 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLANET v2.0: A comprehensive Protein-Ligand Affinity Prediction Model Based on Mixture Density Network
Jan 12, 2026Drug discovery represents a time-consuming and financially intensive process, and virtual screening can accelerate it. Scoring functions, as one of the tools guiding virtual screening, have their precision closely tied to screening efficiency. In our previous study, we developed a graph neural network model called PLANET (Protein-Ligand Affinity prediction NETwork), but it suffers from the defect in representing protein-ligand contact maps. Incorrect binding modes inevitably lead to poor affinity predictions, so accurate prediction of the protein-ligand contact map is desired to improve PLANET. In this study, we have proposed PLANET v2.0 as an upgraded version. The model is trained via multi-objective training strategy and incorporates the Mixture Density Network to predict binding modes. Except for the probability density distributions of non-covalent interactions, we innovatively employ another Gaussian mixture model to describe the relationship between distance and energy of each interaction pair and predict protein-ligand affinity like calculating the mathematical expectation. As on the CASF-2016 benchmark, PLANET v2.0 demonstrates excellent scoring power, ranking power, and docking power. The screening power of PLANET v2.0 gets notably improved compared to PLANET and Glide SP and it demonstrates robust validation on a commercial ultra-large-scale dataset. Given its efficiency and accuracy, PLANET v2.0 can hopefully become one of the practical tools for virtual screening workflows. PLANET v2.0 is freely available at https://www.pdbbind-plus.org.cn/planetv2.
SAVVY: Spatial Awareness via Audio-Visual LLMs through Seeing and Hearing
Jun 04, 20253D spatial reasoning in dynamic, audio-visual environments is a cornerstone of human cognition yet remains largely unexplored by existing Audio-Visual Large Language Models (AV-LLMs) and benchmarks, which predominantly focus on static or 2D scenes. We introduce SAVVY-Bench, the first benchmark for 3D spatial reasoning in dynamic scenes with synchronized spatial audio. SAVVY-Bench is comprised of thousands of relationships involving static and moving objects, and requires fine-grained temporal grounding, consistent 3D localization, and multi-modal annotation. To tackle this challenge, we propose SAVVY, a novel training-free reasoning pipeline that consists of two stages: (i) Egocentric Spatial Tracks Estimation, which leverages AV-LLMs as well as other audio-visual methods to track the trajectories of key objects related to the query using both visual and spatial audio cues, and (ii) Dynamic Global Map Construction, which aggregates multi-modal queried object trajectories and converts them into a unified global dynamic map. Using the constructed map, a final QA answer is obtained through a coordinate transformation that aligns the global map with the queried viewpoint. Empirical evaluation demonstrates that SAVVY substantially enhances performance of state-of-the-art AV-LLMs, setting a new standard and stage for approaching dynamic 3D spatial reasoning in AV-LLMs.
Brain-to-Text Benchmark '24: Lessons Learned
Dec 23, 2024

Speech brain-computer interfaces aim to decipher what a person is trying to say from neural activity alone, restoring communication to people with paralysis who have lost the ability to speak intelligibly. The Brain-to-Text Benchmark '24 and associated competition was created to foster the advancement of decoding algorithms that convert neural activity to text. Here, we summarize the lessons learned from the competition ending on June 1, 2024 (the top 4 entrants also presented their experiences in a recorded webinar). The largest improvements in accuracy were achieved using an ensembling approach, where the output of multiple independent decoders was merged using a fine-tuned large language model (an approach used by all 3 top entrants). Performance gains were also found by improving how the baseline recurrent neural network (RNN) model was trained, including by optimizing learning rate scheduling and by using a diphone training objective. Improving upon the model architecture itself proved more difficult, however, with attempts to use deep state space models or transformers not yet appearing to offer a benefit over the RNN baseline. The benchmark will remain open indefinitely to support further work towards increasing the accuracy of brain-to-text algorithms.
Brain-to-Text Decoding with Context-Aware Neural Representations and Large Language Models
Nov 16, 2024



Decoding attempted speech from neural activity offers a promising avenue for restoring communication abilities in individuals with speech impairments. Previous studies have focused on mapping neural activity to text using phonemes as the intermediate target. While successful, decoding neural activity directly to phonemes ignores the context dependent nature of the neural activity-to-phoneme mapping in the brain, leading to suboptimal decoding performance. In this work, we propose the use of diphone - an acoustic representation that captures the transitions between two phonemes - as the context-aware modeling target. We integrate diphones into existing phoneme decoding frameworks through a novel divide-and-conquer strategy in which we model the phoneme distribution by marginalizing over the diphone distribution. Our approach effectively leverages the enhanced context-aware representation of diphones while preserving the manageable class size of phonemes, a key factor in simplifying the subsequent phoneme-to-text conversion task. We demonstrate the effectiveness of our approach on the Brain-to-Text 2024 benchmark, where it achieves state-of-the-art Phoneme Error Rate (PER) of 15.34% compared to 16.62% PER of monophone-based decoding. When coupled with finetuned Large Language Models (LLMs), our method yields a Word Error Rate (WER) of 5.77%, significantly outperforming the 8.93% WER of the leading method in the benchmark.
Translating Mental Imaginations into Characters with Codebooks and Dynamics-Enhanced Decoding
Sep 25, 2024



Advancements in non-invasive electroencephalogram (EEG)-based Brain-Computer Interface (BCI) technology have enabled communication through brain activity, offering significant potential for individuals with motor impairments. Existing methods for decoding characters or words from EEG recordings either rely on continuous external stimulation for high decoding accuracy or depend on direct intention imagination, which suffers from reduced discrimination ability. To overcome these limitations, we introduce a novel EEG paradigm based on mental tasks that achieves high discrimination accuracy without external stimulation. Specifically, we propose a codebook in which each letter or number is associated with a unique code that integrates three mental tasks, interleaved with eye-open and eye-closed states. This approach allows individuals to internally reference characters without external stimuli while maintaining reasonable accuracy. For enhanced decoding performance, we apply a Temporal-Spatial-Latent-Dynamics (TSLD) network to capture latent dynamics of spatiotemporal EEG signals. Experimental results demonstrate the effectiveness of our proposed EEG paradigm which achieves five times higher accuracy over direct imagination. Additionally, the TSLD network improves baseline methods by approximately 8.5%. Further more, we observe consistent performance improvement throughout the data collection process, suggesting that the proposed paradigm has potential for further optimization with continued use.
ReLExS: Reinforcement Learning Explanations for Stackelberg No-Regret Learners
Aug 26, 2024With the constraint of a no regret follower, will the players in a two-player Stackelberg game still reach Stackelberg equilibrium? We first show when the follower strategy is either reward-average or transform-reward-average, the two players can always get the Stackelberg Equilibrium. Then, we extend that the players can achieve the Stackelberg equilibrium in the two-player game under the no regret constraint. Also, we show a strict upper bound of the follower's utility difference between with and without no regret constraint. Moreover, in constant-sum two-player Stackelberg games with non-regret action sequences, we ensure the total optimal utility of the game remains also bounded.
GLIMMER: Incorporating Graph and Lexical Features in Unsupervised Multi-Document Summarization
Aug 19, 2024



Pre-trained language models are increasingly being used in multi-document summarization tasks. However, these models need large-scale corpora for pre-training and are domain-dependent. Other non-neural unsupervised summarization approaches mostly rely on key sentence extraction, which can lead to information loss. To address these challenges, we propose a lightweight yet effective unsupervised approach called GLIMMER: a Graph and LexIcal features based unsupervised Multi-docuMEnt summaRization approach. It first constructs a sentence graph from the source documents, then automatically identifies semantic clusters by mining low-level features from raw texts, thereby improving intra-cluster correlation and the fluency of generated sentences. Finally, it summarizes clusters into natural sentences. Experiments conducted on Multi-News, Multi-XScience and DUC-2004 demonstrate that our approach outperforms existing unsupervised approaches. Furthermore, it surpasses state-of-the-art pre-trained multi-document summarization models (e.g. PEGASUS and PRIMERA) under zero-shot settings in terms of ROUGE scores. Additionally, human evaluations indicate that summaries generated by GLIMMER achieve high readability and informativeness scores. Our code is available at https://github.com/Oswald1997/GLIMMER.
Feynman-Kac Operator Expectation Estimator
Jul 02, 2024The Feynman-Kac Operator Expectation Estimator (FKEE) is an innovative method for estimating the target Mathematical Expectation $\mathbb{E}_{X\sim P}[f(X)]$ without relying on a large number of samples, in contrast to the commonly used Markov Chain Monte Carlo (MCMC) Expectation Estimator. FKEE comprises diffusion bridge models and approximation of the Feynman-Kac operator. The key idea is to use the solution to the Feynmann-Kac equation at the initial time $u(x_0,0)=\mathbb{E}[f(X_T)|X_0=x_0]$. We use Physically Informed Neural Networks (PINN) to approximate the Feynman-Kac operator, which enables the incorporation of diffusion bridge models into the expectation estimator and significantly improves the efficiency of using data while substantially reducing the variance. Diffusion Bridge Model is a more general MCMC method. In order to incorporate extensive MCMC algorithms, we propose a new diffusion bridge model based on the Minimum Wasserstein distance. This diffusion bridge model is universal and reduces the training time of the PINN. FKEE also reduces the adverse impact of the curse of dimensionality and weakens the assumptions on the distribution of $X$ and performance function $f$ in the general MCMC expectation estimator. The theoretical properties of this universal diffusion bridge model are also shown. Finally, we demonstrate the advantages and potential applications of this method through various concrete experiments, including the challenging task of approximating the partition function in the random graph model such as the Ising model.
Co-designing a Sub-millisecond Latency Event-based Eye Tracking System with Submanifold Sparse CNN
Apr 22, 2024Eye-tracking technology is integral to numerous consumer electronics applications, particularly in the realm of virtual and augmented reality (VR/AR). These applications demand solutions that excel in three crucial aspects: low-latency, low-power consumption, and precision. Yet, achieving optimal performance across all these fronts presents a formidable challenge, necessitating a balance between sophisticated algorithms and efficient backend hardware implementations. In this study, we tackle this challenge through a synergistic software/hardware co-design of the system with an event camera. Leveraging the inherent sparsity of event-based input data, we integrate a novel sparse FPGA dataflow accelerator customized for submanifold sparse convolution neural networks (SCNN). The SCNN implemented on the accelerator can efficiently extract the embedding feature vector from each representation of event slices by only processing the non-zero activations. Subsequently, these vectors undergo further processing by a gated recurrent unit (GRU) and a fully connected layer on the host CPU to generate the eye centers. Deployment and evaluation of our system reveal outstanding performance metrics. On the Event-based Eye-Tracking-AIS2024 dataset, our system achieves 81% p5 accuracy, 99.5% p10 accuracy, and 3.71 Mean Euclidean Distance with 0.7 ms latency while only consuming 2.29 mJ per inference. Notably, our solution opens up opportunities for future eye-tracking systems. Code is available at https://github.com/CASR-HKU/ESDA/tree/eye_tracking.
Event-Based Eye Tracking. AIS 2024 Challenge Survey
Apr 17, 2024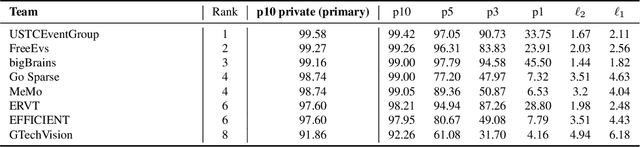
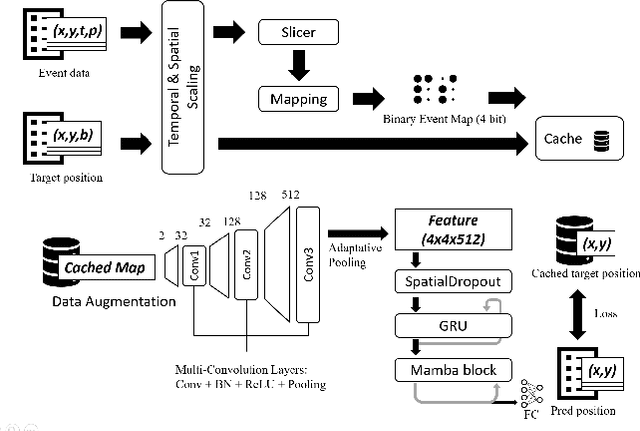
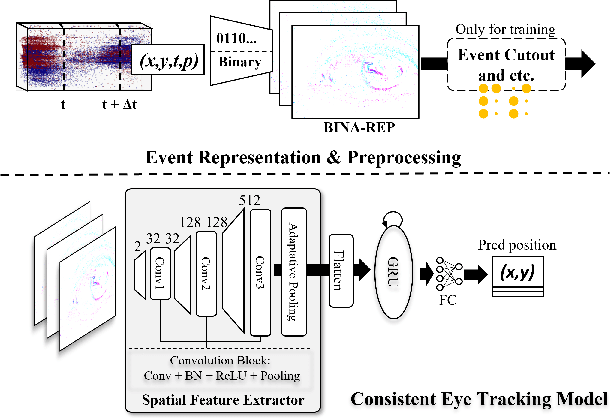

This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye. The challenge emphasizes efficient eye tracking with event cameras to achieve good task accuracy and efficiency trade-off. During the challenge period, 38 participants registered for the Kaggle competition, and 8 teams submitted a challenge factsheet. The novel and diverse methods from the submitted factsheets are reviewed and analyzed in this survey to advance future event-based eye tracking research.