 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Shortcuts to Reasoning: Robust Post-Training of Theory of Mind with Reinforcement Learning
Jun 08, 2026Theory of Mind (ToM) is a must-acquire skill for modern foundation model systems to operate effectively and safely in the real world. Recent works have explored honing ToM via post-training; however, we show that such progress is confounded by a pervasive "shortcut" issue: tasks can reach up to 99% accuracy by simply exploiting spurious causal correlations, leading to a false sense of ToM. Motivated by this, we first develop a framework to systematically examine ToM datasets for shortcuts and provide guidance for future development. We find that questions reducible to pure state tracking, such as "belief," are especially shortcut-prone compared to mind questions, such as "intention," where reasoning beyond tracking is required. Using four shortcut-free datasets across three ToM contexts, we then comprehensively study whether Reinforcement Fine-Tuning with verifiable rewards and explicit reasoning chains, called Thinking-RFT, elevates ToM beyond Supervised Fine-Tuning, or SFT. Our key findings are as follows. First, Thinking-RFT effectively improves ToM in all scenarios, with a 6% improvement over SFT, particularly in complex higher-order reasoning, with a 10% improvement over SFT, and multimodal cases, with a 7% improvement over SFT. It also generalizes notably better to unseen domains and higher-order queries while being more robust to counterfactuals. Second, ToM benefits specifically from the joint effect of reasoning and RL: Thinking-RFT outperforms Non-Thinking-RFT by 7% on average. Third, RFT works by learning to ground its reasoning on anchor cues, such as keywords and state changes, that correspond to causal factors. We believe our study is useful for developing effective and robust ToM post-training datasets and advancing critical ToM capabilities.
ClawForge: Generating Executable Interactive Benchmarks for Command-Line Agents
May 13, 2026Interactive agent benchmarks face a tension between scalable construction and realistic workflow evaluation. Hand-authored tasks are expensive to extend and revise, while static prompt evaluation misses failures that only appear when agents operate over persistent state. Existing interactive benchmarks have advanced agent evaluation significantly, but most initialize tasks from clean state and do not systematically test how agents handle pre-existing partial, stale, or conflicting artifacts. We present \textbf{ClawForge}, a generator-backed benchmark framework for executable command-line workflows under state conflict. The framework compiles scenario templates, grounded slots, initialized state, reference trajectories, and validators into reproducible task specifications, and evaluates agents step by step over persistent workflow surfaces using normalized end state and observable side effects rather than exact trajectory matching. We instantiate this framework as the ClawForge-Bench (17 scenarios, 6 ability categories). Results across seven frontier models show that the best model reaches only 45.3% strict accuracy, wrong-state replacement remains below 17\% for all models, and the widest model separation (17% to 90%) is driven by whether agents inspect existing state before acting. Partial-credit and step-efficiency analyses further reveal that many failures are near-miss closures rather than early breakdowns, and that models exhibit qualitatively different failure styles under state conflict.
VRIQ: Benchmarking and Analyzing Visual-Reasoning IQ of VLMs
Feb 05, 2026Recent progress in Vision Language Models (VLMs) has raised the question of whether they can reliably perform nonverbal reasoning. To this end, we introduce VRIQ (Visual Reasoning IQ), a novel benchmark designed to assess and analyze the visual reasoning ability of VLMs. We evaluate models on two sets of tasks: abstract puzzle-style and natural-image reasoning tasks. We find that on abstract puzzles, performance remains near random with an average accuracy of around 28%, while natural tasks yield better but still weak results with 45% accuracy. We also find that tool-augmented reasoning demonstrates only modest improvements. To uncover the source of this weakness, we introduce diagnostic probes targeting perception and reasoning. Our analysis demonstrates that around 56% of failures arise from perception alone, 43% from both perception and reasoning, and only a mere 1% from reasoning alone. This motivates us to design fine-grained diagnostic probe questions targeting specific perception categories (e.g., shape, count, position, 3D/depth), revealing that certain categories cause more failures than others. Our benchmark and analysis establish that current VLMs, even with visual reasoning tools, remain unreliable abstract reasoners, mostly due to perception limitations, and offer a principled basis for improving visual reasoning in multimodal systems.
EchoVLM: Measurement-Grounded Multimodal Learning for Echocardiography
Dec 13, 2025Echocardiography is the most widely used imaging modality in cardiology, yet its interpretation remains labor-intensive and inherently multimodal, requiring view recognition, quantitative measurements, qualitative assessments, and guideline-based reasoning. While recent vision-language models (VLMs) have achieved broad success in natural images and certain medical domains, their potential in echocardiography has been limited by the lack of large-scale, clinically grounded image-text datasets and the absence of measurement-based reasoning central to echo interpretation. We introduce EchoGround-MIMIC, the first measurement-grounded multimodal echocardiography dataset, comprising 19,065 image-text pairs from 1,572 patients with standardized views, structured measurements, measurement-grounded captions, and guideline-derived disease labels. Building on this resource, we propose EchoVLM, a vision-language model that incorporates two novel pretraining objectives: (i) a view-informed contrastive loss that encodes the view-dependent structure of echocardiographic imaging, and (ii) a negation-aware contrastive loss that distinguishes clinically critical negative from positive findings. Across five types of clinical applications with 36 tasks spanning multimodal disease classification, image-text retrieval, view classification, chamber segmentation, and landmark detection, EchoVLM achieves state-of-the-art performance (86.5% AUC in zero-shot disease classification and 95.1% accuracy in view classification). We demonstrate that clinically grounded multimodal pretraining yields transferable visual representations and establish EchoVLM as a foundation model for end-to-end echocardiography interpretation. We will release EchoGround-MIMIC and the data curation code, enabling reproducibility and further research in multimodal echocardiography interpretation.
MedVista3D: Vision-Language Modeling for Reducing Diagnostic Errors in 3D CT Disease Detection, Understanding and Reporting
Sep 04, 2025Radiologic diagnostic errors-under-reading errors, inattentional blindness, and communication failures-remain prevalent in clinical practice. These issues often stem from missed localized abnormalities, limited global context, and variability in report language. These challenges are amplified in 3D imaging, where clinicians must examine hundreds of slices per scan. Addressing them requires systems with precise localized detection, global volume-level reasoning, and semantically consistent natural language reporting. However, existing 3D vision-language models are unable to meet all three needs jointly, lacking local-global understanding for spatial reasoning and struggling with the variability and noise of uncurated radiology reports. We present MedVista3D, a multi-scale semantic-enriched vision-language pretraining framework for 3D CT analysis. To enable joint disease detection and holistic interpretation, MedVista3D performs local and global image-text alignment for fine-grained representation learning within full-volume context. To address report variability, we apply language model rewrites and introduce a Radiology Semantic Matching Bank for semantics-aware alignment. MedVista3D achieves state-of-the-art performance on zero-shot disease classification, report retrieval, and medical visual question answering, while transferring well to organ segmentation and prognosis prediction. Code and datasets will be released.
Patient-Specific Autoregressive Models for Organ Motion Prediction in Radiotherapy
May 17, 2025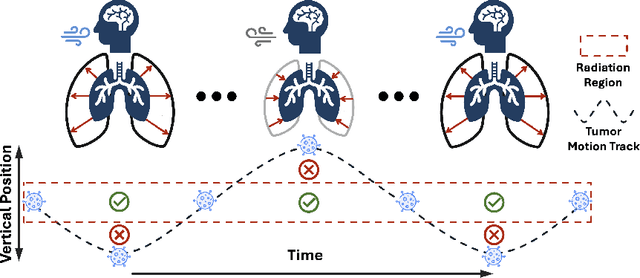
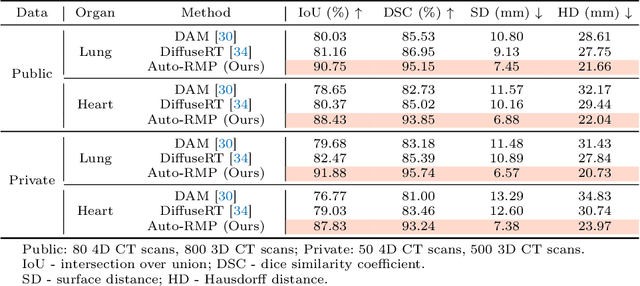
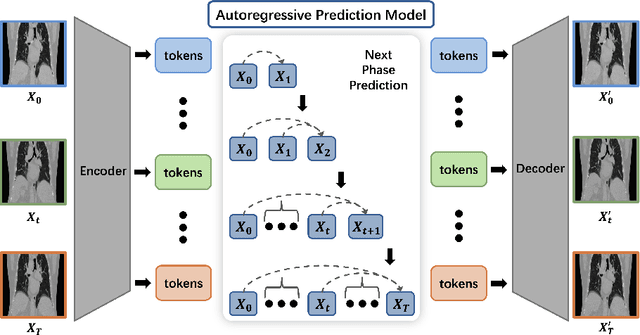
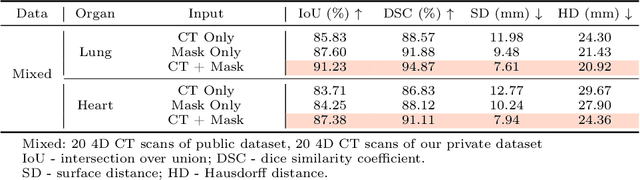
Radiotherapy often involves a prolonged treatment period. During this time, patients may experience organ motion due to breathing and other physiological factors. Predicting and modeling this motion before treatment is crucial for ensuring precise radiation delivery. However, existing pre-treatment organ motion prediction methods primarily rely on deformation analysis using principal component analysis (PCA), which is highly dependent on registration quality and struggles to capture periodic temporal dynamics for motion modeling.In this paper, we observe that organ motion prediction closely resembles an autoregressive process, a technique widely used in natural language processing (NLP). Autoregressive models predict the next token based on previous inputs, naturally aligning with our objective of predicting future organ motion phases. Building on this insight, we reformulate organ motion prediction as an autoregressive process to better capture patient-specific motion patterns. Specifically, we acquire 4D CT scans for each patient before treatment, with each sequence comprising multiple 3D CT phases. These phases are fed into the autoregressive model to predict future phases based on prior phase motion patterns. We evaluate our method on a real-world test set of 4D CT scans from 50 patients who underwent radiotherapy at our institution and a public dataset containing 4D CT scans from 20 patients (some with multiple scans), totaling over 1,300 3D CT phases. The performance in predicting the motion of the lung and heart surpasses existing benchmarks, demonstrating its effectiveness in capturing motion dynamics from CT images. These results highlight the potential of our method to improve pre-treatment planning in radiotherapy, enabling more precise and adaptive radiation delivery.
CLS-RL: Image Classification with Rule-Based Reinforcement Learning
Mar 20, 2025



Classification is a core task in machine learning. Recent research has shown that although Multimodal Large Language Models (MLLMs) are initially poor at image classification, fine-tuning them with an adequate amount of data can significantly enhance their performance, making them comparable to SOTA classification models. However, acquiring large-scale labeled data is expensive. In this paper, we explore few-shot MLLM classification fine-tuning. We found that SFT can cause severe overfitting issues and may even degrade performance over the zero-shot approach. To address this challenge, inspired by the recent successes in rule-based reinforcement learning, we propose CLS-RL, which uses verifiable signals as reward to fine-tune MLLMs. We discovered that CLS-RL outperforms SFT in most datasets and has a much higher average accuracy on both base-to-new and few-shot learning setting. Moreover, we observed a free-lunch phenomenon for CLS-RL; when models are fine-tuned on a particular dataset, their performance on other distinct datasets may also improve over zero-shot models, even if those datasets differ in distribution and class names. This suggests that RL-based methods effectively teach models the fundamentals of classification. Lastly, inspired by recent works in inference time thinking, we re-examine the `thinking process' during fine-tuning, a critical aspect of RL-based methods, in the context of visual classification. We question whether such tasks require extensive thinking process during fine-tuning, proposing that this may actually detract from performance. Based on this premise, we introduce the No-Thinking-CLS-RL method, which minimizes thinking processes during training by setting an equality accuracy reward. Our findings indicate that, with much less fine-tuning time, No-Thinking-CLS-RL method achieves superior in-domain performance and generalization capabilities than CLS-RL.
Med-R1: Reinforcement Learning for Generalizable Medical Reasoning in Vision-Language Models
Mar 19, 2025



Vision-language models (VLMs) have advanced reasoning in natural scenes, but their role in medical imaging remains underexplored. Medical reasoning tasks demand robust image analysis and well-justified answers, posing challenges due to the complexity of medical images. Transparency and trustworthiness are essential for clinical adoption and regulatory compliance. We introduce Med-R1, a framework exploring reinforcement learning (RL) to enhance VLMs' generalizability and trustworthiness in medical reasoning. Leveraging the DeepSeek strategy, we employ Group Relative Policy Optimization (GRPO) to guide reasoning paths via reward signals. Unlike supervised fine-tuning (SFT), which often overfits and lacks generalization, RL fosters robust and diverse reasoning. Med-R1 is evaluated across eight medical imaging modalities: CT, MRI, Ultrasound, Dermoscopy, Fundus Photography, Optical Coherence Tomography (OCT), Microscopy, and X-ray Imaging. Compared to its base model, Qwen2-VL-2B, Med-R1 achieves a 29.94% accuracy improvement and outperforms Qwen2-VL-72B, which has 36 times more parameters. Testing across five question types-modality recognition, anatomy identification, disease diagnosis, lesion grading, and biological attribute analysis Med-R1 demonstrates superior generalization, exceeding Qwen2-VL-2B by 32.06% and surpassing Qwen2-VL-72B in question-type generalization. These findings show that RL improves medical reasoning and enables parameter-efficient models to outperform significantly larger ones. With interpretable reasoning outputs, Med-R1 represents a promising step toward generalizable, trustworthy, and clinically viable medical VLMs.
EEE-Bench: A Comprehensive Multimodal Electrical And Electronics Engineering Benchmark
Nov 03, 2024Recent studies on large language models (LLMs) and large multimodal models (LMMs) have demonstrated promising skills in various domains including science and mathematics. However, their capability in more challenging and real-world related scenarios like engineering has not been systematically studied. To bridge this gap, we propose EEE-Bench, a multimodal benchmark aimed at assessing LMMs' capabilities in solving practical engineering tasks, using electrical and electronics engineering (EEE) as the testbed. Our benchmark consists of 2860 carefully curated problems spanning 10 essential subdomains such as analog circuits, control systems, etc. Compared to benchmarks in other domains, engineering problems are intrinsically 1) more visually complex and versatile and 2) less deterministic in solutions. Successful solutions to these problems often demand more-than-usual rigorous integration of visual and textual information as models need to understand intricate images like abstract circuits and system diagrams while taking professional instructions, making them excellent candidates for LMM evaluations. Alongside EEE-Bench, we provide extensive quantitative evaluations and fine-grained analysis of 17 widely-used open and closed-sourced LLMs and LMMs. Our results demonstrate notable deficiencies of current foundation models in EEE, with an average performance ranging from 19.48% to 46.78%. Finally, we reveal and explore a critical shortcoming in LMMs which we term laziness: the tendency to take shortcuts by relying on the text while overlooking the visual context when reasoning for technical image problems. In summary, we believe EEE-Bench not only reveals some noteworthy limitations of LMMs but also provides a valuable resource for advancing research on their application in practical engineering tasks, driving future improvements in their capability to handle complex, real-world scenarios.
Vision-Language Model Fine-Tuning via Simple Parameter-Efficient Modification
Sep 25, 2024



Recent advances in fine-tuning Vision-Language Models (VLMs) have witnessed the success of prompt tuning and adapter tuning, while the classic model fine-tuning on inherent parameters seems to be overlooked. It is believed that fine-tuning the parameters of VLMs with few-shot samples corrupts the pre-trained knowledge since fine-tuning the CLIP model even degrades performance. In this paper, we revisit this viewpoint, and propose a new perspective: fine-tuning the specific parameters instead of all will uncover the power of classic model fine-tuning on VLMs. Through our meticulous study, we propose ClipFit, a simple yet effective method to fine-tune CLIP without introducing any overhead of extra parameters. We demonstrate that by only fine-tuning the specific bias terms and normalization layers, ClipFit can improve the performance of zero-shot CLIP by 7.27\% average harmonic mean accuracy. Lastly, to understand how fine-tuning in CLIPFit affects the pre-trained models, we conducted extensive experimental analyses w.r.t. changes in internal parameters and representations. We found that low-level text bias layers and the first layer normalization layer change much more than other layers. The code is available at \url{https://github.com/minglllli/CLIPFit}.