 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to See through Illumination Extremes with Event Streaming in Multimodal Large Language Models
Mar 29, 2026Multimodal Large Language Models (MLLMs) perform strong vision-language reasoning under standard conditions but fail in extreme illumination, where RGB inputs lose irrevocable structure and semantics. We propose Event-MLLM, an event-enhanced model that performs all-light visual reasoning by dynamically fusing event streams with RGB frames. Two key components drive our approach: an Illumination Indicator - a learnable signal derived from a DINOv2 branch that represents exposure degradation and adaptively modulates event-RGB fusion - and an Illumination Correction Loss that aligns fused features with non-degraded (normal-light) semantics in the latent space, compensating for information lost in extreme lighting. We curate the first multi-illumination event-instruction corpus for MLLMs, with 2,241 event-RGB samples (around 6 QA pairs each) across diverse scenes and 17 brightness rates (0.05x - 20x), plus an instruct-following benchmark for reasoning, counting, and fine-grained recognition under extreme lighting. Experiments show that Event-MLLM markedly outperforms general-purpose, illumination-adaptive, and event-only baselines, setting a new state of the art in robust multimodal perception and reasoning under challenging illumination.
Beyond Outliers: A Data-Free Layer-wise Mixed-Precision Quantization Approach Driven by Numerical and Structural Dual-Sensitivity
Mar 18, 2026Layer-wise mixed-precision quantization (LMPQ) enables effective compression under extreme low-bit settings by allocating higher precision to sensitive layers. However, existing methods typically treat all intra-layer weight modules uniformly and rely on a single numerical property when estimating sensitivity, overlooking their distinct operational roles and structural characteristics. To address this, we propose NSDS, a novel calibration-free LMPQ framework driven by Numerical and Structural Dual-Sensitivity. Specifically, it first mechanistically decomposes each layer into distinct operational roles and quantifies their sensitivity from both numerical and structural perspectives. These dual-aspect scores are then aggregated into a unified layer-wise metric through a robust aggregation scheme based on MAD-Sigmoid and Soft-OR to guide bit allocation. Extensive experiments demonstrate that NSDS consistently achieves superior performance compared to various baselines across diverse models and downstream tasks, without relying on any calibration data.
Train Short, Inference Long: Training-free Horizon Extension for Autoregressive Video Generation
Feb 17, 2026Autoregressive video diffusion models have emerged as a scalable paradigm for long video generation. However, they often suffer from severe extrapolation failure, where rapid error accumulation leads to significant temporal degradation when extending beyond training horizons. We identify that this failure primarily stems from the spectral bias of 3D positional embeddings and the lack of dynamic priors in noise sampling. To address these issues, we propose FLEX (Frequency-aware Length EXtension), a training-free inference-time framework that bridges the gap between short-term training and long-term inference. FLEX introduces Frequency-aware RoPE Modulation to adaptively interpolate under-trained low-frequency components while extrapolating high-frequency ones to preserve multi-scale temporal discriminability. This is integrated with Antiphase Noise Sampling (ANS) to inject high-frequency dynamic priors and Inference-only Attention Sink to anchor global structure. Extensive evaluations on VBench demonstrate that FLEX significantly outperforms state-of-the-art models at 6x extrapolation (30s duration) and matches the performance of long-video fine-tuned baselines at 12x scale (60s duration). As a plug-and-play augmentation, FLEX seamlessly integrates into existing inference pipelines for horizon extension. It effectively pushes the generation limits of models such as LongLive, supporting consistent and dynamic video synthesis at a 4-minute scale. Project page is available at https://ga-lee.github.io/FLEX_demo.
Residual Decoding: Mitigating Hallucinations in Large Vision-Language Models via History-Aware Residual Guidance
Feb 01, 2026Large Vision-Language Models (LVLMs) can reason effectively from image-text inputs and perform well in various multimodal tasks. Despite this success, they are affected by language priors and often produce hallucinations. Hallucinations denote generated content that is grammatically and syntactically coherent, yet bears no match or direct relevance to actual visual input. To address this problem, we propose Residual Decoding (ResDec). It is a novel training-free method that uses historical information to aid decoding. The method relies on the internal implicit reasoning mechanism and token logits evolution mechanism of LVLMs to correct biases. Extensive experiments demonstrate that ResDec effectively suppresses hallucinations induced by language priors, significantly improves visual grounding, and reduces object hallucinations. In addition to mitigating hallucinations, ResDec also performs exceptionally well on comprehensive LVLM benchmarks, highlighting its broad applicability.
Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
GuiLoMo: Allocating Expert Number and Rank for LoRA-MoE via Bilevel Optimization with GuidedSelection Vectors
Jun 17, 2025Parameter-efficient fine-tuning (PEFT) methods, particularly Low-Rank Adaptation (LoRA), offer an efficient way to adapt large language models with reduced computational costs. However, their performance is limited by the small number of trainable parameters. Recent work combines LoRA with the Mixture-of-Experts (MoE), i.e., LoRA-MoE, to enhance capacity, but two limitations remain in hindering the full exploitation of its potential: 1) the influence of downstream tasks when assigning expert numbers, and 2) the uniform rank assignment across all LoRA experts, which restricts representational diversity. To mitigate these gaps, we propose GuiLoMo, a fine-grained layer-wise expert numbers and ranks allocation strategy with GuidedSelection Vectors (GSVs). GSVs are learned via a prior bilevel optimization process to capture both model- and task-specific needs, and are then used to allocate optimal expert numbers and ranks. Experiments on three backbone models across diverse benchmarks show that GuiLoMo consistently achieves superior or comparable performance to all baselines. Further analysis offers key insights into how expert numbers and ranks vary across layers and tasks, highlighting the benefits of adaptive expert configuration. Our code is available at https://github.com/Liar406/Gui-LoMo.git.
SeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Jun 10, 2025



We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
SeerAttention: Learning Intrinsic Sparse Attention in Your LLMs
Oct 17, 2024



Attention is the cornerstone of modern Large Language Models (LLMs). Yet its quadratic complexity limits the efficiency and scalability of LLMs, especially for those with a long-context window. A promising approach addressing this limitation is to leverage the sparsity in attention. However, existing sparsity-based solutions predominantly rely on predefined patterns or heuristics to approximate sparsity. This practice falls short to fully capture the dynamic nature of attention sparsity in language-based tasks. This paper argues that attention sparsity should be learned rather than predefined. To this end, we design SeerAttention, a new Attention mechanism that augments the conventional attention with a learnable gate that adaptively selects significant blocks in an attention map and deems the rest blocks sparse. Such block-level sparsity effectively balances accuracy and speedup. To enable efficient learning of the gating network, we develop a customized FlashAttention implementation that extracts the block-level ground truth of attention map with minimum overhead. SeerAttention not only applies to post-training, but also excels in long-context fine-tuning. Our results show that at post-training stages, SeerAttention significantly outperforms state-of-the-art static or heuristic-based sparse attention methods, while also being more versatile and flexible to adapt to varying context lengths and sparsity ratios. When applied to long-context fine-tuning with YaRN, SeerAttention can achieve a remarkable 90% sparsity ratio at a 32k context length with minimal perplexity loss, offering a 5.67x speedup over FlashAttention-2.
Co-designing a Sub-millisecond Latency Event-based Eye Tracking System with Submanifold Sparse CNN
Apr 22, 2024Eye-tracking technology is integral to numerous consumer electronics applications, particularly in the realm of virtual and augmented reality (VR/AR). These applications demand solutions that excel in three crucial aspects: low-latency, low-power consumption, and precision. Yet, achieving optimal performance across all these fronts presents a formidable challenge, necessitating a balance between sophisticated algorithms and efficient backend hardware implementations. In this study, we tackle this challenge through a synergistic software/hardware co-design of the system with an event camera. Leveraging the inherent sparsity of event-based input data, we integrate a novel sparse FPGA dataflow accelerator customized for submanifold sparse convolution neural networks (SCNN). The SCNN implemented on the accelerator can efficiently extract the embedding feature vector from each representation of event slices by only processing the non-zero activations. Subsequently, these vectors undergo further processing by a gated recurrent unit (GRU) and a fully connected layer on the host CPU to generate the eye centers. Deployment and evaluation of our system reveal outstanding performance metrics. On the Event-based Eye-Tracking-AIS2024 dataset, our system achieves 81% p5 accuracy, 99.5% p10 accuracy, and 3.71 Mean Euclidean Distance with 0.7 ms latency while only consuming 2.29 mJ per inference. Notably, our solution opens up opportunities for future eye-tracking systems. Code is available at https://github.com/CASR-HKU/ESDA/tree/eye_tracking.
Event-Based Eye Tracking. AIS 2024 Challenge Survey
Apr 17, 2024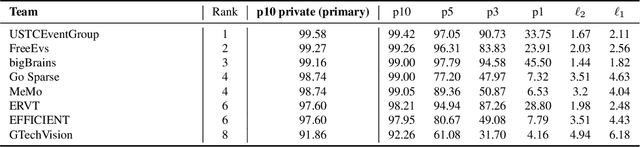
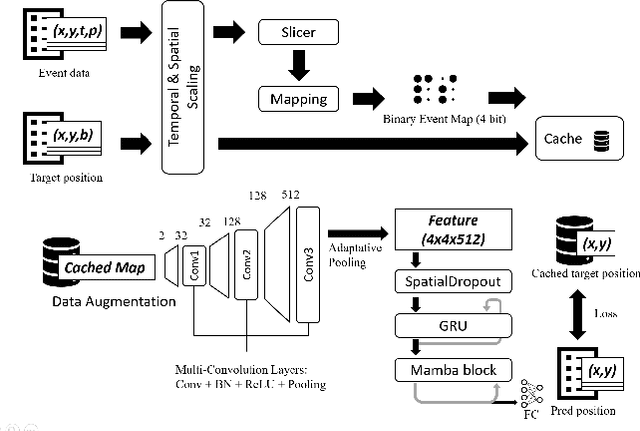
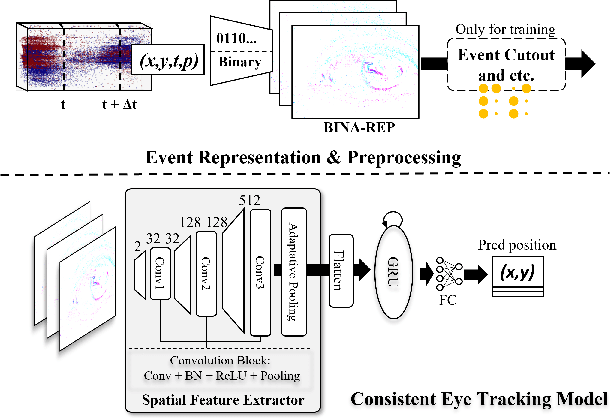

This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye. The challenge emphasizes efficient eye tracking with event cameras to achieve good task accuracy and efficiency trade-off. During the challenge period, 38 participants registered for the Kaggle competition, and 8 teams submitted a challenge factsheet. The novel and diverse methods from the submitted factsheets are reviewed and analyzed in this survey to advance future event-based eye tracking research.