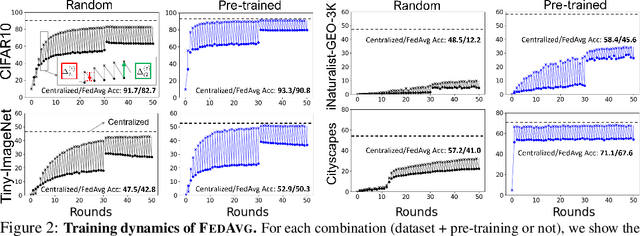
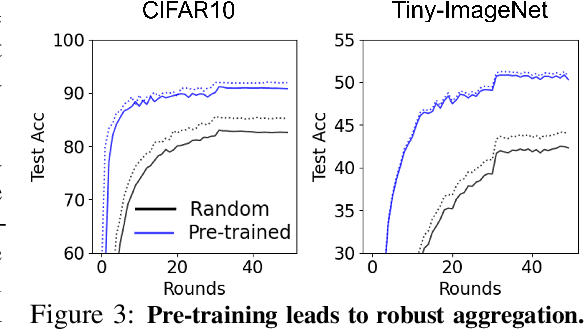
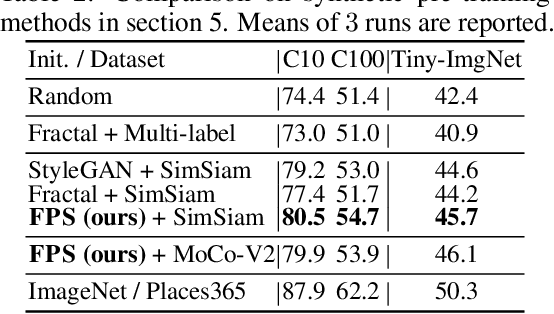
In most of the literature on federated learning (FL), neural networks are initialized with random weights. In this paper, we present an empirical study on the effect of pre-training on FL. Specifically, we aim to investigate if pre-training can alleviate the drastic accuracy drop when clients' decentralized data are non-IID. We focus on FedAvg, the fundamental and most widely used FL algorithm. We found that pre-training does largely close the gap between FedAvg and centralized learning under non-IID data, but this does not come from alleviating the well-known model drifting problem in FedAvg's local training. Instead, how pre-training helps FedAvg is by making FedAvg's global aggregation more stable. When pre-training using real data is not feasible for FL, we propose a novel approach to pre-train with synthetic data. On various image datasets (including one for segmentation), our approach with synthetic pre-training leads to a notable gain, essentially a critical step toward scaling up federated learning for real-world applications.
Compacting, Picking and Growing for Unforgetting Continual Learning
Oct 30, 2019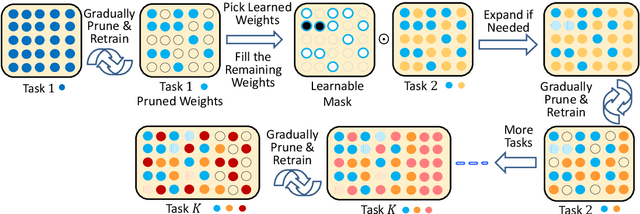

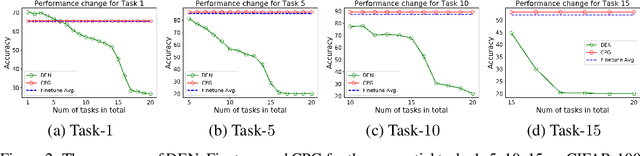
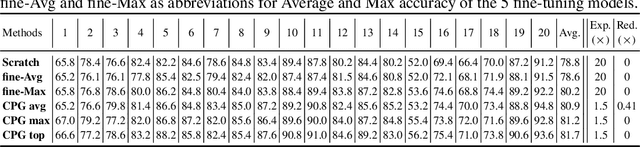
Continual lifelong learning is essential to many applications. In this paper, we propose a simple but effective approach to continual deep learning. Our approach leverages the principles of deep model compression, critical weights selection, and progressive networks expansion. By enforcing their integration in an iterative manner, we introduce an incremental learning method that is scalable to the number of sequential tasks in a continual learning process. Our approach is easy to implement and owns several favorable characteristics. First, it can avoid forgetting (i.e., learn new tasks while remembering all previous tasks). Second, it allows model expansion but can maintain the model compactness when handling sequential tasks. Besides, through our compaction and selection/expansion mechanism, we show that the knowledge accumulated through learning previous tasks is helpful to build a better model for the new tasks compared to training the models independently with tasks. Experimental results show that our approach can incrementally learn a deep model tackling multiple tasks without forgetting, while the model compactness is maintained with the performance more satisfiable than individual task training.