 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHand-in-the-Loop: Improving Dexterous VLA via Seamless Interventional Correction
May 14, 2026Vision-Language-Action (VLA) models are prone to compounding errors in dexterous manipulation, where high-dimensional action spaces and contact-rich dynamics amplify small policy deviations over long horizons. While Interactive Imitation Learning (IIL) can refine policies through human takeover data, applying it to high-degree-of-freedom (DoF) robotic hands remains challenging due to a command mismatch between human teleoperation and policy execution at the takeover moment, which causes abrupt robot-hand configuration changes, or "gesture jumps". We present Hand-in-the-Loop (HandITL), a seamless human-in-the-loop intervention method that blends human corrective intent with autonomous policy execution to avoid gesture jumps during bimanual dexterous manipulation. Compared with direct teleoperation takeover, HandITL reduces takeover jitter by 99.8% and preserves robust post-takeover manipulation, reducing grasp failures by 87.5% and mean completion time by 19.1%. We validate HandITL on tasks requiring bimanual coordination, tool use, and fine-grained long-horizon manipulation. When used to collect intervention data for policy refinement, HandITL yields policies that outperform those trained with standard teleoperation data by 19% on average across three long-horizon dexterous tasks.
SiMHand: Mining Similar Hands for Large-Scale 3D Hand Pose Pre-training
Feb 21, 2025



We present a framework for pre-training of 3D hand pose estimation from in-the-wild hand images sharing with similar hand characteristics, dubbed SimHand. Pre-training with large-scale images achieves promising results in various tasks, but prior methods for 3D hand pose pre-training have not fully utilized the potential of diverse hand images accessible from in-the-wild videos. To facilitate scalable pre-training, we first prepare an extensive pool of hand images from in-the-wild videos and design our pre-training method with contrastive learning. Specifically, we collect over 2.0M hand images from recent human-centric videos, such as 100DOH and Ego4D. To extract discriminative information from these images, we focus on the similarity of hands: pairs of non-identical samples with similar hand poses. We then propose a novel contrastive learning method that embeds similar hand pairs closer in the feature space. Our method not only learns from similar samples but also adaptively weights the contrastive learning loss based on inter-sample distance, leading to additional performance gains. Our experiments demonstrate that our method outperforms conventional contrastive learning approaches that produce positive pairs sorely from a single image with data augmentation. We achieve significant improvements over the state-of-the-art method (PeCLR) in various datasets, with gains of 15% on FreiHand, 10% on DexYCB, and 4% on AssemblyHands. Our code is available at https://github.com/ut-vision/SiMHand.
Translating Mental Imaginations into Characters with Codebooks and Dynamics-Enhanced Decoding
Sep 25, 2024



Advancements in non-invasive electroencephalogram (EEG)-based Brain-Computer Interface (BCI) technology have enabled communication through brain activity, offering significant potential for individuals with motor impairments. Existing methods for decoding characters or words from EEG recordings either rely on continuous external stimulation for high decoding accuracy or depend on direct intention imagination, which suffers from reduced discrimination ability. To overcome these limitations, we introduce a novel EEG paradigm based on mental tasks that achieves high discrimination accuracy without external stimulation. Specifically, we propose a codebook in which each letter or number is associated with a unique code that integrates three mental tasks, interleaved with eye-open and eye-closed states. This approach allows individuals to internally reference characters without external stimuli while maintaining reasonable accuracy. For enhanced decoding performance, we apply a Temporal-Spatial-Latent-Dynamics (TSLD) network to capture latent dynamics of spatiotemporal EEG signals. Experimental results demonstrate the effectiveness of our proposed EEG paradigm which achieves five times higher accuracy over direct imagination. Additionally, the TSLD network improves baseline methods by approximately 8.5%. Further more, we observe consistent performance improvement throughout the data collection process, suggesting that the proposed paradigm has potential for further optimization with continued use.
Vision-Language Model Fine-Tuning via Simple Parameter-Efficient Modification
Sep 25, 2024



Recent advances in fine-tuning Vision-Language Models (VLMs) have witnessed the success of prompt tuning and adapter tuning, while the classic model fine-tuning on inherent parameters seems to be overlooked. It is believed that fine-tuning the parameters of VLMs with few-shot samples corrupts the pre-trained knowledge since fine-tuning the CLIP model even degrades performance. In this paper, we revisit this viewpoint, and propose a new perspective: fine-tuning the specific parameters instead of all will uncover the power of classic model fine-tuning on VLMs. Through our meticulous study, we propose ClipFit, a simple yet effective method to fine-tune CLIP without introducing any overhead of extra parameters. We demonstrate that by only fine-tuning the specific bias terms and normalization layers, ClipFit can improve the performance of zero-shot CLIP by 7.27\% average harmonic mean accuracy. Lastly, to understand how fine-tuning in CLIPFit affects the pre-trained models, we conducted extensive experimental analyses w.r.t. changes in internal parameters and representations. We found that low-level text bias layers and the first layer normalization layer change much more than other layers. The code is available at \url{https://github.com/minglllli/CLIPFit}.
Pre-Training for 3D Hand Pose Estimation with Contrastive Learning on Large-Scale Hand Images in the Wild
Sep 15, 2024



We present a contrastive learning framework based on in-the-wild hand images tailored for pre-training 3D hand pose estimators, dubbed HandCLR. Pre-training on large-scale images achieves promising results in various tasks, but prior 3D hand pose pre-training methods have not fully utilized the potential of diverse hand images accessible from in-the-wild videos. To facilitate scalable pre-training, we first prepare an extensive pool of hand images from in-the-wild videos and design our method with contrastive learning. Specifically, we collected over 2.0M hand images from recent human-centric videos, such as 100DOH and Ego4D. To extract discriminative information from these images, we focus on the similarity of hands; pairs of similar hand poses originating from different samples, and propose a novel contrastive learning method that embeds similar hand pairs closer in the latent space. Our experiments demonstrate that our method outperforms conventional contrastive learning approaches that produce positive pairs sorely from a single image with data augmentation. We achieve significant improvements over the state-of-the-art method in various datasets, with gains of 15% on FreiHand, 10% on DexYCB, and 4% on AssemblyHands.
Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects
Mar 25, 2024
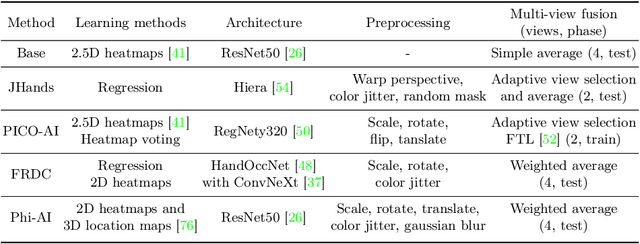
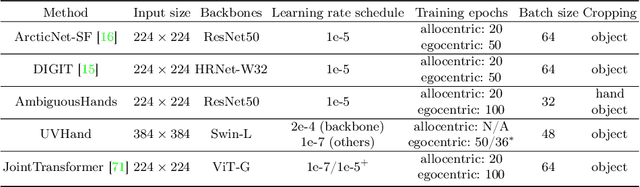
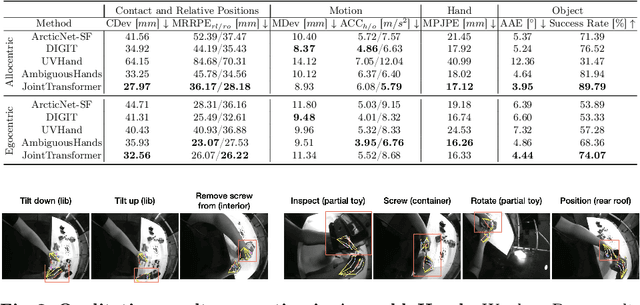
We interact with the world with our hands and see it through our own (egocentric) perspective. A holistic 3D understanding of such interactions from egocentric views is important for tasks in robotics, AR/VR, action recognition and motion generation. Accurately reconstructing such interactions in 3D is challenging due to heavy occlusion, viewpoint bias, camera distortion, and motion blur from the head movement. To this end, we designed the HANDS23 challenge based on the AssemblyHands and ARCTIC datasets with carefully designed training and testing splits. Based on the results of the top submitted methods and more recent baselines on the leaderboards, we perform a thorough analysis on 3D hand(-object) reconstruction tasks. Our analysis demonstrates the effectiveness of addressing distortion specific to egocentric cameras, adopting high-capacity transformers to learn complex hand-object interactions, and fusing predictions from different views. Our study further reveals challenging scenarios intractable with state-of-the-art methods, such as fast hand motion, object reconstruction from narrow egocentric views, and close contact between two hands and objects. Our efforts will enrich the community's knowledge foundation and facilitate future hand studies on egocentric hand-object interactions.
Knowledge Condensation Distillation
Jul 12, 2022
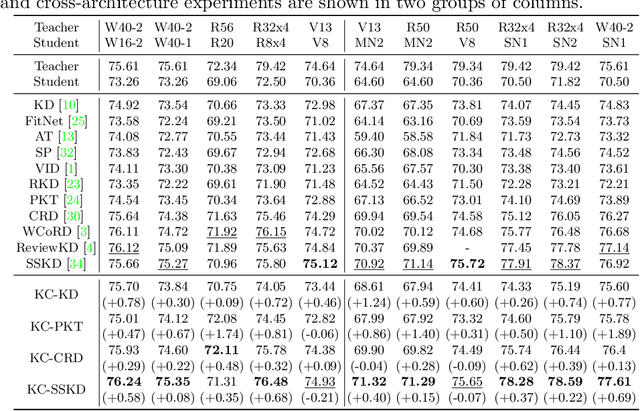
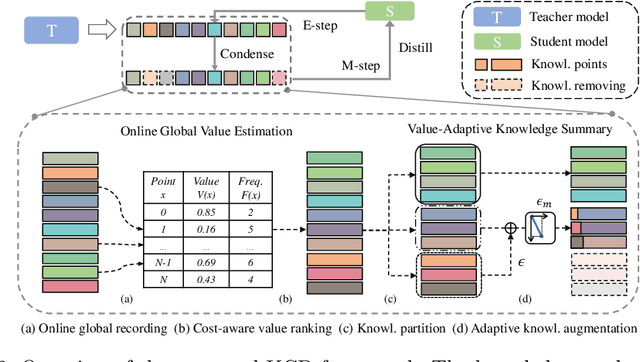

Knowledge Distillation (KD) transfers the knowledge from a high-capacity teacher network to strengthen a smaller student. Existing methods focus on excavating the knowledge hints and transferring the whole knowledge to the student. However, the knowledge redundancy arises since the knowledge shows different values to the student at different learning stages. In this paper, we propose Knowledge Condensation Distillation (KCD). Specifically, the knowledge value on each sample is dynamically estimated, based on which an Expectation-Maximization (EM) framework is forged to iteratively condense a compact knowledge set from the teacher to guide the student learning. Our approach is easy to build on top of the off-the-shelf KD methods, with no extra training parameters and negligible computation overhead. Thus, it presents one new perspective for KD, in which the student that actively identifies teacher's knowledge in line with its aptitude can learn to learn more effectively and efficiently. Experiments on standard benchmarks manifest that the proposed KCD can well boost the performance of student model with even higher distillation efficiency. Code is available at https://github.com/dzy3/KCD.
EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2022: Team HNU-FPV Technical Report
Jul 07, 2022
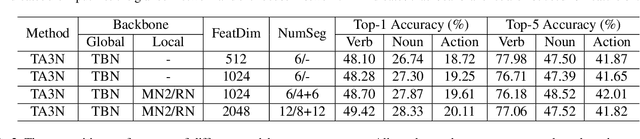
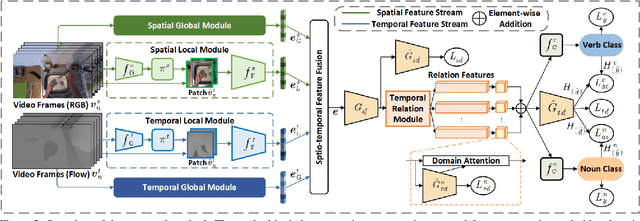

In this report, we present the technical details of our submission to the 2022 EPIC-Kitchens Unsupervised Domain Adaptation (UDA) Challenge. Existing UDA methods align the global features extracted from the whole video clips across the source and target domains but suffer from the spatial redundancy of feature matching in video recognition. Motivated by the observation that in most cases a small image region in each video frame can be informative enough for the action recognition task, we propose to exploit informative image regions to perform efficient domain alignment. Specifically, we first use lightweight CNNs to extract the global information of the input two-stream video frames and select the informative image patches by a differentiable interpolation-based selection strategy. Then the global information from videos frames and local information from image patches are processed by an existing video adaptation method, i.e., TA3N, in order to perform feature alignment for the source domain and the target domain. Our method (without model ensemble) ranks 4th among this year's teams on the test set of EPIC-KITCHENS-100.