 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons Learned from a Unifying Empirical Study of Parameter-Efficient Transfer Learning (PETL) in Visual Recognition
Paper and Code
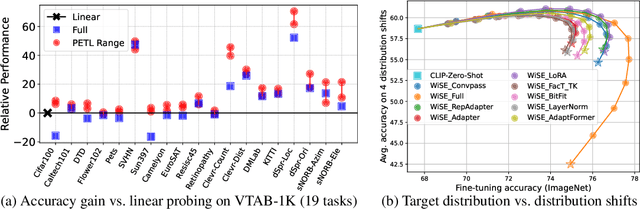
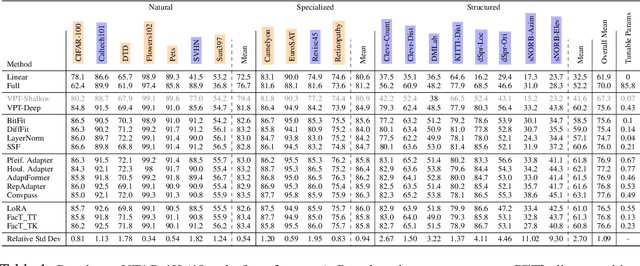


Parameter-efficient transfer learning (PETL) has attracted significant attention lately, due to the increasing size of pre-trained models and the need to fine-tune (FT) them for superior downstream performance. This community-wide enthusiasm has sparked a plethora of new methods. Nevertheless, a systematic study to understand their performance and suitable application scenarios is lacking, leaving questions like when to apply PETL and which method to use largely unanswered. In this paper, we conduct a unifying empirical study of representative PETL methods in the context of Vision Transformers. We systematically tune their hyper-parameters to fairly compare their accuracy on downstream tasks. Our study not only offers a valuable user guide but also unveils several new insights. First, if tuned carefully, different PETL methods can obtain quite similar accuracy in the low-shot benchmark VTAB-1K. This includes simple methods like FT the bias terms that were reported inferior. Second, though with similar accuracy, we find that PETL methods make different mistakes and high-confidence predictions, likely due to their different inductive biases. Such an inconsistency (or complementariness) opens up the opportunity for ensemble methods, and we make preliminary attempts at this. Third, going beyond the commonly used low-shot tasks, we find that PETL is also useful in many-shot regimes -- it achieves comparable and sometimes better accuracy than full FT, using much fewer learnable parameters. Last but not least, we investigate PETL's ability to preserve a pre-trained model's robustness to distribution shifts (e.g., a CLIP backbone). Perhaps not surprisingly, PETL methods outperform full FT alone. However, with weight-space ensembles, the fully FT model can achieve a better balance between downstream and out-of-distribution performance, suggesting a future research direction for PETL.