 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
XNN: Paradigm Shift in Mitigating Identity Leakage within Cloud-Enabled Deep Learning
Aug 09, 2024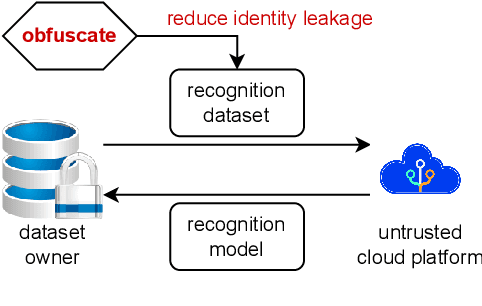
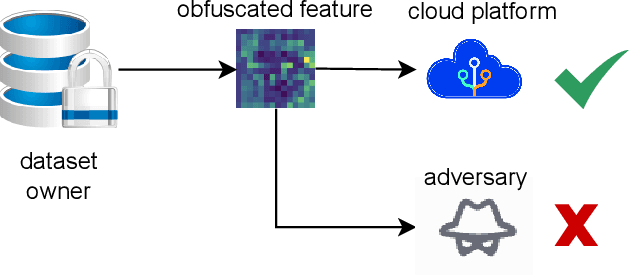
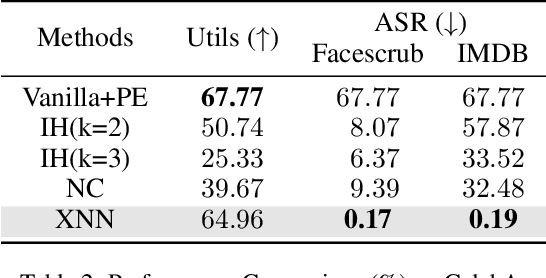
In the domain of cloud-based deep learning, the imperative for external computational resources coexists with acute privacy concerns, particularly identity leakage. To address this challenge, we introduce XNN and XNN-d, pioneering methodologies that infuse neural network features with randomized perturbations, striking a harmonious balance between utility and privacy. XNN, designed for the training phase, ingeniously blends random permutation with matrix multiplication techniques to obfuscate feature maps, effectively shielding private data from potential breaches without compromising training integrity. Concurrently, XNN-d, devised for the inference phase, employs adversarial training to integrate generative adversarial noise. This technique effectively counters black-box access attacks aimed at identity extraction, while a distilled face recognition network adeptly processes the perturbed features, ensuring accurate identification. Our evaluation demonstrates XNN's effectiveness, significantly outperforming existing methods in reducing identity leakage while maintaining a high model accuracy.
Mask-ControlNet: Higher-Quality Image Generation with An Additional Mask Prompt
Apr 08, 2024Text-to-image generation has witnessed great progress, especially with the recent advancements in diffusion models. Since texts cannot provide detailed conditions like object appearance, reference images are usually leveraged for the control of objects in the generated images. However, existing methods still suffer limited accuracy when the relationship between the foreground and background is complicated. To address this issue, we develop a framework termed Mask-ControlNet by introducing an additional mask prompt. Specifically, we first employ large vision models to obtain masks to segment the objects of interest in the reference image. Then, the object images are employed as additional prompts to facilitate the diffusion model to better understand the relationship between foreground and background regions during image generation. Experiments show that the mask prompts enhance the controllability of the diffusion model to maintain higher fidelity to the reference image while achieving better image quality. Comparison with previous text-to-image generation methods demonstrates our method's superior quantitative and qualitative performance on the benchmark datasets.
Injecting Image Details into CLIP's Feature Space
Aug 31, 2022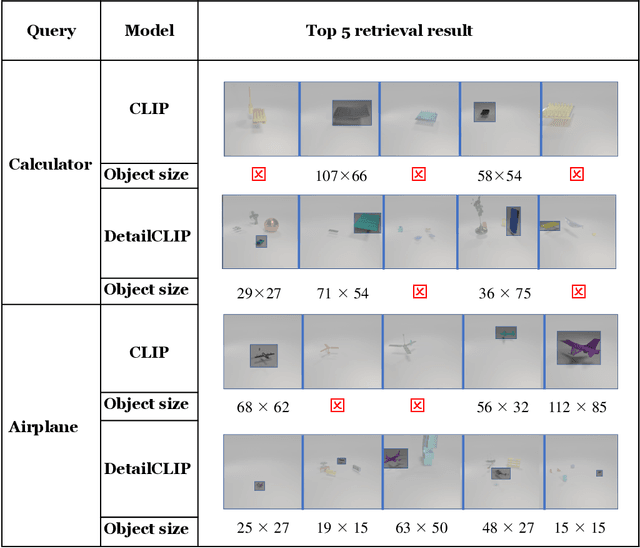
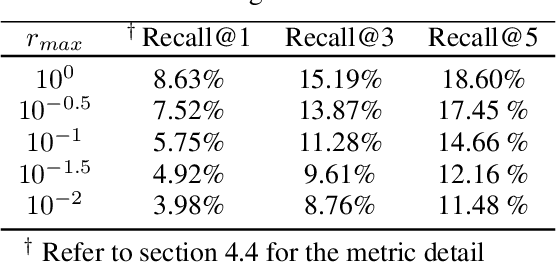

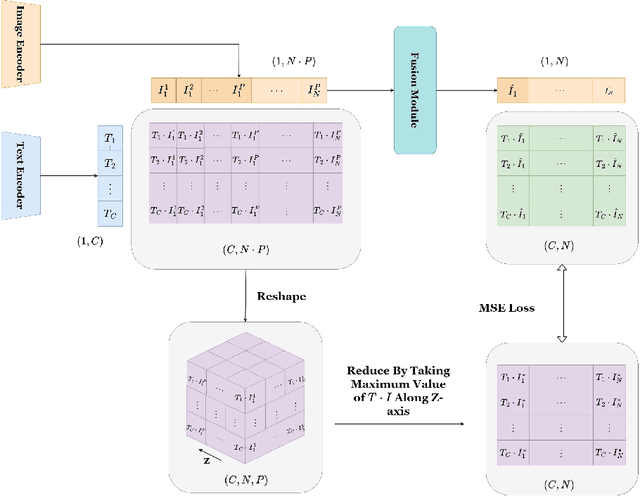
Although CLIP-like Visual Language Models provide a functional joint feature space for image and text, due to the limitation of the CILP-like model's image input size (e.g., 224), subtle details are lost in the feature representation if we input high-resolution images (e.g., 2240). In this work, we introduce an efficient framework that can produce a single feature representation for a high-resolution image that injects image details and shares the same semantic space as the original CLIP. In the framework, we train a feature fusing model based on CLIP features extracted from a carefully designed image patch method that can cover objects of any scale, weakly supervised by image-agnostic class prompted queries. We validate our framework by retrieving images from class prompted queries on the real world and synthetic datasets, showing significant performance improvement on these tasks. Furthermore, to fully demonstrate our framework's detail retrieval ability, we construct a CLEVR-like synthetic dataset called CLVER-DS, which is fully annotated and has a controllable object scale.