 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVGBench: Implicit-to-Explicit Visual Grounding Benchmark in UAV Imagery with Large Vision-Language Models
Jan 02, 2026Remote sensing (RS) large vision-language models (LVLMs) have shown strong promise across visual grounding (VG) tasks. However, existing RS VG datasets predominantly rely on explicit referring expressions-such as relative position, relative size, and color cues-thereby constraining performance on implicit VG tasks that require scenario-specific domain knowledge. This article introduces DVGBench, a high-quality implicit VG benchmark for drones, covering six major application scenarios: traffic, disaster, security, sport, social activity, and productive activity. Each object provides both explicit and implicit queries. Based on the dataset, we design DroneVG-R1, an LVLM that integrates the novel Implicit-to-Explicit Chain-of-Thought (I2E-CoT) within a reinforcement learning paradigm. This enables the model to take advantage of scene-specific expertise, converting implicit references into explicit ones and thus reducing grounding difficulty. Finally, an evaluation of mainstream models on both explicit and implicit VG tasks reveals substantial limitations in their reasoning capabilities. These findings provide actionable insights for advancing the reasoning capacity of LVLMs for drone-based agents. The code and datasets will be released at https://github.com/zytx121/DVGBench
Geo-R1: Improving Few-Shot Geospatial Referring Expression Understanding with Reinforcement Fine-Tuning
Sep 26, 2025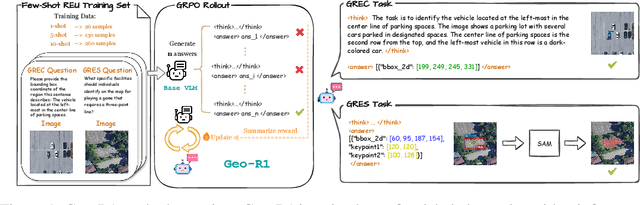


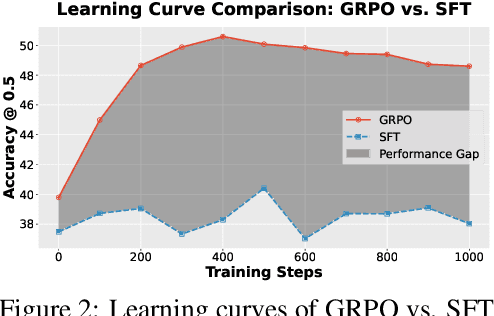
Referring expression understanding in remote sensing poses unique challenges, as it requires reasoning over complex object-context relationships. While supervised fine-tuning (SFT) on multimodal large language models achieves strong performance with massive labeled datasets, they struggle in data-scarce scenarios, leading to poor generalization. To address this limitation, we propose Geo-R1, a reasoning-centric reinforcement fine-tuning (RFT) paradigm for few-shot geospatial referring. Geo-R1 enforces the model to first generate explicit, interpretable reasoning chains that decompose referring expressions, and then leverage these rationales to localize target objects. This "reason first, then act" process enables the model to make more effective use of limited annotations, enhances generalization, and provides interpretability. We validate Geo-R1 on three carefully designed few-shot geospatial referring benchmarks, where our model consistently and substantially outperforms SFT baselines. It also demonstrates strong cross-dataset generalization, highlighting its robustness. Code and data will be released at http://geo-r1.github.io.
SRMF: A Data Augmentation and Multimodal Fusion Approach for Long-Tail UHR Satellite Image Segmentation
Apr 28, 2025The long-tail problem presents a significant challenge to the advancement of semantic segmentation in ultra-high-resolution (UHR) satellite imagery. While previous efforts in UHR semantic segmentation have largely focused on multi-branch network architectures that emphasize multi-scale feature extraction and fusion, they have often overlooked the importance of addressing the long-tail issue. In contrast to prior UHR methods that focused on independent feature extraction, we emphasize data augmentation and multimodal feature fusion to alleviate the long-tail problem. In this paper, we introduce SRMF, a novel framework for semantic segmentation in UHR satellite imagery. Our approach addresses the long-tail class distribution by incorporating a multi-scale cropping technique alongside a data augmentation strategy based on semantic reordering and resampling. To further enhance model performance, we propose a multimodal fusion-based general representation knowledge injection method, which, for the first time, fuses text and visual features without the need for individual region text descriptions, extracting more robust features. Extensive experiments on the URUR, GID, and FBP datasets demonstrate that our method improves mIoU by 3.33\%, 0.66\%, and 0.98\%, respectively, achieving state-of-the-art performance. Code is available at: https://github.com/BinSpa/SRMF.git.
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Apr 10, 2025
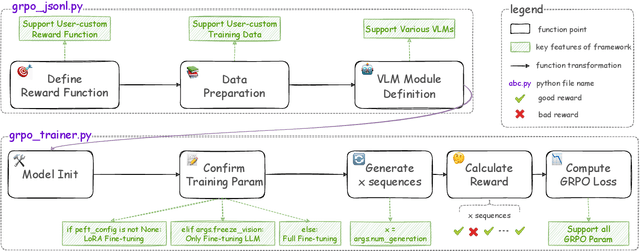
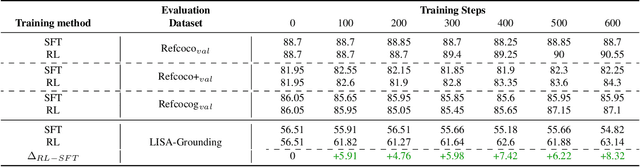
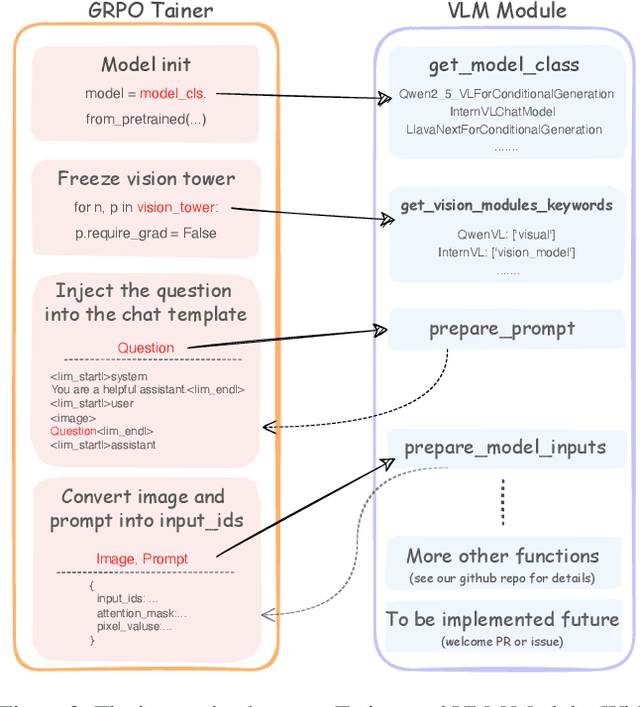
Recently DeepSeek R1 has shown that reinforcement learning (RL) can substantially improve the reasoning capabilities of Large Language Models (LLMs) through a simple yet effective design. The core of R1 lies in its rule-based reward formulation, which leverages tasks with deterministic ground-truth answers to enable precise and stable reward computation. In the visual domain, we similarly observe that a wide range of visual understanding tasks are inherently equipped with well-defined ground-truth annotations. This property makes them naturally compatible with rule-based reward mechanisms. Motivated by this observation, we investigate the extension of R1-style reinforcement learning to Vision-Language Models (VLMs), aiming to enhance their visual reasoning capabilities. To this end, we develop VLM-R1, a dedicated framework designed to harness RL for improving VLMs' performance on general vision-language tasks. Using this framework, we further explore the feasibility of applying RL to visual domain. Experimental results indicate that the RL-based model not only delivers competitive performance on visual understanding tasks but also surpasses Supervised Fine-Tuning (SFT) in generalization ability. Furthermore, we conduct comprehensive ablation studies that uncover a series of noteworthy insights, including the presence of reward hacking in object detection, the emergence of the "OD aha moment", the impact of training data quality, and the scaling behavior of RL across different model sizes. Through these analyses, we aim to deepen the understanding of how reinforcement learning enhances the capabilities of vision-language models, and we hope our findings and open-source contributions will support continued progress in the vision-language RL community. Our code and model are available at https://github.com/om-ai-lab/VLM-R1
GeoRSMLLM: A Multimodal Large Language Model for Vision-Language Tasks in Geoscience and Remote Sensing
Mar 16, 2025The application of Vision-Language Models (VLMs) in remote sensing (RS) has demonstrated significant potential in traditional tasks such as scene classification, object detection, and image captioning. However, current models, which excel in Referring Expression Comprehension (REC), struggle with tasks involving complex instructions (e.g., exists multiple conditions) or pixel-level operations like segmentation and change detection. In this white paper, we provide a comprehensive hierarchical summary of vision-language tasks in RS, categorized by the varying levels of cognitive capability required. We introduce the Remote Sensing Vision-Language Task Set (RSVLTS), which includes Open-Vocabulary Tasks (OVT), Referring Expression Tasks (RET), and Described Object Tasks (DOT) with increased difficulty, and Visual Question Answering (VQA) aloneside. Moreover, we propose a novel unified data representation using a set-of-points approach for RSVLTS, along with a condition parser and a self-augmentation strategy based on cyclic referring. These features are integrated into the GeoRSMLLM model, and this enhanced model is designed to handle a broad range of tasks of RSVLTS, paving the way for a more generalized solution for vision-language tasks in geoscience and remote sensing.
The Self-Improvement Paradox: Can Language Models Bootstrap Reasoning Capabilities without External Scaffolding?
Feb 19, 2025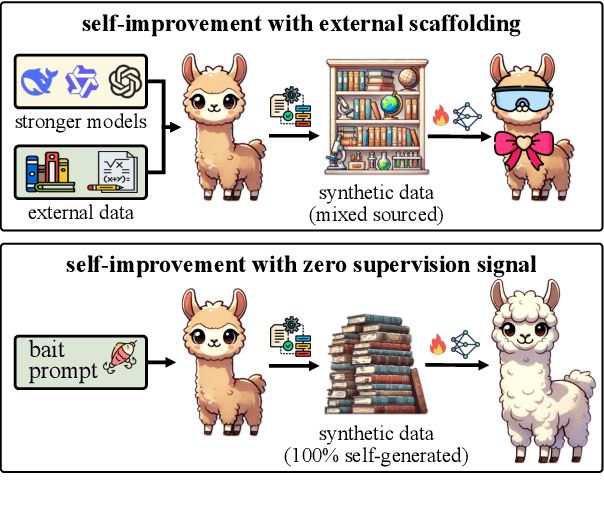
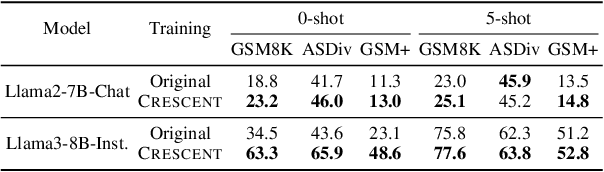
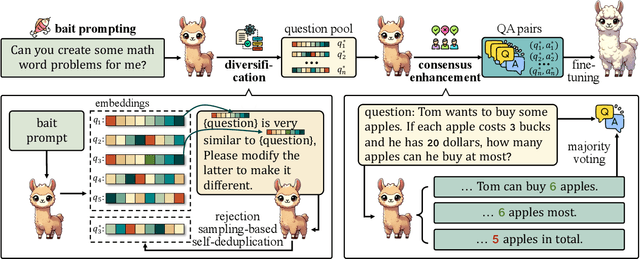
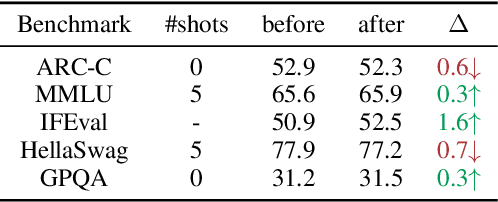
Self-improving large language models (LLMs) -- i.e., to improve the performance of an LLM by fine-tuning it with synthetic data generated by itself -- is a promising way to advance the capabilities of LLMs while avoiding extensive supervision. Existing approaches to self-improvement often rely on external supervision signals in the form of seed data and/or assistance from third-party models. This paper presents Crescent -- a simple yet effective framework for generating high-quality synthetic question-answer data in a fully autonomous manner. Crescent first elicits the LLM to generate raw questions via a bait prompt, then diversifies these questions leveraging a rejection sampling-based self-deduplication, and finally feeds the questions to the LLM and collects the corresponding answers by means of majority voting. We show that Crescent sheds light on the potential of true self-improvement with zero external supervision signals for math reasoning; in particular, Crescent-generated question-answer pairs suffice to (i) improve the reasoning capabilities of an LLM while preserving its general performance (especially in the 0-shot setting); and (ii) distil LLM knowledge to weaker models more effectively than existing methods based on seed-dataset augmentation.
ZoomEye: Enhancing Multimodal LLMs with Human-Like Zooming Capabilities through Tree-Based Image Exploration
Nov 25, 2024

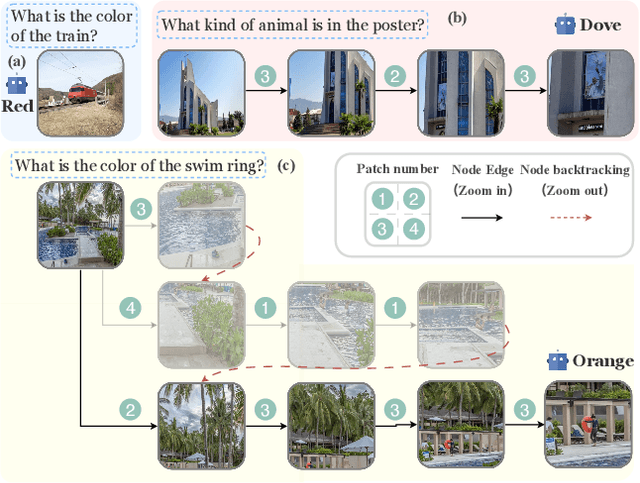
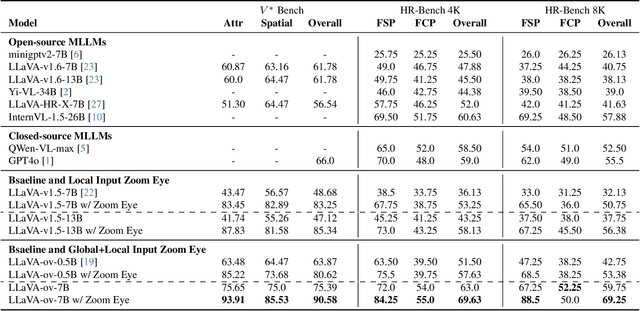
An image, especially with high-resolution, typically consists of numerous visual elements, ranging from dominant large objects to fine-grained detailed objects. When perceiving such images, multimodal large language models~(MLLMs) face limitations due to the restricted input resolution of the pretrained vision encoder and the cluttered, dense context of the image, resulting in a focus on primary objects while easily overlooking detailed ones. In this paper, we propose Zoom Eye, a tree search algorithm designed to navigate the hierarchical and visual nature of images to capture relevant information. Zoom Eye conceptualizes an image as a tree, with each children node representing a zoomed sub-patch of the parent node and the root represents the overall image. Moreover, Zoom Eye is model-agnostic and training-free, so it enables any MLLMs to simulate human zooming actions by searching along the image tree from root to leaf nodes, seeking out pertinent information, and accurately responding to related queries. We experiment on a series of elaborate high-resolution benchmarks and the results demonstrate that Zoom Eye not only consistently improves the performance of a series base MLLMs with large margin~(e.g., LLaVA-v1.5-7B increases by 34.57\% on $V^*$ Bench and 17.88\% on HR-Bench), but also enables small 7B MLLMs to outperform strong large models such as GPT-4o. Our code is available at \href{https://github.com/om-ai-lab/ZoomEye}{https://github.com/om-ai-lab/ZoomEye}.
Enhancing Ultra High Resolution Remote Sensing Imagery Analysis with ImageRAG
Nov 12, 2024


Ultra High Resolution (UHR) remote sensing imagery (RSI) (e.g. 100,000 $\times$ 100,000 pixels or more) poses a significant challenge for current Remote Sensing Multimodal Large Language Models (RSMLLMs). If choose to resize the UHR image to standard input image size, the extensive spatial and contextual information that UHR images contain will be neglected. Otherwise, the original size of these images often exceeds the token limits of standard RSMLLMs, making it difficult to process the entire image and capture long-range dependencies to answer the query based on the abundant visual context. In this paper, we introduce ImageRAG for RS, a training-free framework to address the complexities of analyzing UHR remote sensing imagery. By transforming UHR remote sensing image analysis task to image's long context selection task, we design an innovative image contextual retrieval mechanism based on the Retrieval-Augmented Generation (RAG) technique, denoted as ImageRAG. ImageRAG's core innovation lies in its ability to selectively retrieve and focus on the most relevant portions of the UHR image as visual contexts that pertain to a given query. Fast path and slow path are proposed in this framework to handle this task efficiently and effectively. ImageRAG allows RSMLLMs to manage extensive context and spatial information from UHR RSI, ensuring the analysis is both accurate and efficient.
Preserving Knowledge in Large Language Model: A Model-Agnostic Self-Decompression Approach
Jun 17, 2024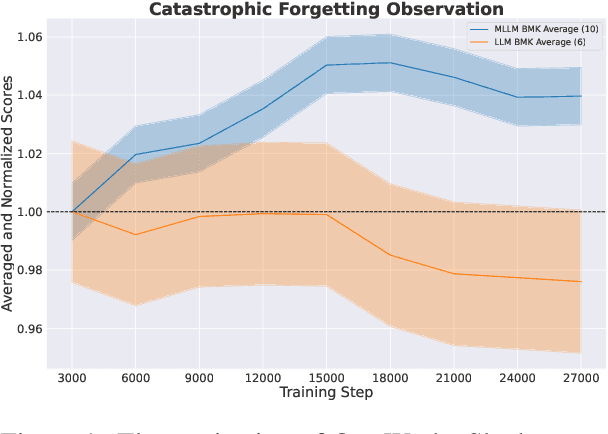
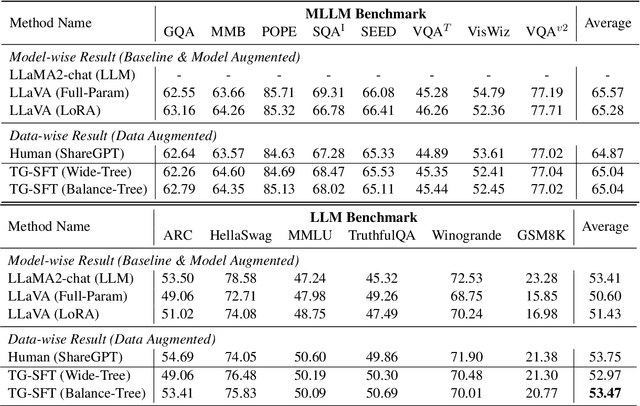
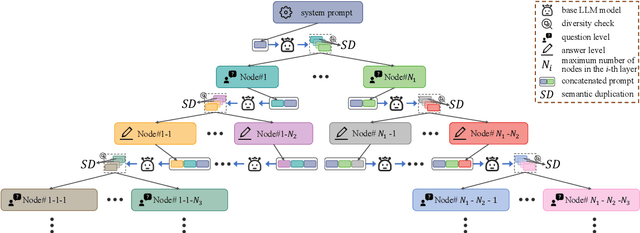

Humans can retain old knowledge while learning new information, but Large Language Models (LLMs) often suffer from catastrophic forgetting when post-pretrained or supervised fine-tuned (SFT) on domain-specific data. Moreover, for Multimodal Large Language Models (MLLMs) which are composed of the LLM base and visual projector (e.g. LLaVA), a significant decline in performance on language benchmarks was observed compared to their single-modality counterparts. To address these challenges, we introduce a novel model-agnostic self-decompression method, Tree Generation (TG), that decompresses knowledge within LLMs into the training corpus. This paper focuses on TG-SFT, which can synthetically generate SFT data for the instruction tuning steps. By incorporating the dumped corpus during SFT for MLLMs, we significantly reduce the forgetting problem.
RS5M: A Large Scale Vision-Language Dataset for Remote Sensing Vision-Language Foundation Model
Jun 20, 2023Pre-trained Vision-Language Foundation Models utilizing extensive image-text paired data have demonstrated unprecedented image-text association capabilities, achieving remarkable results across various downstream tasks. A critical challenge is how to make use of existing large-scale pre-trained VLMs, which are trained on common objects, to perform the domain-specific transfer for accomplishing domain-related downstream tasks. In this paper, we propose a new framework that includes the Domain Foundation Model (DFM), bridging the gap between the General Foundation Model (GFM) and domain-specific downstream tasks. Moreover, we present an image-text paired dataset in the field of remote sensing (RS), RS5M, which has 5 million RS images with English descriptions. The dataset is obtained from filtering publicly available image-text paired datasets and captioning label-only RS datasets with pre-trained VLM. These constitute the first large-scale RS image-text paired dataset. Additionally, we tried several Parameter-Efficient Fine-Tuning methods on RS5M to implement the DFM. Experimental results show that our proposed dataset are highly effective for various tasks, improving upon the baseline by $8 \% \sim 16 \%$ in zero-shot classification tasks, and obtaining good results in both Vision-Language Retrieval and Semantic Localization tasks. Finally, we show successful results of training the RS Stable Diffusion model using the RS5M, uncovering more use cases of the dataset.