 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal YOCO for Efficient Depth Scaling
Apr 01, 2026The rise of test-time scaling has remarkably boosted the reasoning and agentic proficiency of Large Language Models (LLMs). Yet, standard Transformers struggle to scale inference-time compute efficiently, as conventional looping strategies suffer from high computational overhead and a KV cache that inflates alongside model depth. We present Universal YOCO (YOCO-U), which combines the YOCO decoder-decoder architecture with recursive computation to achieve a synergistic effect greater than either alone. Built on the YOCO framework, YOCO-U implements a Universal Self-Decoder that performs multiple iterations via parameter sharing, while confining the iterative process to shallow, efficient-attention layers. This combination yields a favorable capability-efficiency tradeoff that neither YOCO nor recursion achieves independently. The YOCO architecture provides a constant global KV cache and linear pre-filling, while partial recursion enhances representational depth with limited overhead. Together, YOCO-U improves token utility and scaling behavior while maintaining efficient inference. Empirical results confirm that YOCO-U remains highly competitive in general and long-context benchmarks, demonstrating that the integration of efficient-attention architectures and recursive computation is a promising direction for scalable LLMs.
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Mar 26, 2026Equipping Large Language Model (LLM) agents with domain-specific skills is critical for tackling complex tasks. Yet, manual authoring creates a severe scalability bottleneck. Conversely, automated skill generation often yields fragile or fragmented results because it either relies on shallow parametric knowledge or sequentially overfits to non-generalizable trajectory-local lessons. To overcome this, we introduce Trace2Skill, a framework that mirrors how human experts author skills: by holistically analyzing broad execution experience before distilling it into a single, comprehensive guide. Instead of reacting sequentially to individual trajectories, Trace2Skill dispatches a parallel fleet of sub-agents to analyze a diverse pool of executions. It extracts trajectory-specific lessons and hierarchically consolidates them into a unified, conflict-free skill directory via inductive reasoning. Trace2Skill supports both deepening existing human-written skills and creating new ones from scratch. Experiments in challenging domains, such as spreadsheet, VisionQA and math reasoning, show that Trace2Skill significantly improves upon strong baselines, including Anthropic's official xlsx skills. Crucially, this trajectory-grounded evolution does not merely memorize task instances or model-specific quirks: evolved skills transfer across LLM scales and generalize to OOD settings. For example, skills evolved by Qwen3.5-35B on its own trajectories improved a Qwen3.5-122B agent by up to 57.65 absolute percentage points on WikiTableQuestions. Ultimately, our results demonstrate that complex agent experience can be packaged into highly transferable, declarative skills -- requiring no parameter updates, no external retrieval modules, and utilizing open-source models as small as 35B parameters.
Geometric Autoencoder for Diffusion Models
Mar 12, 2026Latent diffusion models have established a new state-of-the-art in high-resolution visual generation. Integrating Vision Foundation Model priors improves generative efficiency, yet existing latent designs remain largely heuristic. These approaches often struggle to unify semantic discriminability, reconstruction fidelity, and latent compactness. In this paper, we propose Geometric Autoencoder (GAE), a principled framework that systematically addresses these challenges. By analyzing various alignment paradigms, GAE constructs an optimized low-dimensional semantic supervision target from VFMs to provide guidance for the autoencoder. Furthermore, we leverage latent normalization that replaces the restrictive KL-divergence of standard VAEs, enabling a more stable latent manifold specifically optimized for diffusion learning. To ensure robust reconstruction under high-intensity noise, GAE incorporates a dynamic noise sampling mechanism. Empirically, GAE achieves compelling performance on the ImageNet-1K $256 \times 256$ benchmark, reaching a gFID of 1.82 at only 80 epochs and 1.31 at 800 epochs without Classifier-Free Guidance, significantly surpassing existing state-of-the-art methods. Beyond generative quality, GAE establishes a superior equilibrium between compression, semantic depth and robust reconstruction stability. These results validate our design considerations, offering a promising paradigm for latent diffusion modeling. Code and models are publicly available at https://github.com/sii-research/GAE.
VIBEVOICE-ASR Technical Report
Jan 26, 2026This report presents VibeVoice-ASR, a general-purpose speech understanding framework built upon VibeVoice, designed to address the persistent challenges of context fragmentation and multi-speaker complexity in long-form audio (e.g., meetings, podcasts) that remain despite recent advancements in short-form speech recognition. Unlike traditional pipelined approaches that rely on audio chunking, VibeVoice-ASRsupports single-pass processing for up to 60 minutes of audio. It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task. In addition, VibeVoice-ASR supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Furthermore, we introduce a prompt-based context injection mechanism that allows users to supply customized conetxt, significantly improving accuracy on domain-specific terminology and polyphonic character disambiguation.
VibeVoice Technical Report
Aug 26, 2025This report presents VibeVoice, a novel model designed to synthesize long-form speech with multiple speakers by employing next-token diffusion, which is a unified method for modeling continuous data by autoregressively generating latent vectors via diffusion. To enable this, we introduce a novel continuous speech tokenizer that, when compared to the popular Encodec model, improves data compression by 80 times while maintaining comparable performance. The tokenizer effectively preserves audio fidelity while significantly boosting computational efficiency for processing long sequences. Thus, VibeVoice can synthesize long-form speech for up to 90 minutes (in a 64K context window length) with a maximum of 4 speakers, capturing the authentic conversational ``vibe'' and surpassing open-source and proprietary dialogue models.
SeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Jun 10, 2025



We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
Reinforcement Pre-Training
Jun 09, 2025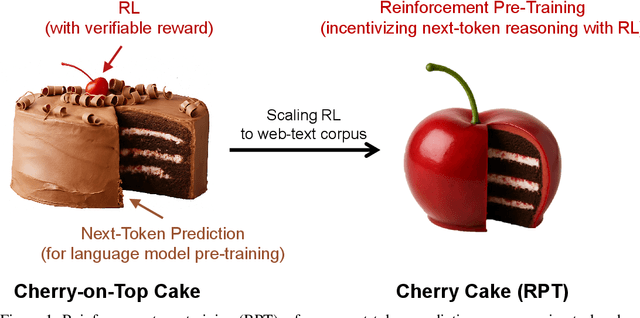
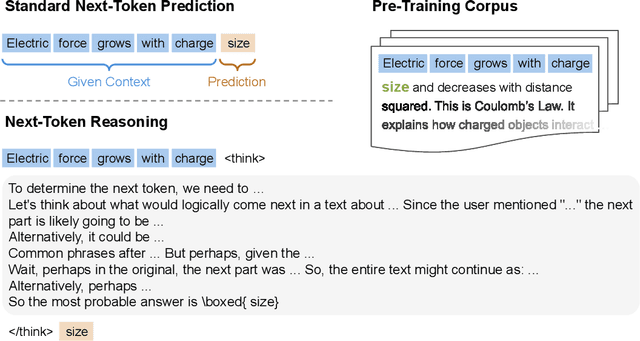

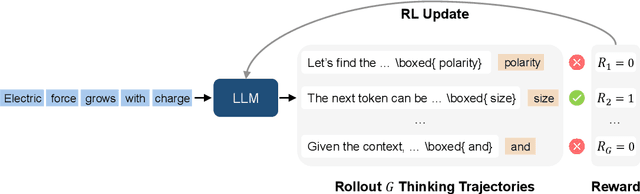
In this work, we introduce Reinforcement Pre-Training (RPT) as a new scaling paradigm for large language models and reinforcement learning (RL). Specifically, we reframe next-token prediction as a reasoning task trained using RL, where it receives verifiable rewards for correctly predicting the next token for a given context. RPT offers a scalable method to leverage vast amounts of text data for general-purpose RL, rather than relying on domain-specific annotated answers. By incentivizing the capability of next-token reasoning, RPT significantly improves the language modeling accuracy of predicting the next tokens. Moreover, RPT provides a strong pre-trained foundation for further reinforcement fine-tuning. The scaling curves show that increased training compute consistently improves the next-token prediction accuracy. The results position RPT as an effective and promising scaling paradigm to advance language model pre-training.
Rectified Sparse Attention
Jun 05, 2025Efficient long-sequence generation is a critical challenge for Large Language Models. While recent sparse decoding methods improve efficiency, they suffer from KV cache misalignment, where approximation errors accumulate and degrade generation quality. In this work, we propose Rectified Sparse Attention (ReSA), a simple yet effective method that combines block-sparse attention with periodic dense rectification. By refreshing the KV cache at fixed intervals using a dense forward pass, ReSA bounds error accumulation and preserves alignment with the pretraining distribution. Experiments across math reasoning, language modeling, and retrieval tasks demonstrate that ReSA achieves near-lossless generation quality with significantly improved efficiency. Notably, ReSA delivers up to 2.42$\times$ end-to-end speedup under decoding at 256K sequence length, making it a practical solution for scalable long-context inference. Code is available at https://aka.ms/ReSA-LM.
The Self-Improvement Paradox: Can Language Models Bootstrap Reasoning Capabilities without External Scaffolding?
Feb 19, 2025
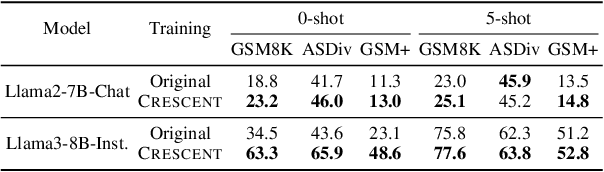
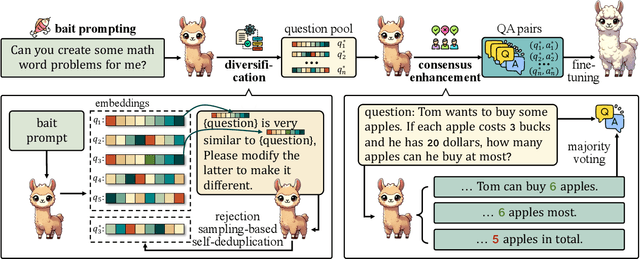
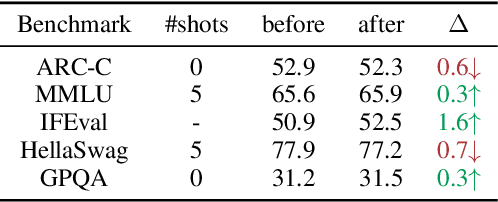
Self-improving large language models (LLMs) -- i.e., to improve the performance of an LLM by fine-tuning it with synthetic data generated by itself -- is a promising way to advance the capabilities of LLMs while avoiding extensive supervision. Existing approaches to self-improvement often rely on external supervision signals in the form of seed data and/or assistance from third-party models. This paper presents Crescent -- a simple yet effective framework for generating high-quality synthetic question-answer data in a fully autonomous manner. Crescent first elicits the LLM to generate raw questions via a bait prompt, then diversifies these questions leveraging a rejection sampling-based self-deduplication, and finally feeds the questions to the LLM and collects the corresponding answers by means of majority voting. We show that Crescent sheds light on the potential of true self-improvement with zero external supervision signals for math reasoning; in particular, Crescent-generated question-answer pairs suffice to (i) improve the reasoning capabilities of an LLM while preserving its general performance (especially in the 0-shot setting); and (ii) distil LLM knowledge to weaker models more effectively than existing methods based on seed-dataset augmentation.
Multimodal Latent Language Modeling with Next-Token Diffusion
Dec 11, 2024



Multimodal generative models require a unified approach to handle both discrete data (e.g., text and code) and continuous data (e.g., image, audio, video). In this work, we propose Latent Language Modeling (LatentLM), which seamlessly integrates continuous and discrete data using causal Transformers. Specifically, we employ a variational autoencoder (VAE) to represent continuous data as latent vectors and introduce next-token diffusion for autoregressive generation of these vectors. Additionally, we develop $\sigma$-VAE to address the challenges of variance collapse, which is crucial for autoregressive modeling. Extensive experiments demonstrate the effectiveness of LatentLM across various modalities. In image generation, LatentLM surpasses Diffusion Transformers in both performance and scalability. When integrated into multimodal large language models, LatentLM provides a general-purpose interface that unifies multimodal generation and understanding. Experimental results show that LatentLM achieves favorable performance compared to Transfusion and vector quantized models in the setting of scaling up training tokens. In text-to-speech synthesis, LatentLM outperforms the state-of-the-art VALL-E 2 model in speaker similarity and robustness, while requiring 10x fewer decoding steps. The results establish LatentLM as a highly effective and scalable approach to advance large multimodal models.